딥러닝 모델의 배포와 모니터링 : Full Stack Deep Learning Lecture 11 정리
Full Stack Deep Learning의 원본 강의 11 챕터를 정리한 내용입니다.
Notes
프로덕션에서의 ML에서는 초당 수천 혹은 수백만 예측을 딜리버리하는 유저의 요구사항을 다룬다. 반면에 노트북에서의 ML은 올바른 방식으로 셀들을 동작시키면 동작한다. 솔직하게 말하면 대부분의 데이터 사이언티스트와 ML 엔지니어들은 어떻게 ML 시스템을 배포하는지 모른다. 그래서 이 강의의 목적은 그 태스크를 수행하기 위한 다양한 방법을 제공한다.
1. 모델 배포
1. 배포 타입들
ML 모델 배포를 위한 여러 방법들을 개념화하는 방법 중 하나는 어플리케이션의 전체 구조 중 어느 위치에 배포 할지를 고려하는 방법이 있다.
- Client-Side : 머신( 웹 브라우저, 모바일 디바이스 등등 ) 위에서 ML 모델을 실행한다.
- Server-Side : 원격 서버에서 ML 모델을 동작시키고 연결해서 사용한다.
- Database : 데이터베이스에서 ML 모델 결과 데이터를 추출하고, 렌더링해서, 사용자에게 표시한다.
Batch Prediction
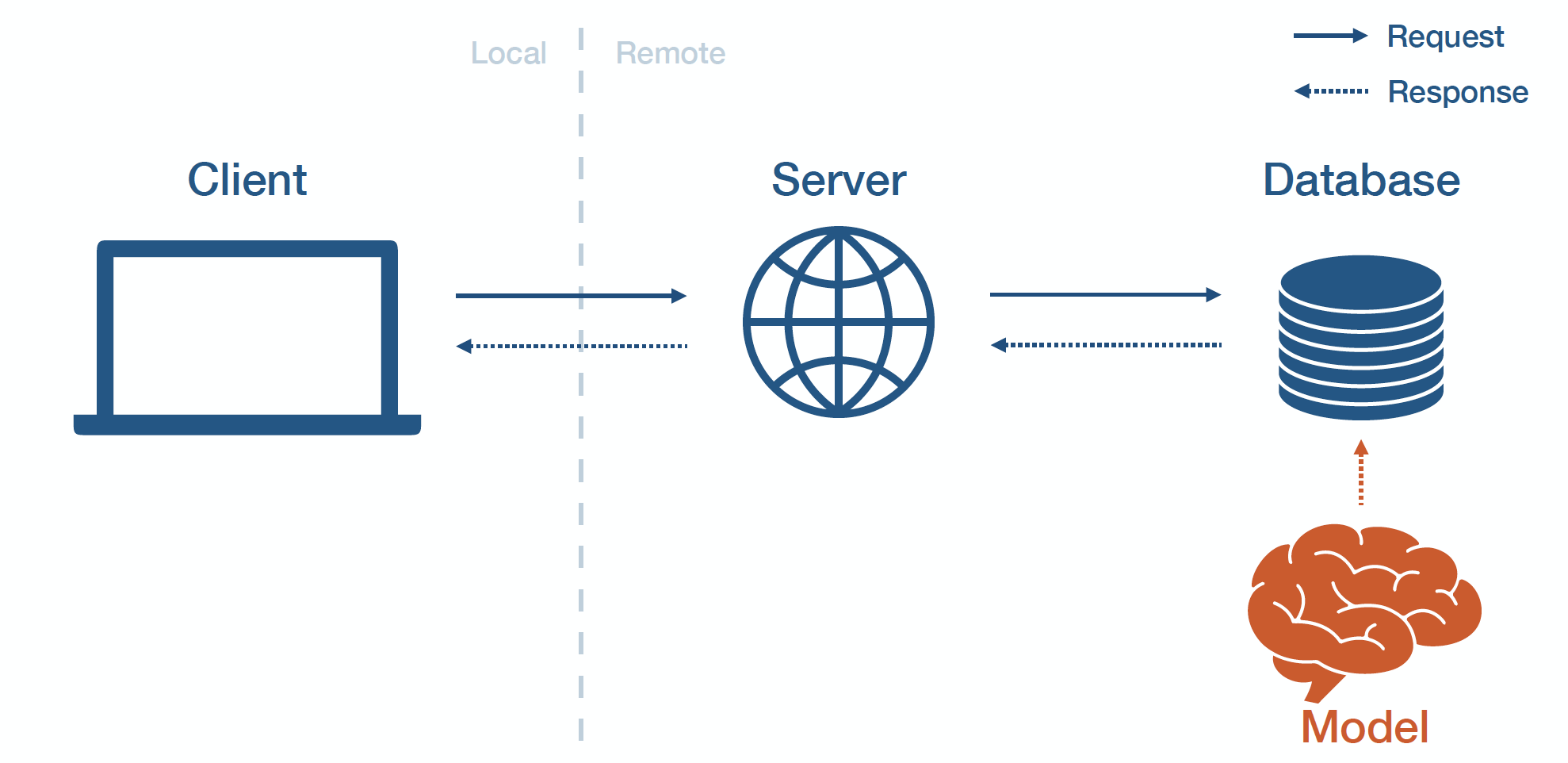
Batch Prediction
배치 예측 방법은 모델을 오프라인에서 학습시키고, 모델의 예측 결과를 데이터베이스에 덤프하고, 그 나머지를 어플리케이션에서 동작시키는 방법이다. 새롭게 들어오는 데이터를 모델을 사용해서 예측 결과를 생성하고 데이터베이스에 캐싱한다. 배치 예측은 입력의 범위가 상대적으로 작을 때(예, 매일 한 유저에게 한번 예측 결과만 필요한 경우 ) 공통적으로 사용하는 흔한 방법이다.
배치 예측의 장점
- 구현이 간단하다
- 유저에게 필요한 대기시간의 적다
배치 예측의 단점
- 복잡한 입력 타입에는 적합하지 않다
- 유저가 최신 예측 결과를 받지 못한다
- 모델이 빈번하게 “도태"되며 그걸 발견하는게 쉽지 않다
MODEL-IN-SERVICE
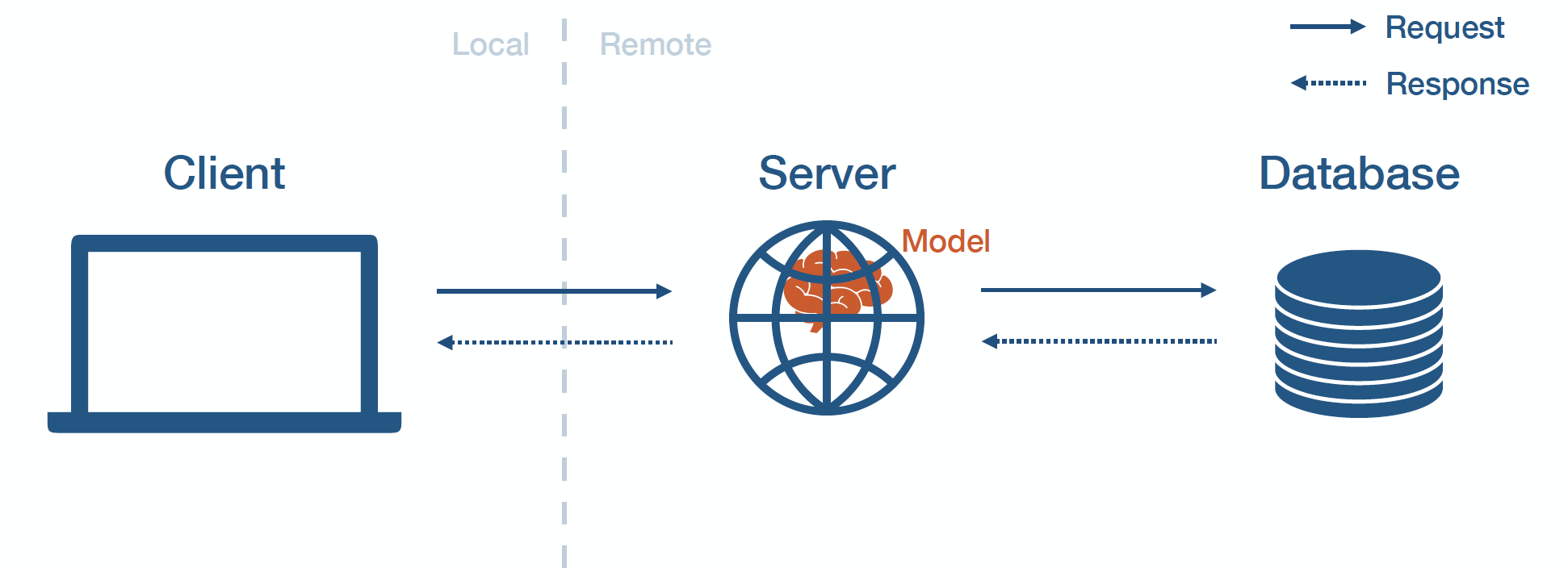
Model-In-Service
모델을 패키지화 하고 배포된 웹 서버에 포함시키는 방식을 모델 인 서비스 방식이라고 한다. 웹 서버가 모델을 로드하고 클라이언트가 서버에 호출 하는 방식으로 모델 예측을 수행한다.
모델-인-서비스의 장점
- 이미 존재하는 인프라를 재사용 한다
모델-인-서비스의 단점
- 웹 서버가 서로 다른 언어로 작성될 수 있다
- 서버 코드에 비해 모델 코드가 더 빈번하게 변경될 수 있다
- 대형 모델은 서버 리소스의 대부분을 차지할 수 있다
- 서버의 하드웨어 스펙이 모델에 최적화 되어있지 않다 ( GPU를 지원하지 않는 하드웨어 스펙 )
- 모델과 서버가 서로와 다르게 각각 확장 될 수 있다
MODEL-AS-SERVICE
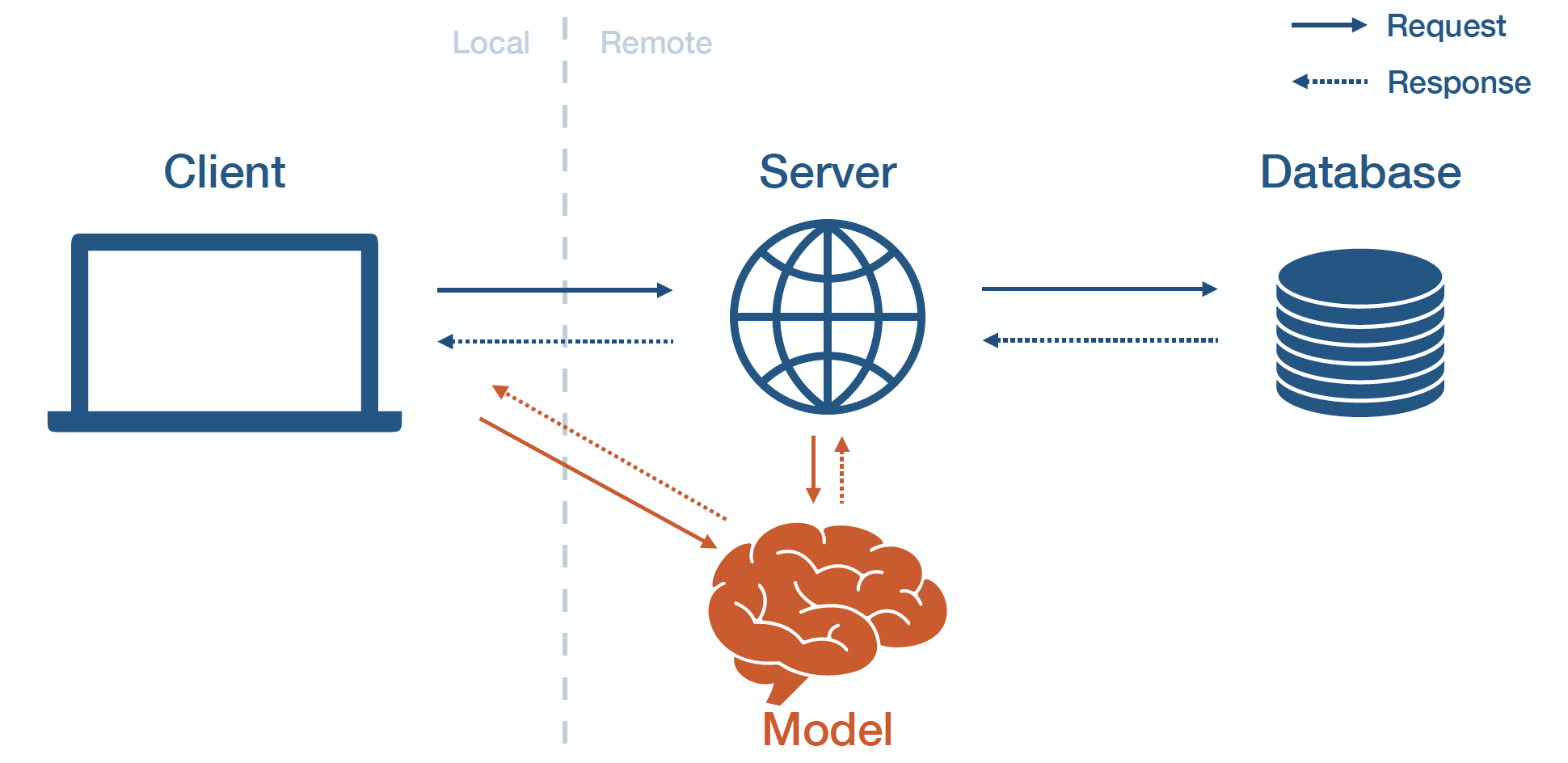
Model-As-Service
고유한 서비스의 형태 모델을 배포하는 방식을 모델-애스-서비스라고 한다. 클라이언트와 서버가 모델 서비스에 요청 하고 응답을 받는 형태로 모델과 상호작용한다.
모델-애스-서비스의 장점
- 모델의 버그가 웹 앱을 크래쉬할 가능성이 낮다
- 모델에 최적화된 하드웨어 스펙을 선택하고 적절하게 확장할 수 있다
- 다양한 어플리케이션에서 모델을 쉽게 재사용할 수 있어 유연하다
모델-애스-서비스의 단점
- 대기 시간이 추가된다
- 인프라적으로 복잡해진다
2. 모델 서비스 구축하기
REST APIS
REST API는 정형화된 HTTP 요청에 대한 응답을 제공하는 방법을 의미한다. 대안으로 gRPC와 GraphQL도 있다. ( 예를 들어, 커맨드라인으로 CURL을 사용해서 URL에 데이터를 POST로 요청하고 모델 예측이 포함된 JSON을 응답 받는다 )
ML 모델에 보낼 정형화된 데이터 구조에 대한 표준은 존재하지 않는다.
DEPENDENCY MANAGEMENT
모델 예측은 코드, 모델 가중치, 그리고 코드 의존성에 영향을 받는다. 세가지 모두 웹 서버에 존재해야 한다. 코드와 모델 가중치를 사용하기 위해서 간단하게 로컬에 카피( 혹은 추출할 스크립트를 작성) 할 수 있다. 그러나 의존성은 문제의 원인이 될 수 있어서 까다롭다. 일관성을 가지게 만들기 어렵고 업데이트 하기 어렵기 때문에, 모델의 결과도 의존성에 의해 변경될 수 있다.
코드 의존성을 관리하기 위한 아래의 두가지 전략이 있다.
- 모델의 종속성을 제한한다
- 컨테이너를 사용한다
ONNX

ONNX
첫번째 전략을 이용하기 위해서는 표준 뉴럴 네트워크 포맷이 필요하다. Open Neural Network eXchange ( 요약하면 ONNX )은 각 프레임워크 간의 상호의존성을 허용하기 위해 설계 되었다. ONNX의 목표는 서로 다른 프레임워크 들을 섞어 개발에 장점을 가진 프레임워크가 반드시 추론에도 장점을 가질 필요가 없도록 하는 것이다.
- 약속은 한 툴 스택을 사용해서 학습 하고 추론/예측을 위해 다른 스택을 사용해서 배포하는 것이다. ONNX는 강력하고 개방적인 표준으로 특정 프레임워크에 락인을 방지하고 장기적인 모델 사용을 보장한다.
- 현실은 ML 라이브러리들이 빠르게 변화하고, 트랜슬레이션 레이어에 가끔 버그가 존재한다. 게다가 라이브러리가 아닌 코드를 처리( 피처 전처리 )에 대한 이슈가 있다.
Docker
두번째 전략을 사용하기 위해서는 도커를 배워야 한다. 도커는 운영체제 레벨의 가상화를 수행하는 프로그램으로 컨테이너화로 알려져 있다. 컨테이너화는 완전하게 패키지화된 소프트웨어의 표준화된 단위로 로컬 개발, 코드 이동, 시스템 배포에 사용된다.
파일 시스템과 함께 구성된 프로세스로 직관적으로 컨테이너화를 설명할 수 있다. 하나나 여러 연결된 프로세스를 실행하면, 그 프로세스들은 모두 전체 파일 시스템을 보고 있고, 다른 누구와 공유되지 않는다.
- 아래에 위치하는 하드웨어 레이어와 분리되고 실행 플랫폼과 분리되어 컨테이너의 이식성이 매우 강력해진다
- 데이터를 최소화해서 포함시킬수 있어 경량화가 가능하다
- 외부 노출을 최소화 할 수 있어 보안이 강력하다
컨테이너는 가상 머신과는 다르다.
- 가상 머신은 전체 하드웨어 스택을 가상화하기 위해서 hypervisor가 필요하다. 그리고 여러 게스트 운영체제가 있어 규모가 더 크고 확장이 가능하다. 예로, AWS/GCP/Azure의 클라우드 인스턴스가 있다.
- 컨테이너는 hypervisor와 하드웨어 가상화가 필요없다. 모든 컨테이너는 같은 호스트 커널을 공유한다. 전용으로 격리된 환경이 있고, 더 작은 사이즈와 빠른 부팅 속도를 가지게 한다.
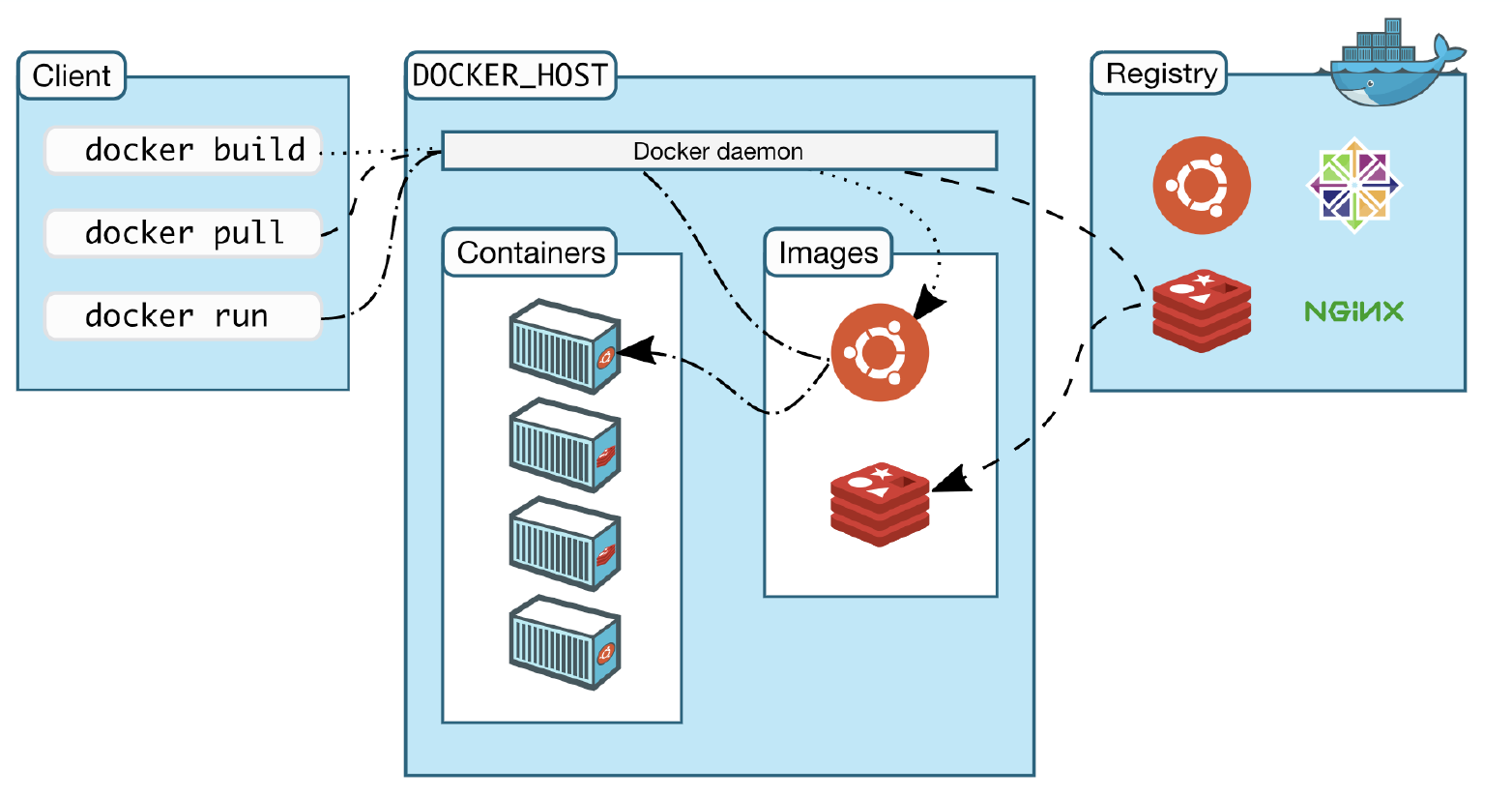
Docker
익숙해져야 하는 기본 개념은 다음과 같다.
- Dockerfile : 이미지를 어떻게 빌드 하는지를 정의한다
- Image : 빌드 되어 패키지화된 환경
- Container : 이미지가 실행되는 내부
- Repository : 이미지의 여러 버전을 호스팅
- Registry : 리파지토리 집합
추가로, 도커는 강력한 에코시스템을 가지고 있다. 커뮤니티에 의해 컨트리뷰트된 DockerHub를 가진다. 이미지를 찾기 쉽고, 수정 없이도, 바로 사용할 수 도 있다.
도커가 개별 마이크로서비스 들을 어떻게 처리할 지를 제시하지만, 전체 서비스 클러스터를 다루기 위한 오케스트레이터(Ochestrator)가 필요하다. 오케스트레이터는 가상 머신이나 베어메탈에 컨테이너를 위치시키고 이 컨테이너 들이 서로 통신하고 태스크를 해결하기 위해 조정한다. 컨테이너 오케스트레이션 툴의 표준은 쿠버네티스(Kubernetes)이다.
PERFORMANCE OPTIMIZATION
단일 머신에서 모델 서비스를 빠르게 실행하는 방법을 다룬다. 해결해야할 주요 의문점은 다음과 같다.
- GPU에서 추론할 것인가? 혹은 아닌가?
- 어떻게 동시에 모델의 여러 카피본을 실행할 것인가?
- 모델을 어떻게 더 작게 만들 것인가?
- 캐싱, 배칭, GPU 공유 등으로 모델 성능을 어떻게 개선할 것인가?
GPU or no GPU?
GPU를 사용할 때의 장점
- 모델을 학습한 하드웨어와 같은 하드웨어를 사용한다
- 모델의 규모를 키우고 모델 사이즈를 제한하고 배치 사이즈를 조정하면, 더 높은 처리량을 얻을 수 있다
GPU를 사용했을 때의 단점
- GPU 구성은 복잡하다
- GPU 비용이 비싸다
Concurrency
머신에 단일 모델의 카피본을 실행하는 대신에, 여러 모델 카피본들을 서로 다른 CPU나 코어 들로 실행할 수 있다. 실전에서는 쓰레드 튜닝(thread tuning)을 조심해서 다루어야 한다. 모델 카피 각각이 최소한의 쓰레드를 사용하게 해야 한다.
Model distilation
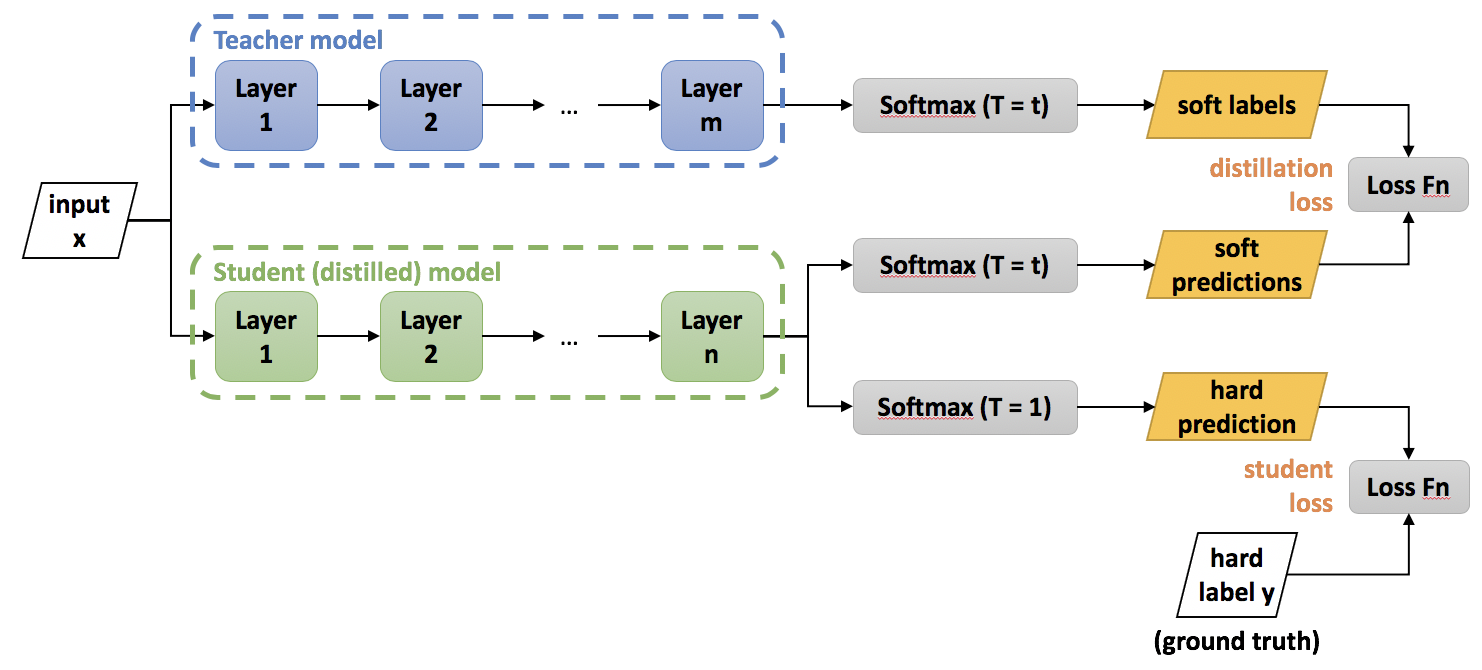
Model Distilation
모델 증류는 압축 기술로 작은 ‘학생’ 모델이 큰 ‘교사’ 모델의 동작을 재현하도록 학습한다. 방법은 Buclia et al., 2006이 처음 제안되었고 Hinton et al., 2015이 일반화했다. 증류에서 교사 모델의 지식은 학생 모델로 손실 함수를 최소화하는 형태로 전파된다. 여기에서 타겟은 교사 모델이 예측한 클래스 확률 분포이다. 즉, 교사 모델의 로짓(logit)의 소프트 맥스 함수의 출력값이다.
증류는 까다로울 수 있기 때문에, 실제로는 거의 사용되지는 않는다.
Model quantization
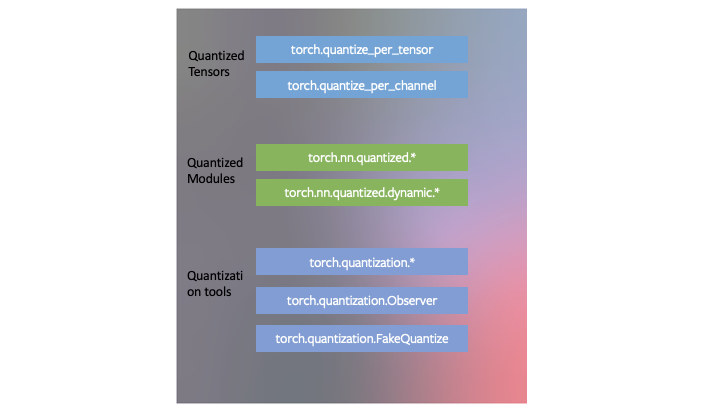
Model Quantization
모델 양자화도 모델 압축 기술로 모델을 물리적으로 작게 만들어 디스크 저장 공간을 절약하고 메모리 사용량을 줄여 연산 속도를 올리는 기술이다. 모델 양자화를 통해 모델 가중치의 수치적인 정확도를 줄인다. 다르게 말하자면 모델의 각 가중치를 영구적으로 더 적은 비트를 사용해서 인코딩한다. 정확도와의 트레이드오프가 있다.
- 텐서플로우 라이트 툴킷에 간단한 메소드가 구현되어 있다. 간단한 ‘center-and-scale’을 적용해서 32비트 float를 8비트 integer로 변경시킨다. : $W_8 = W_32 / scale + shift$ ( 스케일과 시프트는 각각의 가중치 매트릭스에서 개별적으로 결정됨 ). 이 방법으로 $W_8$가 매트릭스 연산에 사용되고, 그 결과는 반대로 ‘center-and-scale’ 연산을 반대로 적용해서 수정된다.
- 파이토치도 빌트인된 양자화 기술이 있고 세가지 기술을 포함한다. dynamic quantization, post-training static quantization, quantization-aware training.
Caching
많은 ML 모델은 입력 분포가 균일하지 않다 ( 일부는 다른 것들에 비해 더 일반적일 수 도 있다 ). 캐싱은 그 부분에 장점이 있다. 어떠한 경우에도 모든 입력에 모델을 호출하는 대신, 자주 사용되는 모델 입력값을 캐싱한다. 모델을 호출하기 이전에, 캐시를 체크하고 자주 사용되는 입력을 호출한다.
캐싱 기술에 요구되는 비용이 상당할 수 있다. 가장 기본적인 방식은 파이썬의 functools를 사용하는 방식이다.

functools.cache
Batching
일반적으로 ML 모델은 병렬( GPU Inference )로 예측 결과를 만들 때 높은 처리량을 달성할 수 있다. 고 레벨에서, 배치가 동작하는 방식은 다음과 같다.
- 배치를 만족할 때까지 들어오는 입력을 모은다. 수집한 배치로 모델을 실행하고 예측 결과를 반환한다
- 처리량과 대기 시간의 트레이드오프를 고려한 배치 사이즈에 조정이 필요하다
- 대기시간이 너무 길어졌을 때를 대비한 프로세스 단축 방법이 필요하다
- 배치 처리를 직접 구현하고 싶지 않을 수 있다
Sharing The GPU
배치 추론 사이즈가 GPU 메모리를 전부 점유하지 않을 수 있다. 동일한 GPU에서 여러 모델을 실행하는건 어떤가? 지원하는 모델 서빙 솔루션들이 있다.
Model Serving Libraries
Pytorch(TorchServe)와 Tensorflow(Tensorflow Serving) 모두 오픈소스 모델 서빙 라이브러리를 제공한다. 다른 선택지로 Ray Serve도 있다. 심지어 NVIDIA도 Triton inference Server가 있다.
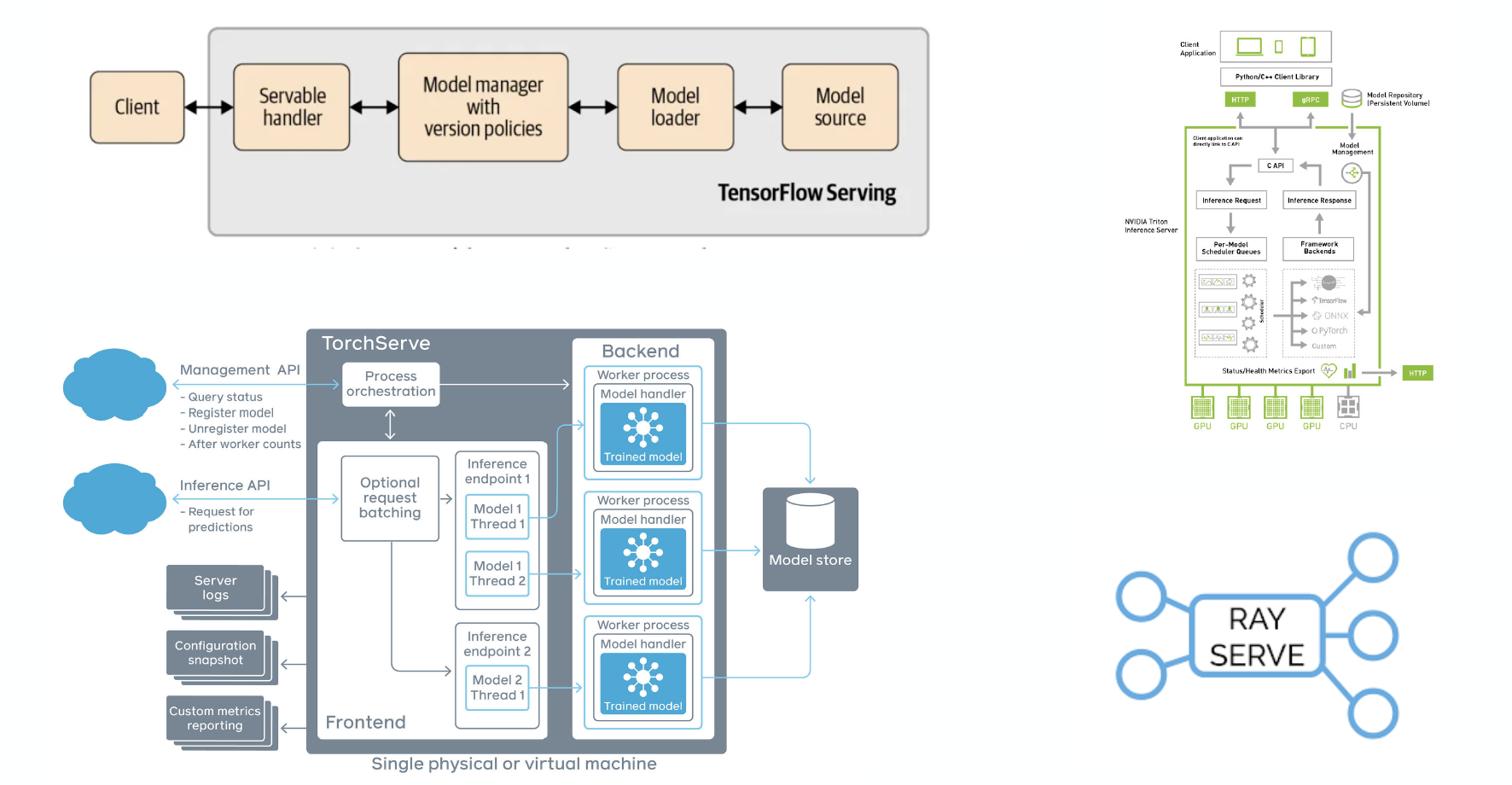
Model Serving Libraries
HORIZONTAL SCALING
단일 머신에 너무 많은 트래픽이 몰릴 때, 여러 머신으로 트래픽을 나누어 보자. 고 수준에서, 예측 서비스를 중복시키고, 로드밸런서를 사용해서 트래픽을 나누고, 복제된 서비스에 트래픽을 보낸다. 실제에서는, 두가지 방법이 있다.
- 쿠버네티스 같은 컨테이너 오케스트레이션을 사용한다
- AWS Lambda와 같은 서버리스 옵션을 사용한다
Container Ochestration
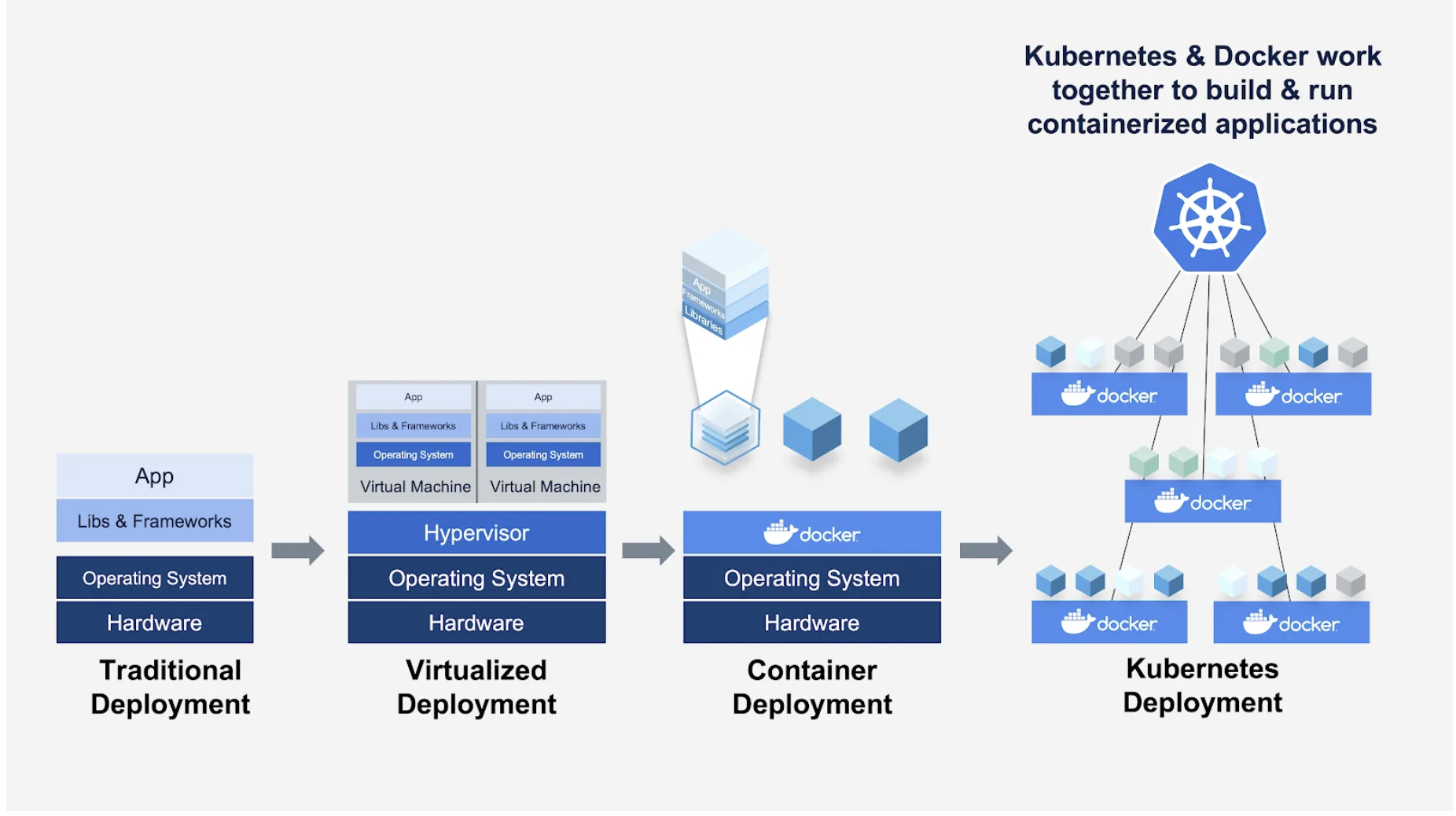
Container Ochestration
이 패러다임에서 도커 컨테이너들은 쿠버네티스에 의해 조정된다. K8S가 요청을 보낼 단일 서비스를 제공하면 가상의 컨테이너 복제본으로 트래픽을 나눠 서비스( 인프라스트럭처 상에서 실행 하고 있는 )로 보낸다.
이러한 시스템을 K8S에서 구축할 수 있다. 이미 동작하고 있는 K8S 클러스터가 있다면 이러한 인프라스트럭처를 탑재한 프레임워크를 사용할 수 있다. KFServing은 Kubeflow 패키지의 일부로 유명한 K8S 네이티브 ML 인프라스트럭처 솔루션이고, Seldon은 K8S 상의 모델 서빙 스택을 제공한다.
Deploying Code As Serverless Functions
이 아이디어는 앱 코드와 의존성들을 단일 엔트리 포인트 함수를 사용해서 .zip 파일들( 혹은 도커 컨테이너 )로 패키지화 하는 것이다. 대표 클라우드 공급자들인 AWS Lamda, Google Cloud Functions 혹은 Azure Functions는 초당 10,000+ 요청으로 즉시 스케일링, 로드밸런싱 등을 제공한다.
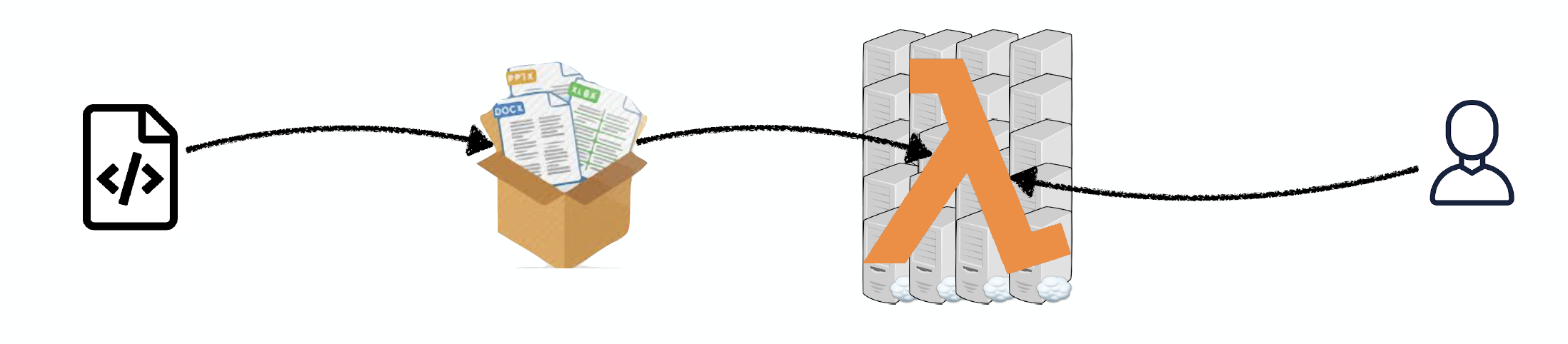
Deploying Code As Serverless Functions
장점은 연산 시간에만 비용을 지불하는 점이다. 추가로 이 접근법은 서버 관리를 줄여서 DevOps 업무 로드 부하를 줄인다.
서버리스의 심각한 제약사항을 가지고 있다.
- 전체 배포 패키지가 제한되어 있다
- CPU 연산만 가능하다
- 모델 파이프라인 구축이 어려울 수 있다
- 상태 관리와 배포 툴이 제한된다
MODEL DEPLOYMENT
서빙을 모델을 요청에 응답을 하는 어떤 것으로 변경이라고 하면, 배포는 이러한 서비스를 롤-아웃, 관리 그리고 업데이트를 하는 방법이다. 점진적으로 롤-아웃, 즉시 롤-백 그리고 모델 배포 파이프라인을 하기를 원한다면, 여기 많은 인프라스트럭처 선택지가 있다. 배포 라이브러리를 사용하면 간단하게 할 수 있다.
MANAGED OPTIONS

Managed Options
앞에서 언급한 것들을 다루고 싶지 않다면, 시장에 여러가지 관리형 옵션들이 있다. 모든 주요 클라우드 제공사는 미리 정의된 방식으로 모델을 패키지 하거나 API로 만들어준다. Algorithmia와 Cortex와 같은 스타트업과 같은 대안도 있다. 편리하지만 비용을 많이 지불해야한다는 단점이 있다.
TAKEAWAYS
- CPU 추론을 만든다면, 더 많은 서버들을 실행하거나 서버리스로 하는 방법이 있다
- CPU를 사용하지 않거나, 트래픽이 급증하거나 용량이 적다면 서버리스가 좋다
- GPU 추론을 사용한다면, 서빙 툴이 시간을 절약시켜 줄 수 있다
- GPU 추론을 위해 스타트업을 주시할만한 가치가 있다
3 - Edge Deployment
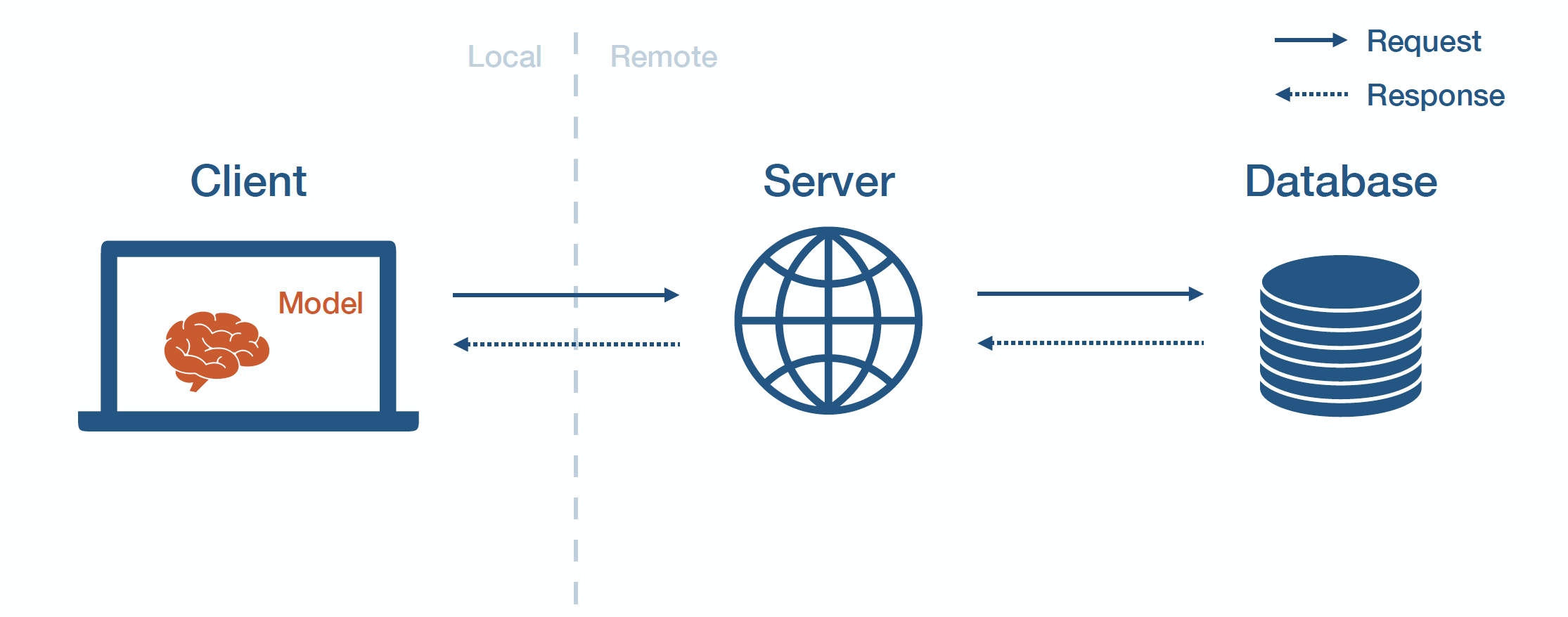
Edge Deployment
엣지 예측은 클라이언트 엣지 디바이스에 모델 가중치를 보낸다는 의미다. 클라이언트에서 모델을 직접 로드하고 직접 상호작용한다.
엣지 예측의 장점
- 대기시간이 짧다
- 인터넷 연결이 필요없다
- 유저의 디바이스에 데이터가 남지 않기 때문에, 데이터 보안 요구사항을 만족한다
엣지 예측의 단점
- 클라이언트의 사용가능한 하드웨어 리소스에 제한이 있을 수 있다
- 임베디드와 모바일 프레임워크가 Tensorflow와 PyTorch에 비해 기능이 제한된다
- 모델 업데이트가 어려울 수 있다
- 이슈가 발생했을 때, 모니터와 디버깅이 어렵다
TOOLS FOR EDGE DEPLOYMENT
TensorRT는 NVIDIA의 프레임워크로 데이터센터의 NVIDIA 기기와 임베디드와 자동화 기기에서의 추론을 위한 모델 최적화를 돕는다. TensorRT는 애플리케이션 별 SDK와 통합되어 개발자가 대화형 AI, 추천, 화상 회의 그리고 스트리밍 앱을 배포할 수 있는 통합 경로를 제공한다.
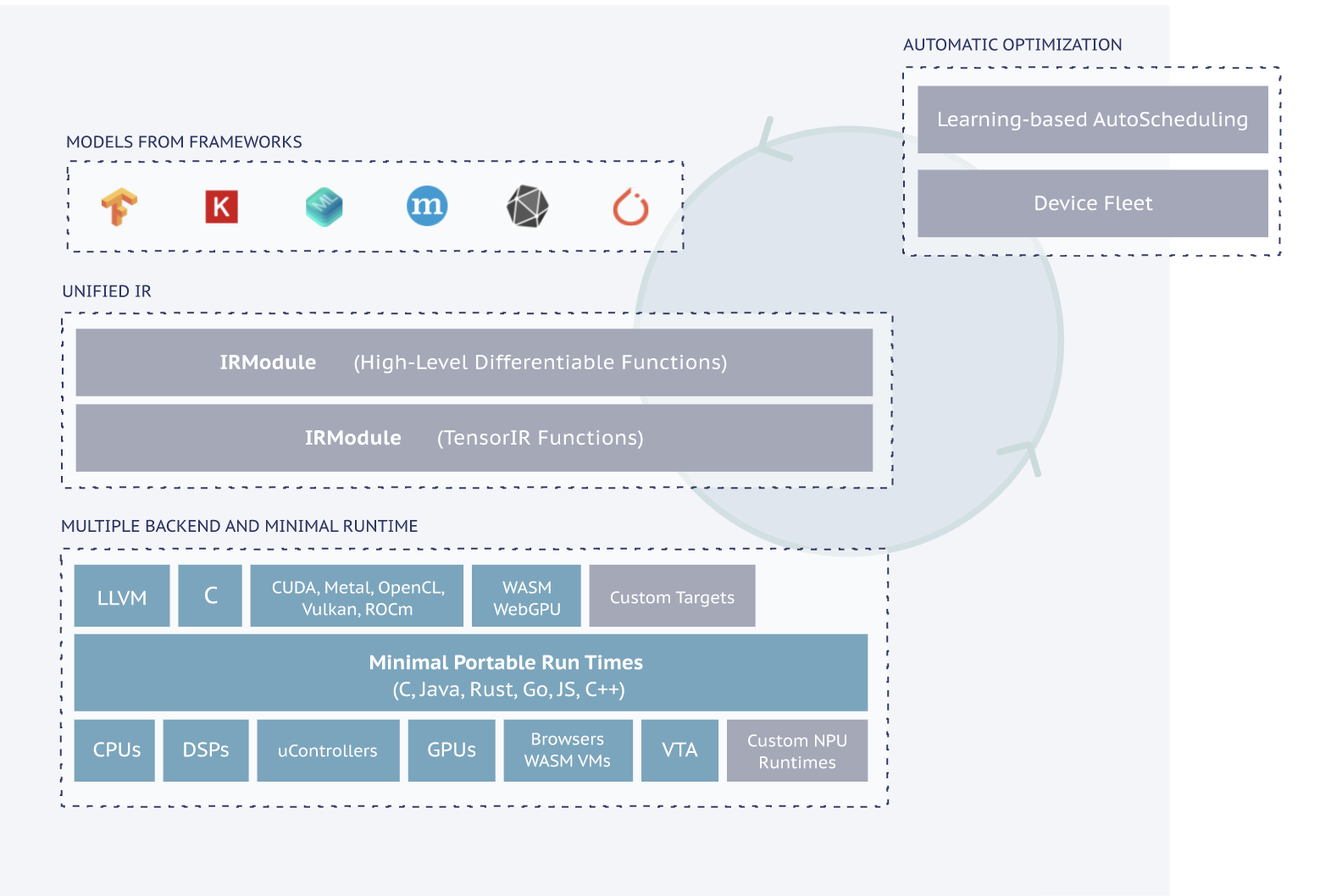
Tools For Edge Deployment
ApacheTVM은 CPUs, GPUs, 그리고 ML 가속기를 위한 오픈소스 머신러닝 컴파일러이다. ML 엔지니어가 어떤 하드웨어 백엔드에서든 효율적인 연산과 최적화를 가능하게한다. 특히, ML 모델을 배포 가능한 최소한의 모듈로 컴파일하고 더 많은 백엔드에서 모델을 자동으로 더 좋은 성능으로 최적화하는 인프라스트럭처를 제공한다.
Tensorflow Lite 모바일이나 임베디드 애플리케이션으로 압축되거나 배포하기 위한 학습된 텐서플로우 모델 프레임워크를 제공한다. 텐서플로우의 고비용의 연산 학습 프로세스는 최적의 환경( 개인 서버, 클라우드, 오버클록된 컴퓨터 )에서 수행될 수 있다. 그 후 텐서플로우 라이트가 결과 모델( 고정된 그래프, 저장된모델, HDF5 모델 )을 입력, 패키지, 배포한 다음에 클라이언트 애플리케이션으로 해석하고, 최적화해서 리소스를 절약한다.
PyTorch Mobile 모바일 개발자와 ML 엔지니어가 파이토치 모델을 온디바이스로 임베드 하는 것을 돕는 프레임워크다. 현재는 어떤 토치 스크립트 모델이라도 IOS 내부와 안드로이드 애플리케이션에서 직접적으로 동작하게 할 수 있다. 파이토치 모바일의 첫번째 릴리즈에서는 성능에 영향을 거의 미치지 않으면서도 모델 사이즈를 줄이는 양자화 기술 지원했다. 파이토치 모바일로 다른 툴/프레임워크를 사용하지 않아도 모델을 모바일 지원 형식으로 직접 변환할 수 있다.
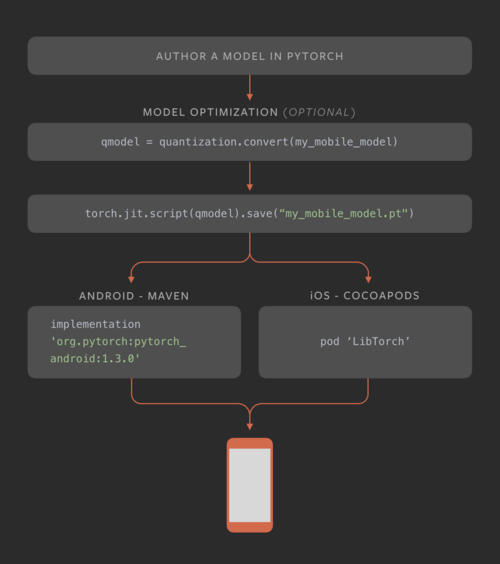
PyTorch Mobile
Tensorflow.js 자바스크립트는 서로 다른 디바이스에서 코드를 실행하는 간편한 방법이다. Tensorflow.js 는 텐서플로우 코드를 자바스크립트에서 실행하게 해준다. 유연하고 직관적인 API를 사용해서 기존의 상용화된 자바스크립트 모델을 사용하거나, 파이썬 텐서플로우 모델이 브라우저나 Node.JS로 동작하도록 변환하거나. 기존의 ML 모델을 데이터를 가지고 재학습 하거나, 자바스크립트에서 모델을 직접 구축/실행할 수 있다
Core ML 은 애플이 2017년이 릴리즈 했다. 온디바이스에서의 성능을 최적화해서 모델의 메모리 풋 프린트와 파워 소비를 최소화한다. 디바이스 상에서의 실행은 유저 데이터가 보안적으로 안전하다는 것을 보장한다. 네트워크 연결 없이도 앱이 동작한다. 많은 코드를 사용하지 않더라도 완전한 ML 코드를 디바이스와 통합할 수 있어 모델에 대한 학습 없이도 모델 추론이 가능하다.
ML Kit 는 2018년에 구글 파이어베이스가 발표했다. 개발자들이 모바일 앱에서 (1) API를 통해 클라우드에서 추론하거나 (2) 온디바이스에서 추론 ( Core ML 같이 ) 머신러닝을 이용 가능하게 한다. 전자의 경우, ML Kit는 이미지 라벨링, 텍스트 인식, 그리고 바코드 인식 같은 기본 여섯개의 API를 제공한다. 후자의 경우, 클라우드에 비해서는 낮은 정확도를 제공하지만 유저 데이터 면에서 보안성이 높다.
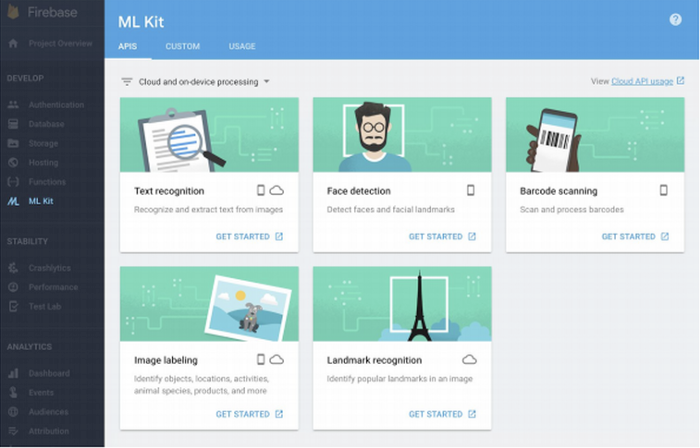
ML Kit
위의 선택지들에 대해 관심이 있다면, FritzAI 팀에서 진행한 비교 결과를 확인 해볼 수 있다. 추가적으로, FritzAI는 모바일 개발자를 위한 ML 플랫폼으로 사전 학습 모델, 개발자 툴, iOS를 위한 SDK, 안드로이드, 유니티를 제공한다.
MORE EFFICIENT MODEL
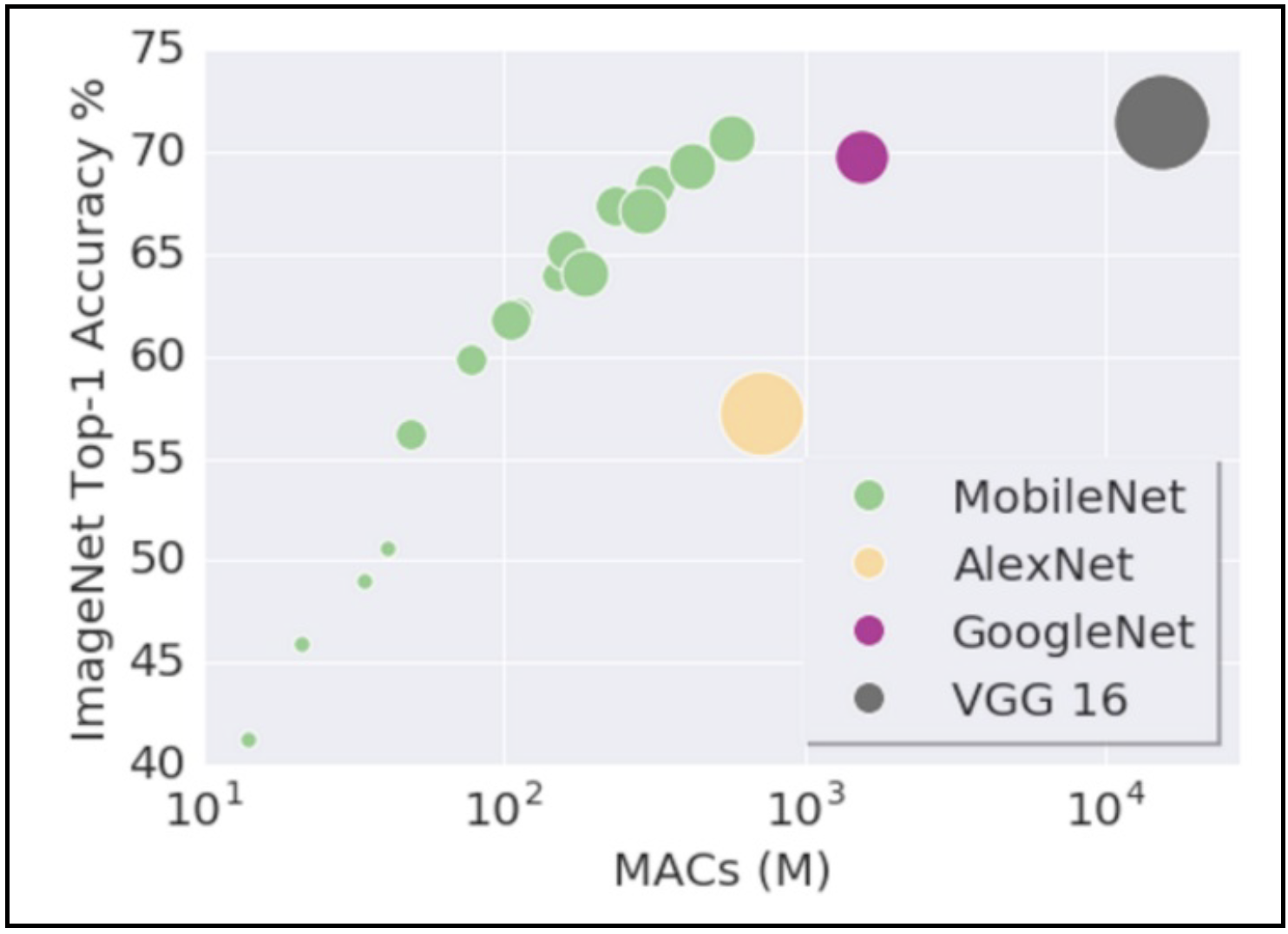
More Efficient Model
엣지 배포를 위한 다른 고려사항은 더 효율적인 모델을 만드는 것이다. 한가지 방법은 위에서 언급한 양자화나 증류를 사용하는 것이다. 다른 방법은 모바일 친화적인 모델 구조를 선택하는 것이다. 첫번째 성공 사례로 MobileNet가 있다. 기존 ConvNet 구조에 다양한 다운샘플링 기술을 수행하여 모바일이나 임베디드 디바이스의 제한된 리소스를 고려하면서도 정확도를 최대화한 구조이다. Yusuke Uchida의 분석 결과는 왜 모바일넷과 그 변형들의 빠른지에 대해 설명되어 있다.
지식 증류의 잘 알려진 사례로 허깅 페이스의 DistilBERT가 있다. 유명한 BERT 언어 모델로 부터 파생된 더 작은 언어 모델이다. DistilBERT는 토큰 타입 임베딩과 BERT의 풀러( NSP 분류 태스크를 위해 사용되었던 )를 제거하고 나머지 구조는 유지했다. 레이어 수는 2배 감소 시켰다. BERT 베이스에 비해 전체 파라미터 수를 반으로 줄였지만 언어 이해 태스크인 GLUE에서 95%의 성능을 유지했다.
MINDSET FOR EDGE DEPLOYMENT
- 타겟 하드웨어를 고려해서 아키텍처를 선택하는 것은 중요하다. 증류, 양자화, 그리고 다른 트릭을 2-10 정도의 팩터로 구성할 수 있다.
- 엣지 디바이스에서 동작하는 모델을 가졌을 때, 회귀를 회피하는 한 반복적으로 메트릭에 모델 사이즈와 대기 시간을 반복적으로 추가할 수 있다.
- 디바이스를 위한 모델 튜닝을 배포 사이클과 테스트에서의 추가 리스크로 봐야한다. 실제 배포 전에 프로덕션 하드웨어에서 모델을 반드시 테스트 해야 한다.
- 모델이 까다로울 수 있기 때문에, 모델이 실패하거나 너무 느려질 경우를 대비해서 폴백 메커니즘을 구축하는 것이 좋다.
TAKEAWAYS
- 웹 배포가 더 쉬우니 반드시 필요한 경우, 엣지 배포를 진행한다.
- 사용가능한 하드웨어와 해당되는 모바일 프레임워크와 매칭되는 프레임워크를 선택해야한다. 그렇지 않을 경우, 더 유연하게 Apache TVM을 적용해 볼 수 있다.
- 프로젝트 초기에 하드웨어 제약사항을 고려해야하고 그에 따라 구조를 선택해야한다.
2. Model Monitoring
모델을 배포 할 때, 어떻게 모델이 잘 동작할지 확신할까? 모델 모니터링에 대해 알아보자.
모델이 학습 되었을 때, 많은 것들이 잘못될 수 있다. 모델이 잘 학습 되어도 잘못될 수 있다. 검증과 테스트 셋에서 문제가 없었어도, 여러 슬라이스들과 예측 성능이 강력해도, 테스트된 모델과 트러블 슈팅을 진행했어도, 여전히 문제가 있을 수 있다.
1. Why Model Degrades Post-Deployment
모델을 배포한 후에 모델 성능이 떨어지는 경향이 있다. 왜 이런 일이 발생할 까? 지도 학습은, 함수 f가 데이터의 사후 분포를 근사하도록 만든다. 이러한 프로세스 중 하나( 예, 데이터 $x$ )가 변경되면, 배포된 모델의 성능이 떨어질 수 있다. 아래의 예시 차트는 어떻게 배포 후 성능 감소가 발생하는지 이론적으로 실제로 발생하는지 보인다.

Why Model Degrades Post-Deployment
요약하자면, 모델 성능이 감소할 수 있는 세 주요 방법이 있다 : data drift, concept drift, domain shift
- data drift 에서는 모델을 구축하는데 사용한 기저 데이터에 대한 예상이 변경될 수 있다. 업스트림 데이터 파이프라인 버그나 악의적인 사용자가 모델에 나쁜 데이터를 공급하는 경우가 있을 수 있다.
- concept drift 에서는 모델에서 찾은 실제 결과, 혹은 데이터와 결과 간의 관계가 흐트러질 수 있다. 예를 들어, 유저가 모델의 결과에 기반해 영화를 선택하는 방식이 기존 의도한 방식과 다를 수 있다. 그래서 모델이 근사해야 하는 기본 “컨셉” 자체가 변경될 수 있다.
- domain shift 에서는 만약 데이터셋이 운영 즉 배포 후 환경을 잘 샘플하지 않았다면, 모델의 성능이 낮을 것이다. “롱 테일” 시나리오에서 발생할 수도 있다, 개발 데이터에서는 나타나지 않은 희귀한 예제가 많이 발생할 수 있다.
2. Data Drift
데이터 드리프트의 몇가지 타입이 있다
- Instantneous drift : 이 상황에서는 드리프트의 패러다임이 극적으로 변화한다. 예를 들어, 새로운 도메인으로 모델을 배포 한다. ( 즉, 새로운 도시에 자율 주행 모델 ), 전처리 파이프라인의 버그, COVID와 같은 주요 외부 변화가 있을 수 있다.
- Gradual drift : 이 상황에서는 데이터 값이 시간에 따라 점진적으로 변한다. 예를 들어, 유저의 선호도가 시간에 따라 변화한다. 혹은 새로운 컨셉이 도메인으로 도입된다.
- Predict drift : 데이터가 계절성과 시간대 같은 기본 패턴을 가져서 변동하는 값을 가질 수 있다.
- Temporary drift : 감지하기 가장 힘들고, 단 기간에 변화하고 다시 정상으로 돌아간다. 일시적으로 악의적인 공격을 받거나, 데모그라픽이나 행동이 다른 유저가 설계되지 않은 방향으로 제품을 사용하는 경우가 될 수도 있다.
이러한 카테고리들이 학문적인 카테고리 처럼 보일 수 있지만, 데이터 시프트 결과는 실제이다. 실제로 많은 회사에서 발생하는 문제지만, 이제서야 관심을 받게 되었다.
3. What Should You Monitor?
머신러닝 모델을 위해 모니터할 네가지 핵심 신호가 있다.

What Should You Monitor?
이러한 메트릭들은 얼마나 유익한지와 접근 난이도 간의 트레이드 오프가 있다. 간단하게 말하면, 모니터링 하기 어려운 메트릭 일수록, 유용하다.
- model performance metrics : 모니터 하기 가장 어렵고 좋은 메트릭은 모델 성능 메트릭으로, 실시간으로 획득하기 어려울 수 있다 ( 라벨을 얻기 힘들다 )
- Business metrics : 모델 성능 감소를 모니터링하는 좋은 신호가 될 수 있지만, 다른 고려해야할 사향들과 혼동 될 수 있다
- Model inputs and predictions : 고수준 드리프트를 인식하는 간단한 방법이고 수집하기 쉽다. 실제 성능 임팩트를 평가하기에 어려울 수 있어서, 과학보다는 예술에 가까울 수 있다
- system performance : ( 예, GPU 사용량 ) 심각한 버그를 잡기 위한 거친 방법
어떤 메트릭에 집중해야 하는지 고려했을 때, 그라운드 트루스 메트릭들에 우선순위 하고 ( 모델과 비지니스 메트릭 ), 그 다음, 근사 성능 메트릭( 비지니스와 입력/출력 ), 마지막으로 시스템 헬스 메트릭에 우선순위를 매긴다.
4. How Do You Measure Distribution Changes?
SELECT A REFERENCE WINDOW
모니터 하는 메트릭의 분포 차이를 측정하기 위해서, 새로운 데이터와 비교할 운영 데이터의 레퍼런스를 선택한다. 레퍼런스 데이터를 선택하기 위한 여러가지 방법이 있다. ( 예, 슬라이딩 윈도우나 운영 데이터에서의 고정된 윈도우 ) 그러나 비교를 위한 가장 실전적인 방법은 학습 데이터나 검증 데이터를 레퍼런스 데이터로 사용하는 것이다. 모델 개발 시의 데이터와 들어오는 데이터 간 차이는 조치해야할 중요한 신호이다.
SELECT A MEASUREMENT WINDOW
레퍼런스 윈도우를 선택한 후에, 다음 스텝은 비교할 측정 윈도우, 거리 측정법, 드리프트를 위한 검증법 들을 선택하는 것이다. 측정 윈도우를 선택하는 것은 문제에 많이 의존하기 때문에 챌린징하다. 솔루션으로 데이터 중에서 하나 혹은 여러 윈도우 사이즈를 선택하는 방법이 있다. 메트릭을 계속해서 재연산 하는 것을 방지하기 위해, 윈도우를 슬라이딩할 때, the literature on mergeable (quantile) sketching algorithm을 참고하는 것이 좋다.
COMPARE WINDOWS USING A DISTANCE METRIC
어떤 거리 메트릭을 사용해서 레퍼런스 윈도우와 관측 윈도우를 비교해야하는가? 1-D 메트릭 카테고리들은 다음이 있다.
- Rule-based distance metrics ( 즉, 데이터 퀄리티 ) : 통계 요약, 데이터 볼륨, 결측치, 전체 비교와 같은 더 복잡한 테스트는 적용될 수 있는 공통 데이터 퀄리티 체크다. Great Expectations 는 이를 위한 좋은 라이브러리다. 간단한 룰 기반 메트릭을 하자. 아마존과 구글에 따르면 많은 수의 버그를 잡을 수 있다.
- Statistical distance metrics ( 즉, KS statistics, KL divergence, D_1 distance, etc. )
- KL Divergence : 서로 다른 두 분포의 로그 비율 기댓값으로 정의되어, 많이 알려진 이 메트릭은 분포의 tail 부분에 민감하다. 데이터 시프트 테스트에는 적합하지 않는데 그 이유는 쉽게 방해받을 수 있고, 해석 가능하지 않으며, 서로 다른 분포를 가지는 데이터에 적용 어려움이 있기 때문이다.
- KS Statistic : CDF간 최대 거리로 정의되는 메트릭이다. 해석이 쉽고 그래서 실제로 많이 사용된다.
- D1 Distance : PDF간 거리의 합으로 정의되는 메트릭이다. 구글에서 사용되는 메트릭이다. 원칙적이지 않을 수 있지만, 쉽게 해석가능하고 추가적으로 구글이 사용한다는 이점이 있다.

COMPARE WINDOWS USING A DISTANCE METRIC
연구의 오픈된 영역은 거리 메트릭과 모델 성능에서 달라지는 드리프트 패턴의 효과를 이해하는 것이다. 다른 오픈된 영역은 고차원 거리 메트릭이다. 몇가지 선택지가 있다.
- Maximum mean discrepancy ( 최대 평균 불일치 )
- Performing multiple 1D comparisions across the data : 다중 가설 테스트 문제에서 어려움이 있지만, 실전적인 접근방법이다.
- Prioritize some features for 1D comparisions : 다른 옵션은 모든 피처들을 테스팅하는 것을 방지하는 것으로 메리트가 있는 비교에 집중한다. 예를 들어, 데이터에서 시프트한 피처들만 하는 것이다.
- Projections : ****이 접근법에서, 큰 데이터 포인트들은 차원 축소 프로세스에 거치고 두 샘플 통계 테스트를 거친다. 특정 도메인의 차원을 축소 방법( 이미지의 평균 픽셀 값, 문장의 길이 )에 따라 적용하는 것이 권장된다.
높은 레벨에서, 이 전체 거리 메트릭 작업은 데이터 시프트에 대한 스코어를 인식할 뿐만 아니라 이에 대해 모델이 받는 영향도 이해하려고 한다. 가능한 모든 선택지 중에서 메트릭을 선정하는 것이 복잡할 수 있지만, 배포 후 시나리오에서 모델의 강력함을 이해하는데 집중해야 한다.
5. How Do You Tell If A Change Is Bad?
데이터 내 변화가 나쁘다는 것을 찾아내는 어렵지 않고 빠른 규칙은 존재하지 않는다. 쉬운 옵션은 테스트 값에 임계치를 두는 것이다. KS 테스트 같은 통계 테스트를 사용하지 마라. 작은 시프트에도 굉장히 민감하다. 다른 옵션들은 세팅 메뉴얼 범위, 시간에 따른 값 비교, 이상치 감지를 위한 비지도 모델 적용 등이 있다. 실제에서는, 고정된 룰들, 구체적인 테스트 값의 범위가 널리 사용된다.
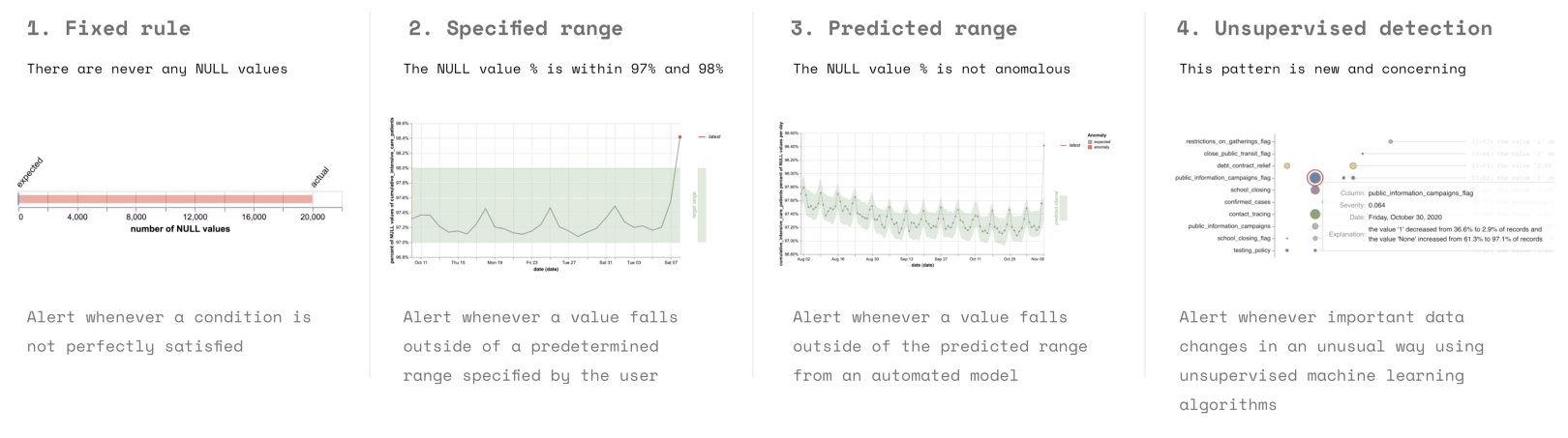
How Do You Tell If A Change Is Bad?
6. Tools For Monitoring
모니터링하기 위한 세가지 카테고리가 있다.
- System monitoring tools : AWS Cloudwatch, Datadog, New Relic, and honeycomb. 기존 성능 메트릭을 테스트한다
- Data quality tools : Great Expectations, Anomalo, and Monte Carlo test. 구체화된 데이터의 윈도우가 룰이나 가정을 어겼는지 테스트한다
- ML monitoring tools : Arize, Fiddler, Arthur도 모델 테스트에 특화되어 있어, 유용할 수 있다.
7. Evaluation Store
모니터링은 기존 소프트웨어에 비해 ML에서 더 중요하다.
- 기존 SWE에서, 대부분의 버그는 오류의 원인이 되고, 모니터링 되는 데이터는 감지할 가치가 있고 문제를 진단하는데 중요하다. 시스템이 잘 동작한다면, 이러한 메트릭 데이터와 모니터링 시스템이 유용하지 않을 수 있다.
- 머신러닝에서, 그러나 모니터링은 다른 역할을 한다. 우선, ML 시스템의 버그는 성능을 조용하게 감소시킨다. 게다가 ML에서 언급된 데이터는 다음 모델의 학습에서 사용되는 코드라고 할 수 있다.
모니터링이 ML 시스템에서 필수적이기 때문에, ML 시스템 구조에 통합하는 것은 많은 이점을 가져온다. 더 나은 통합과 모니터링 사례, 검증 저장소를 만들고, 이전 클래스에서 언급했던 개념인 data flywheel loop 을 클로즈 할 수 있다.
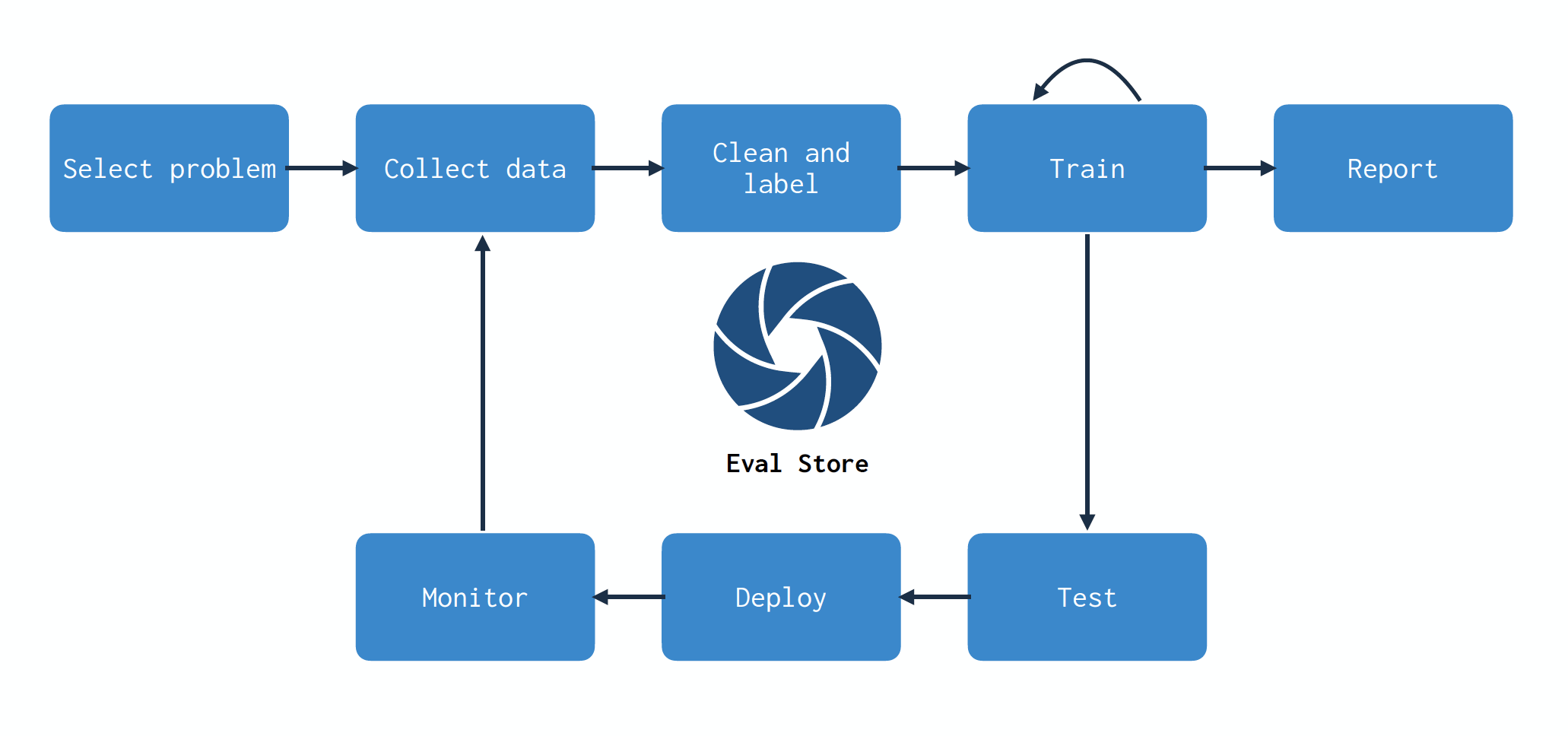
data flywheel loop
모델을 구축할 때, 데이터와 모델 간의 매핑을 만든다. 데이터가 변경되면 모델을 재학습하고, 이러한 변화를 모니터 하는 것이 엔드포인트가 되지는 않는다. 전체 모델 개발 프로세스의 부분이 된다. 검증 스토어를 통한 모니터링은 스택의 모든 파트를 건들려야한다. 이 프로세스가 문제를 해결하는데 도움을 주는 것은 어떤 데이터 포인트를 수집, 저장 그리고 라벨링할지 효과적으로 선택하는 것이다. 검증 스토어는 불확실한 성능에 기반해서 더 수집 해야할 데이터를 인식하는 것을 돕는다. 더 많은 데이터가 수집되고 라벨링 되면, 효율적인 재학습이 검증 스토어 가이드에 따라 수행 될 수 있다.
Conclusion
- 항상 무언가가 잘못될 수 있다, 에러를 잡을 시스템을 가지고 있어야한다.
- 쉬운 데이터 퀄리티 메트릭과 시스템 메트릭 부터 살펴보자
- 완벽한 세상에서 테스트와 모니터링은 이어져있어야 하며, 그러면 데이터 플라이휠을 닫는걸 도울 것이다.
- 관련된 툴과 연구가 곧 계속해서 나올 것이다.