ALBERT : A Lite BERT 리뷰
ALBERT : A Lite BERT
1. Introduction
Full-Network Pretraining 가 Language Representation Model (언어를 표현할 수 있는 모델)
충분한 학습 데이터를 가지지 않은 Non-Trivial Task ( 사소하지 않은 태스크 )의 돌파구가 되었다.
ALBERT가 RACE 데이터 셋에서 89.4%로 SOTA
거대한 모델을 사전 학습하고, 작은 모델을 추출해서 실제 문제 해결에 사용하는 것이 일반화가 되었다.
→ 모델의 크기가 과연 중요한가? 클 수록 더 좋은 NLP 모델 일까?
모델을 크기가 커질 수록 생기는 가용할 수 있는 하드웨어와 학습 속도 등의 문제가 있다.
-
파라미터 수로 인한 메모리 한계 → 분산 학습 → 파라미터 커뮤니케이션 오버헤드
→ 모델 병렬화 + 메모리 관리 개선으로 메모리 문제는 어느정도 해소 할 수는 있지만…
-
파라미터 커뮤니케이션 오버헤드는?
결국 파라미터수를 줄일 수 밖에 없다. 파라미터 수를 줄인 가벼운 BERT.
Bert-Large 버전에 비해 18배 작은 파라미터 수, 1.7배 빠른 학습 시간
-
조건
-
vocab 임베딩 파라미터 수를 많이 늘리지 않으면서 hidden size를 늘려야 한다.
-
모델 성능을 최대한 유지하면서 파라미터 수를 줄여야 한다.
-
Factorized Embedding Parameterization, Cross-Layer Parameter Sharing
오버피팅을 방지하는 기술인 Regularization 작용을 해서 Generalization
기존 BERT의 Loss인 NSP의 비효율을 해결한 Self-Supervised Loss인 SOP를 소개
GLUE, SQuAD, RACE에서 새롭게 SOTA를 갱신했다.
2. RELATED WORK
2.1 SCALING UP REPRESENTATION LEARNING FOR NATURAL LANGUAGE
1
모델의 크기가 클수록 ~ 더 많은 히든 사이즈, 히든 레이어, 어텐션 헤드를 추가해 성능이 향상 되는 것으로 나타났다. 그렇지만 그만큼 연산에 필요한 비용이 늘어나 한계에 봉착했다. 그래서
-
BackPropagation에서의 메모리 효율을 최적화
Chen et al 2016, Gomez et al 2017
-
거대한 모델을 학습하기 위한 모델 병렬화
Raffel et al 2019
2.2 CROSS-LAYER PARAMETER SHARING
-
Attention is All you Need
사전 학습과 파인 튜닝 환경을 고려하지 않은 정통 인-디코더의 파라미터 공유
-
Universal Transformer ( UT )
CNN/RNN에서 사용되는 weight sharing을 도입
-
Deep Equilibrium Model ( DQM )
특정 레이어의 입력 임베딩과 출력 임베딩 동일하게 사용
-
Modeling Recurrence for Transformer
파라미터 수가 오히려 더 늘었다.
ALBERT의 임베딩은 수렴하기 보다는 진동한다.
2.3 SENTENCE ORDERING OBJECTIVES
-
StructBERT
세(앞+뒤+아님) 방향으로 두 개의 연속된 텍스트 세그먼트의 순서를 예측하려고 했다.
ALBERT는 두 방향으로 SOP 문제를 제시한다.
Coherence 와 Cohesion
Coherence - 문장을 의미적으로 연결, 여러 문장이 동일한 주제로 꿰어지는 힘
Cohesion - 텍스트에서 일관되게 찾아낸 총체적 의미의 상, 형식적인 결속성, 이웃 하는 문장과 관련성이 있는 의미이다.
3 THE ELEMENTS OF ALBERT
3.1 MODEL ARCHITECTURE CHOICES
트랜스포머의 Encoder와 GELU를 사용한다.
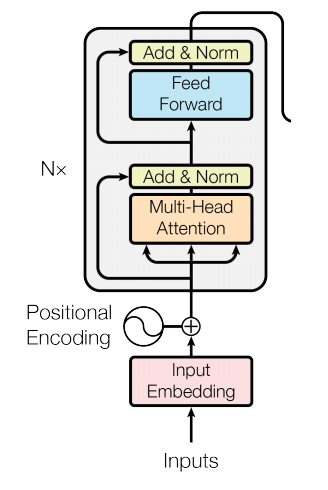
2
3
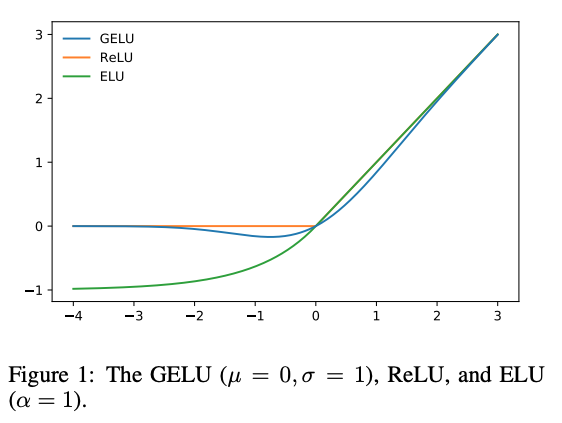
Gaussian Error Linear Unit (GELU) : 다른 알고리즘 들 보다 더 빠르게 수렴한다. ReLU는 0이상의 값을 그대로 가져가는 역할. GELU는 ReLU에서 정규 분포를 따르는 베르누이 분포를 곱해서 사용한다.
Factorized embedding parameterization
Bert, XLNet, RoBERTa, WordPiece embedding 사이즈 E를 히든 레이어 크기 H와 같이 가져갔다.
모델링 관점에서
- 워드 피스 임베딩은 워드 표현을 문맥과 독립적으로 학습하는 것
- 버트의 임베딩은 문맥 의존적인 표현을 사용한다. 따라서 E가 H 보다 작아도 괜찮다.
실제에서는 vocab의 크기를 크게 가져가야한다.
- E와 H의 크기를 같이 가져간다면, H가 커지면 E도 같이 커지는 것이므로 모델의 파라미터 크기가 너무 커지게 된다.
- 파라미터 수를 줄이기 위해서는 E가 H 보다 작아야 의미가 있다. ( H » E)
- E 보다 H가 작아지면 Hidden Layer의 Input 크기 H와 맞지 않아서 한 매트릭스를 추가로 둔다.
ALBERT에서는 임베딩 파라미터를 두개의 작은 매트릭스로 분해해서 H로 바로 매핑하는 것이 아니라 나눠서 계산하게 된다.
4
( V, H ) → ( V, E ) X ( E, H ) = ( V X H ) // (1000, 1024 ) → ( 1000, 128 ) X ( 128, 1024 ) , x3.95배 파라미터 절약
( 1000, 1024 ) → ( 1000, 128 ) (128, 1024 ) → (1000, 1024 )
Cross-layer parameter sharing
다양한 파라미터 공유 방법이 있지만 ( FFN, Attention ), ALBERT의 기본 접근법은 모든 파라미터의 공유
이전의 UT, DQE가 기존 트랜스포머에 비해 좋은 성능을 보였었다.
5
6
Layer의 Output 이 다시 Layer의 Input으로 들어가는 형태
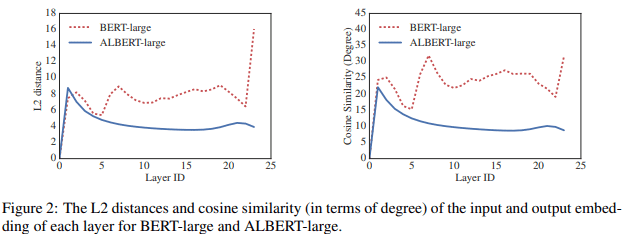
7
뭔가 ALBERT가 BERT에 비해서 부드러워 보이는데, 네트워크 파라미터의 안정화에 영향을 준다는 것을 의미
Inter-sentence coherence loss
BERT는 MLM(Masked Language Model) Loss 외에도 NSP(Next-Sentence Prediction) Loss를 사용한다.

8
- MLM : [MASK] 토큰이 된 부분의 단어를 예측
- NSP : 첫번째 [CLS] 토큰으로 A 다음 문장이 B가 맞느냐? →True 틀리냐? → False 를 예측, DownStream
subsequent 연구 결과로 NSP Loss의 효과를 신뢰할 수 없다고 판단해서 제거하기로 결정 ( 상대적으로 쉽다 )
그래도 문장 간 모델링은 중요하기 때문에, SOP Loss를 도입 했다.
- topic prediction ( 같은 주제이기만 하면 ~ ) → inter-sentence coherence ( 두 문장의 연관 관계 )
Sentence Ordering Prediction
- Positive Example : 실제 연속인 두 문장 ( NSP의 Positive Example과 같음 )
- Negative Example : 두 문장의 순서를 앞뒤로 스왑 ( 두 문장의 순서가 옳은 지 )
3.2 MODEL SETUP

9
ALBERT-large, ALBERT-xlarge, ALBERT-xxlarge VS BERT-large의 파라미터와 히든 사이즈 그리고 레이어
4 EXPERIMENTAL RESULTS
4.1 EXPERIMENTAL SETUP
BERT와 동일한 세팅으로 BOOKCORPUS와 ENGLISH WIKIPEDIA ( 16GB 정도 )
$[CLS] x_1 [SEP] x_2 [SEP]$, 최대 인풋 길이를 512, 10%로 512 이하로 입력 시퀀스 생성
vocab 사이즈를 30,000 개, SentencePiece로 토큰화 ( XLNet 에서와 같이 )
max 3-gram 마스킹을 랜덤 하게 마스킹 입력을 위한 MLM 타겟을 생성했다.
배치 사이즈 4096, LAMB 옵티마이저를 0.00176 학습율으로 사용했다.
Cloud TPU V3, 64 - 512 개를 사용했다.
4.2 EVALUATION BENCHMARKS
4.2.1 INTRINSIC BENCHMARK
SQuAD와 RACE 데이터셋에 4.1 섹션과 동일한 세팅으로 MLM과 문장 분류 태스크에 정확도를 제시함.
다운 스트림 태스크에 대한 성능 검증 과는 별개로 수렴하는 과정을 보이는데 사용했다.
4.2.2 DOWNSTREAM EVALUATION
GLUE, SQuAD, RACE 벤치마크 데이터 셋을 사용했다.
GLUE 데이터셋은 Variance 문제로(일반화가 잘 안되어서 ) 5번의 실험의 중앙값을 사용함.
4.3 OVERALL COMPARISION BETWEEN BERT AND ALBERT
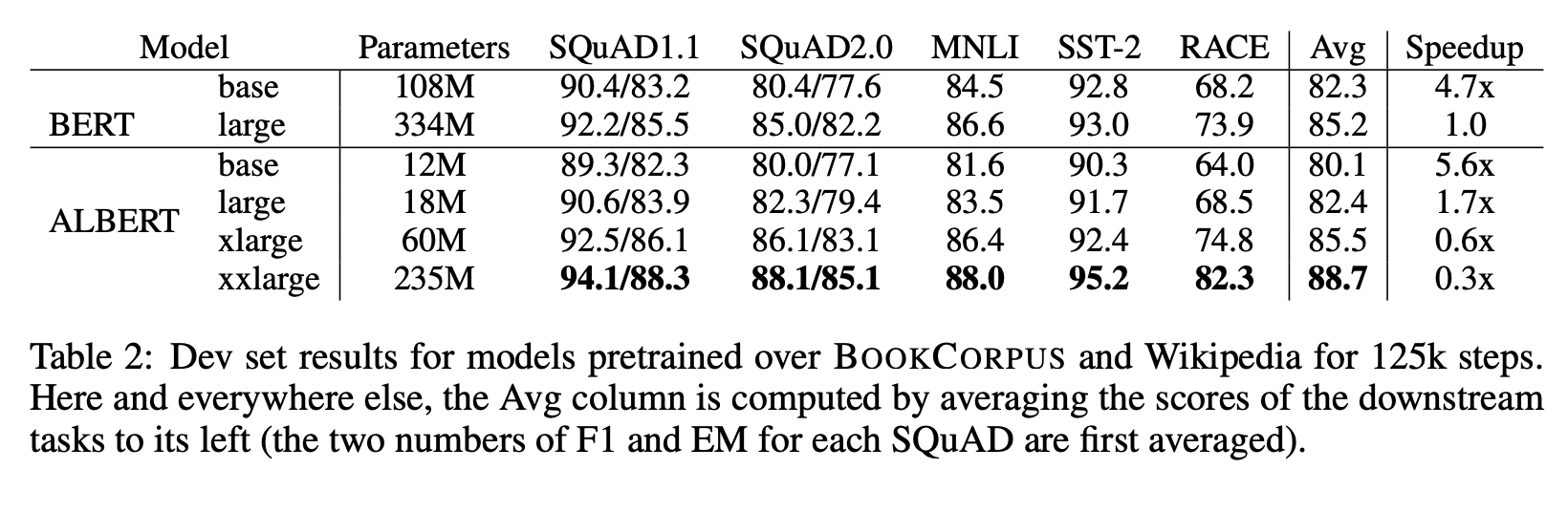
10
ALBERT-xxlarge(BERT-large의 70% 파라미터)로 다운-스트림 태스크에 성능 향상을 보였다.
동일한 컴퓨팅 리소스 환경에서도 학습 시간이 빨랐다. ( BERT-LARGE에 비해 ALBERT-LARGE가 1.7배 빠름 )
4.4 FACTORIZED EMBEDDING PARAMETERIZATION
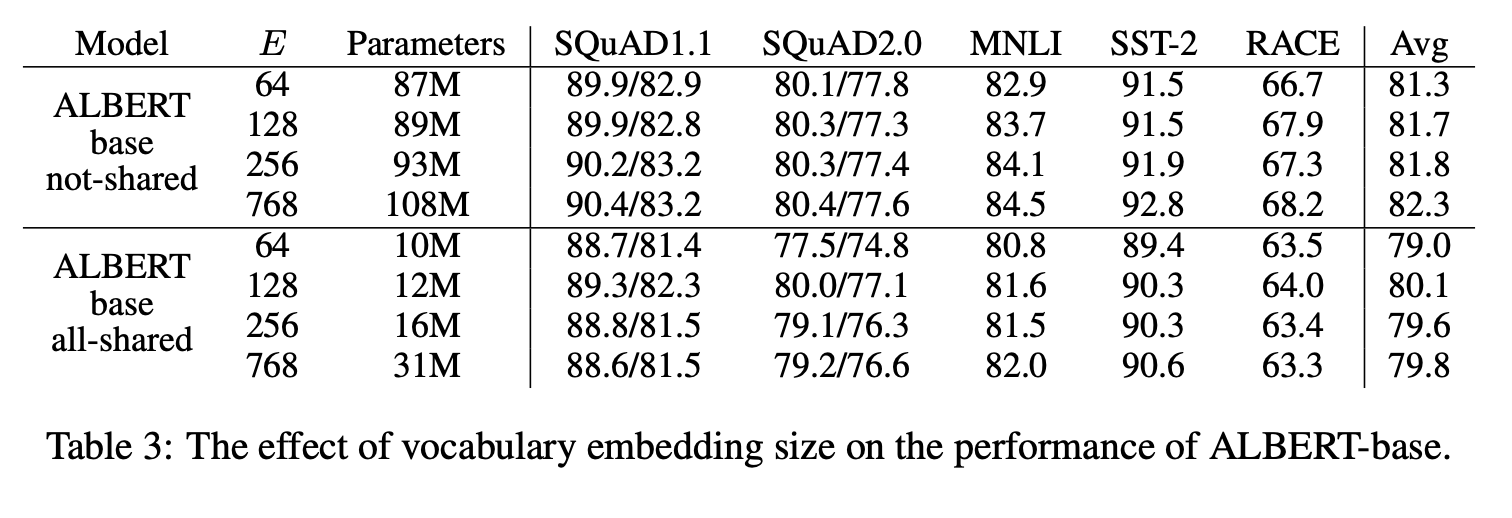
11
non-shared 상태 ( BERT ) 에서 임베딩 사이즈가 커질 수록 더 좋은 성능을 보였지만 그다지
all-shared 상태 ( ALBERT ) 에서 E=128일 때 최고였다.
4.5 CROSS-LAYER PARAMETER SHARING
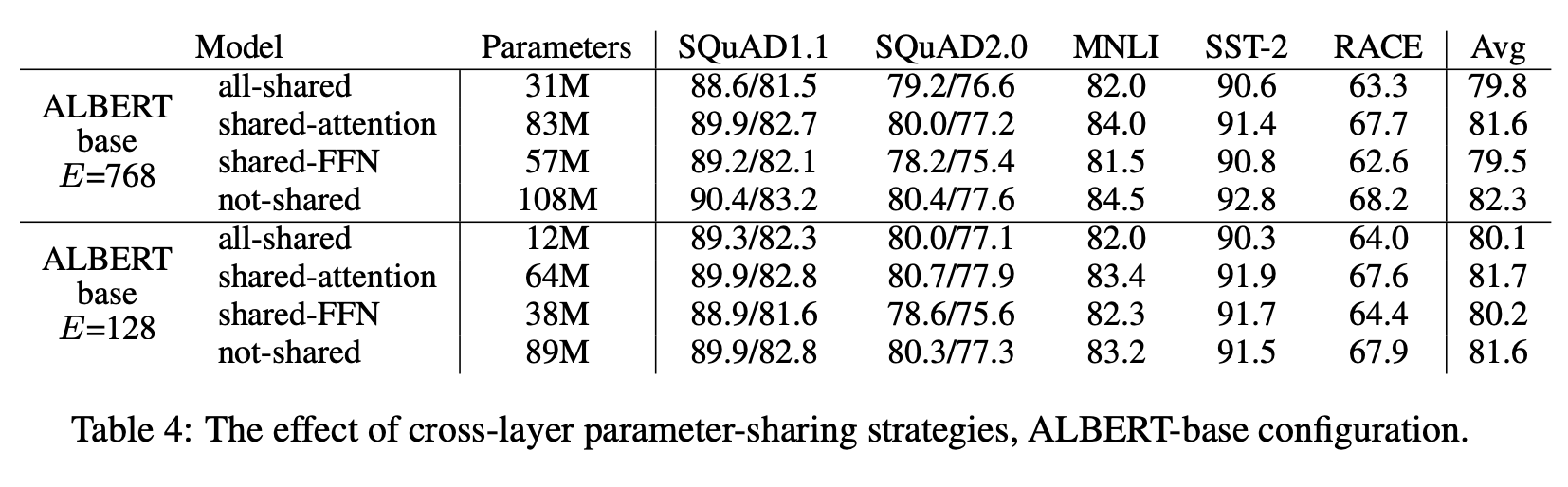
12
all-shared 에서 대부분의 성능 감소는 FFN-Layer 파라미터 공유에서 발생 했다.
레이어 사이즈 L을 크기 M을 가지는 그룹 N개로 그룹 내에서만 파라미터 공유를 하게 전략을 세우기도 했는데 M을 작게 가져가는 전략이 더 좋은 성능을 보였다. 그룹의 크기 M을 줄이는 방법이 파라미터 수를 더 많이 줄임
4.6 SENTENCE ORDER PREDICTION (SOP)

13
NSP를 학습 했을 때, SOP 태스크의 성능이 52%로 좋지 않았다. 결국 NSP는 Topic Modeling 정도만 한다.는 결론이 도출 될 수 있다.
SOP가 multi-sentence encoding task에서 상당히 성능을 개선 시키는 것을 보인다.
4.7 WHAT IF WE TRAIN FOR THE SAME MOUNT OF TIME

14
BERT-large와 ALBERT-xxlarge의 Table2에서의 데이터 처리량은 3.17배 차이가 난다.
4.8 ADDITIONAL TRAINING DATA AND DROPOUT EFFECTS
WIKIPEDIA 와 BOOKCORPUS 데이터셋에 대해서만 실험이 진행됨.
추가 데이터의 영향에 대해 측정 결과를 보이는데 100만 번 학습 스텝 이후에도 여전히 오버피팅 되지 않아서 드롭아웃을 제거 했다. 그 결과 (b)에서 엄청나게 정확도가 증가했다. 없는게 더 좋다고 한다.
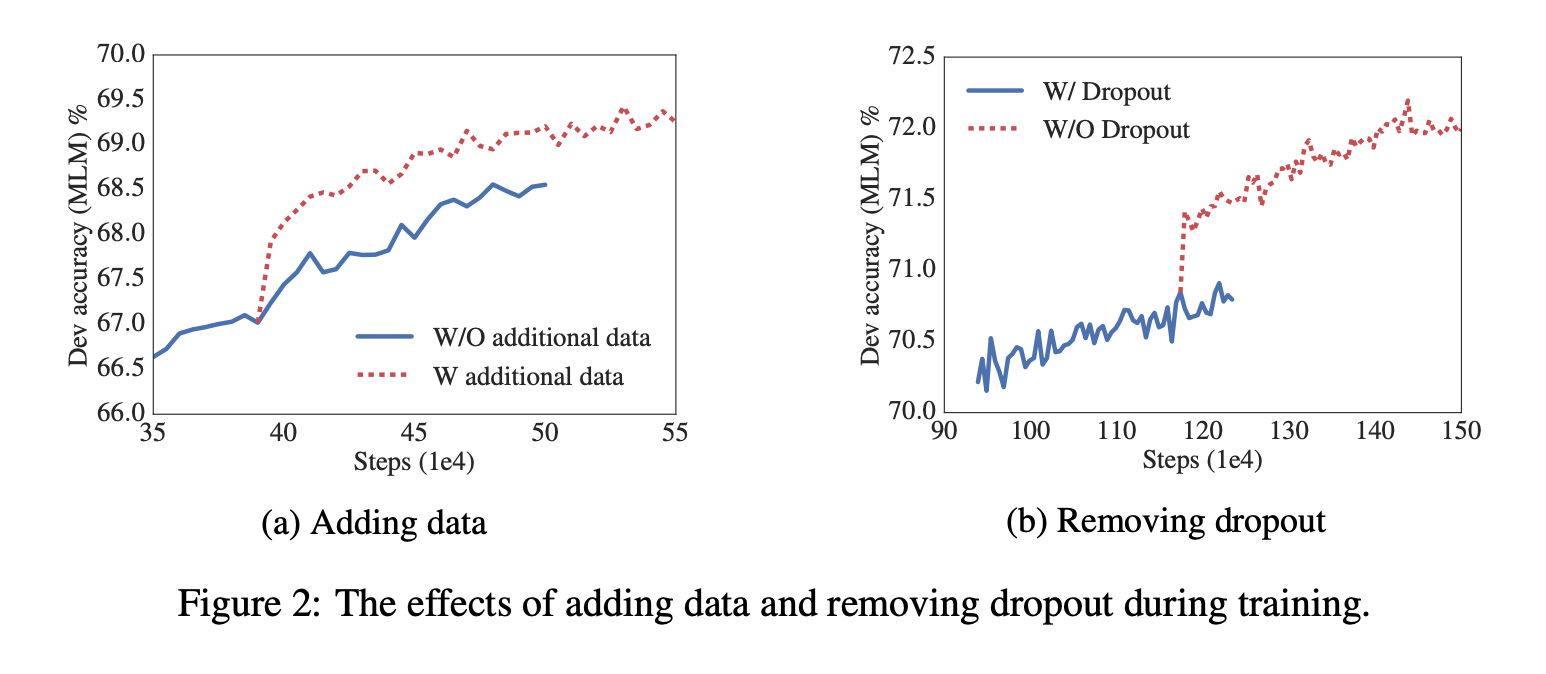
15

16
4.9 CURRENT STATE-OF-THE-ART ON NLU TASKS
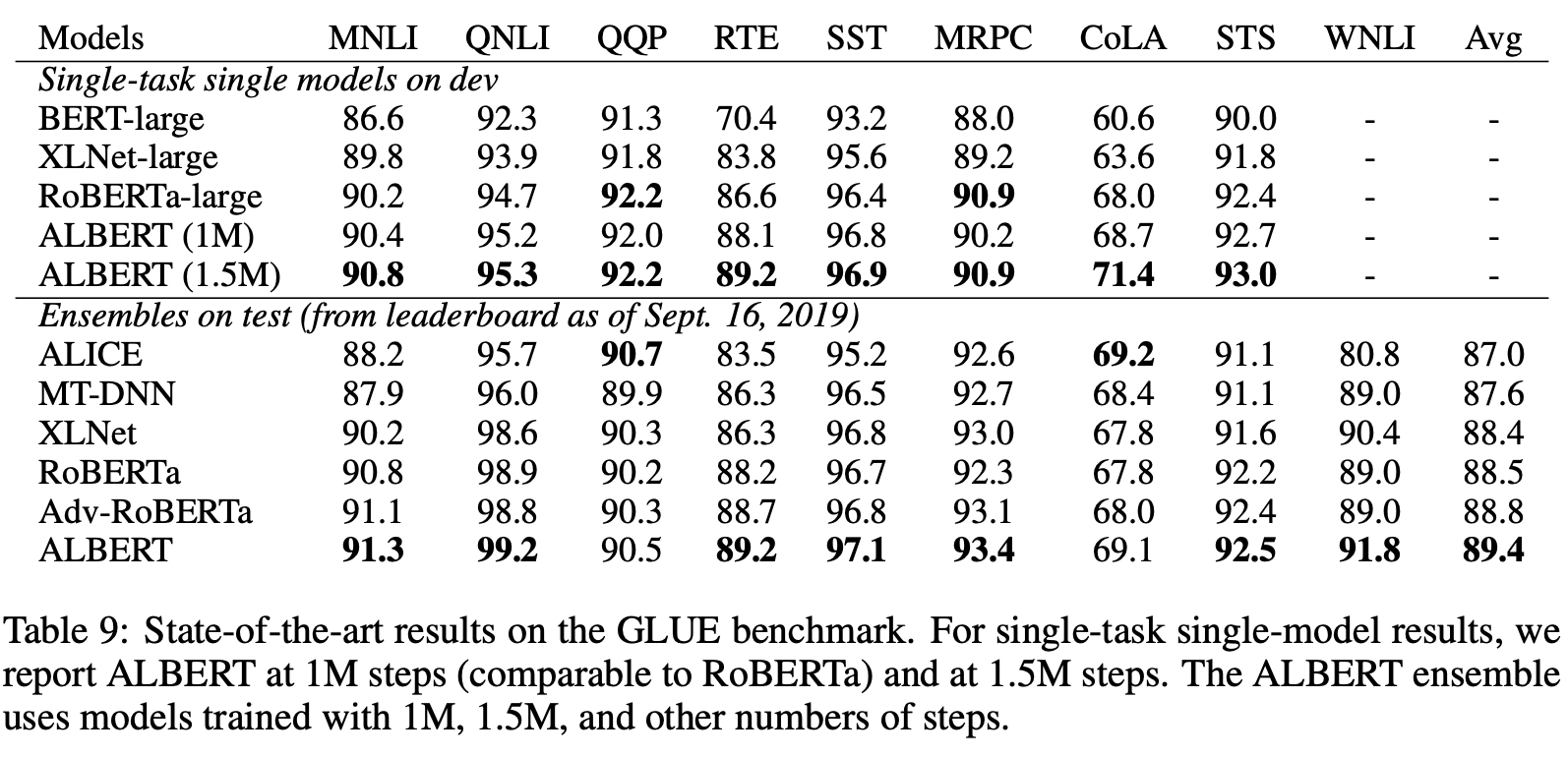
17
ALBERT-xxlarge는 MLM과 SOP과 결합한 Loss로 dropout을 제거했다. 쵝오!
앙상블 모델에서 체크 포인트 수 6-17 로 12개 24개 레이어를 가지는 모델의 결과의 평균을 사용했다. 세 벤치마크 데이터셋 GLUE RACE SQuAD에서도 SOTA를 했다.
앙상블 모델에서 체크 포인트 수 6-17 로 12개 24개 레이어를 가지는 모델의 결과의 평균을 사용했다. 세 벤치마크 데이터셋 GLUE RACE SQuAD에서도 SOTA를 했다.
5 DISCUSSION
ALBERT는 BERT에 비해 파라미터 수를 많이 줄였지만 성능이 월등하게 더 좋다.
후속으로
- sparse-attention 이나 block-attention을 사용해서 학습과 추론 속도도 더 좋게 만들겠다.
- example-mining 이나 더 좋은 언어 모델링으로 추가적인 표현력을 더 좋게 만들겠다.
SOP는 언어 표현력을 위해 일관적으로 유용한 학습 태스크이다. 더 높은 표현력을 위한 self-supervised training loss가 더 있다고 가정한다.