Distilling Task-Specific Knowledge from BERT into Simple Neural Networks 리뷰
Distilling Task-Specific Knowledge from BERT into Simple Neural Networks
Abstract
자연어 처리 분야에서 뉴럴 네트워크는 깊어지고 복잡해지고 있다. 최근 트렌드는 딥 언어 표현 모델이고 BERT, ELMo 그리고 GPT가 있다. 이런 발전들은 이전 세대의, 언어 이해를 위한 얕은 뉴럴 네트워크는 쓸모 없다는 확신을 가지게 했다. 그러나 이 논문에서는, 기본적이고 가벼운 뉴럴 네트워크 모델이 구조 변경, 외부 학습 데이터, 추가 입력 피처들 없이도 경쟁력이 있다는 것을 증명한다. 논문에서 SOTA 언어 표현 모델인 BERT의 지식을 레이어 하나를 가지는 BiLSTM으로 녹여낼 뿐만아니라, 문장 쌍 태스크에는 샴 구조로 녹여내는 것을 제시했다. 페러프레이징, 자연어 추론, 감정 분류 데이터셋에 대해 100 배 더 적은 파라미터 수와 15배 단축시킨 추론 시간으로 ELMo와 비교할 만한 결과를 달성했다.
Introduction
자연어 처리 분야에서, 뉴럴 네트워크의 발전은 끝이 없지만, 어느 정도 예측 가능하다. 이전 아키텍처에 비해 새로운 아키텍처는 성능과 가정되는 인사이트 뿐만이 아닌 깊이와 복잡도도 계속해서 증가하고 있다. 이런 발전하는 신경망에서 “1세대” 신경망은 구식이라고 취급 받는다. 단편적으로 봤을 때는 그렇게 보일 수 있다. ELMo은 사전 학습된 딥러닝 기반 언어 표현이 다양한 태스크에서 SOTA를 달성했다. BERT는 이런 연구에서 더 나가 트랜스포머(BERT)의 양방향 인코더 표현으로 더 거대한 모델들이 더 많은 태스크에서 SOTA를 달성했다. OpenAI는 GPT2로 더 많은 데이터로 학습한 더 큰 트랜스포머 모델로 SOTA를 달성했다.
근데 큰 신경망 모델들은 실제로는 문제가 있다. 파라미터 수가 많기 때문이다. BERT와 GPT-2를 예를 들면, 모바일 디바이스 같은 리소스가 제한된 시스템에서 모델 배포가 불가능하다. 추론 속도에서 효율적이지 않아 실시간 시스템에도 적합하지 않다. 게다가 무어의 법칙과 데나드 스케일링의 계속적인 감소는 모델을 반드시 압축하고 신경망 구조 선택을 검증해야 하는 시기가 오고 있다는 것을 암시한다.
이 논문에서는 간단하지만 효과적인 방법론을 제시한다. BERT로 부터 태스크 특화된 knowledge를 더 얕은 신경망 구조(BiLSTM)로 전달 하는 방법이다. 방법론을 제시하게 된 동기는 두가지가 있다.
- 간단한 아키텍처는 정말 텍스트 모델링 능력 부족한가?
- BERT에서 BiLSTM으로 트랜스퍼하는 효과적인 방법에 대해 연구하고 싶었음.
구체적으로 knowledge distillation 방법을 활용하는데, 지식 증류는 큰 모델을 teacher로 제공하고 작은 모델은 student로 선생님을 흉내내는 법을 학습하는 방법이다.
1
지식 증류는 특정 모델에 의존하지 않고, BERT와 다른 신경망 구조 간 지식 전달이 가능하도록 만드는 방식이다. 이 논문에서 말하는 작은 모델이 레이어 하나를 가지는 BiLSTM 모델이다.
효과적인 지식 전달을 가능하게 하기 위해 거대하고 라벨링 되지 않은 데이터 셋이 필요한 경우가 많다. 교사 모델은 확률 로짓과 예측된 라벨을 이러한 라벨링 되지 않은 샘플로 제공하고, 학생 네트워크는 교사의 출력으로 학습을 한다. 비전에서, 라벨링 되지 않은 이미지들을 로테이션, 노이즈 추가나 그밖의 왜곡을 사용해서 데이터 확장 하기 쉽다. 그러나 NLP의 특정 태스크에서는 라벨링 되지 않은 샘플 확보가 어렵다. 기존 NLP의 데이터 확장은 한 태스크에 특화되기 때문에 다른 NLP 태스크로 확장 시키기 어렵다. 그래서 지식 전달 데이터 셋에 사용할 수 있는 새로운 룰 기반의 텍스트 데이터 확장 방법을 제시한다. 이 방법으로 확장한 샘플들이 훌륭한 자연어 문장은 아니지만, 실험 결과에서 지식 증류에 놀랄 정도로 잘 동작한다는 것을 보였다.
논문의 방법을 문장 분류와 문장 매칭의 세가지 태스크에서 검증했다. 실험으로 지식 증류 과정이 간단한 네트워크를 처음부터 학습하는 것에 비해 좋은 성능을 보였다. 이 논문은 BERT에 지식 증류를 한 첫번째 논문으로 간단한 BiLSTM을 ELMO와 비교할만한 성능으로 만들었다고 한다. BiLSTM이 파라미터 수가 100배 적고 추론이 15배 빠르다고 한다. 그렇게 만든 모델로 “small” 모델에서 SOTA를 달성했다.
Related Work
과거에는 NLP에 CNN, RNN 등의 다양한 신경망 구조를 적용하고 개발을 했다. 일반적인 네트워크가 문장 분류나 문장 매칭 같은 태스크에 적용할 수 있었지만, 오직 특정 태스크의 데이터 만 사용해서 학습 했었다.
ELMO는 양방향 언어 모델을 사용해서 신경망 기반으로 contextualized 표현을 학습했고 여섯개의 서로 다른 NLP 태스크에서 많은 개선을 했다. BERT는 트랜스포머를 사용한 양방향 인코더 모델로, 열한개의 NLP 태스크에서 SOTA를 달성했다. 대규모 말뭉치로 학습된 언어 모델인 BERT는 강력한 구문적 능력과 언어의 일반적인 특성을 보유하고 있다. 다운스트림 태스크에서는 보통 NLP 태스크에 파인튜닝하는 방식으로 BERT를 사용한다. 이런 모델은 학습 효율성은 기존에 비해 높지만, 추론 효율은 상당히 낮다.
모델 압축. 추론 가속화를 위해서 대규모 신경망을 압축하는 연구다. 초기 연구는 중요하지 않은 가중치를 pruning(가지치기) 하기 위해 로컬 에러 기반 방법이었다. 최근에는 간단한 압축 파이프라인을 제시했는데. 정확도 감소 없이 모델 사이즈를 40배 감소시킨 연구도 있다. 안타깝지만, 이러한 기술들은 고도로 최적화된 계산 루틴을 방지하는 불규칙한 weight sparsity를 유도하기 때문에 다른 연구는 필터 전체를 제거하는 방법을 연구 했고, 소숫점 연산과 같은 디바이스 중심 메트릭을 대상으로 하는 연구도 있다. 여전히 신경망을 유한 집합에 대량의 입력값을 매핑하는 양자화 연구도 있고, 극단적으로는 이진 가중치와 이진 활성화를 사용하는 이진 네트워크를 연구하기도 한다.
기존의 연구와는 다르게 Knowledge Distillation은 거대한 모델에서 작은 “학생” 모델로 지식 전달을 하는 방법이다. 출력 레벨에서 증류 작업을 하기 때문에, 완전히 다른 구조의 학생 네트워크를 사용할 수 있다. 이 연구 목표는 BERT와 같은 모델을 동시에 압축하는 동시에, 작은 언어 이해 신경망의 표현력을 연구하는 것이기 때문에 지식 증류 방법을 논문에서 사용했다. NLP 분야에서 지식 증류는 기계 번역과 언어 모델링에서 사용 된다.
3 Our Approach
먼저, 지식 증류 방법을 위한 교사와 학생 모델을 선택한다. 다음으로 증류 과정을 설명한다. 증류 과정은 두가지 구성 요소로 구성된다.
- logits-regression 목적 함수 추가
- 전달 데이터셋 구축 ( 효과적인 지식 전달을 위한 학습 셋 확장)
3.1 Model Architecture
Teacher
사전학습하고 파인튜닝한 BERT를 교사 모델로 사용하는데 BERT는 양방향 트랜스포머 인코더를 사용해서 다양한 언어 이해 태스크에서 SOTA를 달성한 모델이다.
- BERT로 입력 문장(문장 쌍)을 피처 벡터 $h \in R^d$ 를 계산한다.
- 벡터를 태스크에 대한 분류기에 사용한다
단일 문장 분류의 경우
- 소프트맥스 레이어를 사용해서 예측된 확률은 $y^{(B)} = softmax (Wh)$로 $W \in R^{k \times d}$는 소프트맥스 가중치 매트릭스이고 k 는 라벨의 수를 의미한다
한 쌍의 문장을 사용하는 태스크의 경우
- 두 문장의 BERT 피처들을 합치고 소프트맥스 레이어로 피딩한다. 학습 과정에서, BERT의 파라미터와 분류기를 크로스 엔트로피 로스를 사용해서 함께 파인튜닝 한다
Student
학생 모델은 레이어가 하나인 BiLSTM에 비선형 분류기를 사용하는 모델이다.
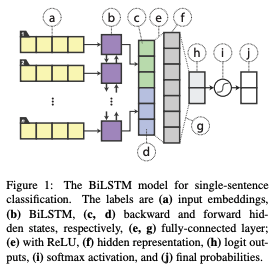
단일 문장 분류의 경우 ( 그림 1 )
- BiLSTM으로 단어 임베딩을 피딩 양방향의 끝의 히든 스테이트를 합친다
- ReLU를 사용하는 fully-connected 레이어로 피딩한다
- 그 후에, 소프트맥스 레이어로 보내져서 분류한다
2
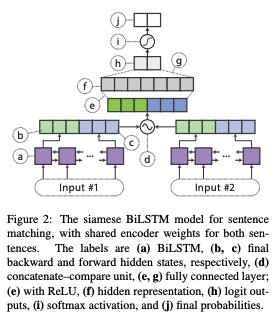
한 쌍의 문장을 사용하는 태스크의 경우 ( 그림 2 )
- 샴 구조로 두 문장 인코더 간 BiLSTM 인코더 가중치를 공유해서 문장 벡터 $h_{s1}$과 $h_{s2}$를 생성한다
- 다음, 표준 concatenate-compare 연산을 두 문장 벡터 간에 적용한다. $f(h_{s1}, h_{s2}) = [h_{s1}, h_{s2}, h_{s1} \odot h_{s2}, |h_{s1} - h_{s2}|]$, $\odot$ 는 엘리먼트 단위 곱을 의미한다
- 그 후에, ReLU를 사용하는 분류기로 로 보낸다
3
BiLSTM 의 표현력을 다시 검토하기 위한 논문의 목적을 위해 아키텍처 엔지니어링을 최소한으로 했다. 어텐션과 레이어 정규화 같은 기술은 사용하지 않았다.
3.2 Distillation Objective
지식 전달을 출력 레벨에서 함으로써 지식 증류를 수행한다. 학생 모델은 특정 데이터 포인트에서 교사 모델의 행동을 모방해서 학습한다. Ba 와 Caruana (2014)는 원 핫 예측 라벨 외에도 교사의 예측 확률이 중요하다고 주장한다. 이진 감정 분류에서, 예를 들면, 어떤 문장은 감정을 강력하게 드러내지만, 다른 문장은 중립일 수 있다. 그렇기 때문에, 만약 학생을 학습 시키기 위해서 교사의 예측된 원 핫 라벨만 사용하면, 예측 불확실성에 대한 귀중한 정보를 잃을 수 있다. 신경망 출력인 확률은 아래와 같이 주어진다.
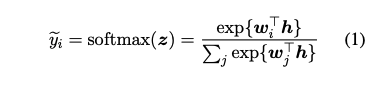
4
$w_i$는 소프트맥스 가중치 $W$의 i 번째 행이고, $z$는 $w^Th$와 같다. 소프트맥스 함수의 인수를 $logits$이라고 한다. logits으로 학습하는 것은 교사 모델로 학습된 관계가 모든 타겟들에 대해 동일하게 강조되기 때문에 학생 모델의 학습을 더 쉽게 만든다.
증류에 사용하는 목적 함수는 학생과 교사 모델 간 logits 차이를 MSE 로스로 패널티를 주는 함수다.
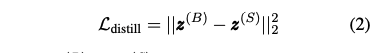
5
$z^{(B)}$와 $z^{(S)}$는 교사와 학생 모델의 logits이다. 소프트 타겟의 크로스 엔트로피를 사용해도 된다. 실험을 했을 때는 MSE가 성능이 조금 더 좋았다.
학습 과정에서의 증류 목적함수는 원 핫 라벨 $t$에 대해 기존 크로스 엔트로피 로스와 함께 사용될 수 있다.
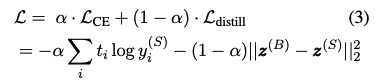
6
라벨링 된 데이터를 사용해서 증류할 때에, 원 핫 타겟 $t$는 그라운드 트루스 라벨이다. 라벨링 되지 않은 데이터셋을 사용하는 경우, 교사 모델로 예측된 라벨을 사용해서, $i = argmax \space y^{(B)}$ 일 때 $t_i = 1$, 아니면 $t_i = 0$이다.
3.3 Data Augmentation for Distillation
증류 접근법에서, 작은 데이터셋으로는 교사 모델이 지식을 완전히 표현하기에 부족할 수 있다. 그래서 학습 셋을 라벨링 되지 않은 데이터셋으로 크게 확장하고, 교사 모델이 제공하는 의사 라벨로 효과적인 지식 증류를 하게 한다.
안타깝게도 비전에 비해 NLP의 데이터 확장은 어렵다. 먼저 비전 태스크에는 많은 동질의 이미지가 존재한다. 비전의 CIFAR-10 데이터셋을 예로 들면, 8천만의 작은 이미지 데이터셋의 서브셋으로 구성된다. 로테이트, 노이즈 추가 그리고 다른 왜곡으로 진짜 이미지에 가깝게 만들 수 있지만, 자연어 문장은 수동으로 조작하면, 문장이 유창하지 않을 수 있으며, NLP 데이터 확장의 효과가 애매 할 수 있다.
이 연구에서는 태스크에 구애받지 않는 데이터 확장을 위한 휴리스틱한 방법을 제시한다. 데이터 셋의 기존 문장을 청사진으로 사용하고, 휴리스틱한 방법을 적용해서 변경한다. 이미지 왜곡과 유사한 프로세스를 적용한다. 특히, 다음과 같은 과정을 랜덤하게 수행한다.
Masking. 확률 $p_{mask}$로 단어를 랜덤하게 [MASK]로 교체 하는데, 모델이 알 수 없는 토큰과 BERT의 마스크 된 단어 토큰에 해당한다. 이 규칙으로 레이블에 대한 각 단어의 기여도를 명확하게 한다. 예를들어 “I [MASK] the comedy"에 대해 교사 네트워크는 “I love the comedy"에 비해 신뢰도가 떨어진logits를 도출한다.
POS-guided word replacement. 확률 $p_{pos}$로 단어를 같은 POS 태그의 다른 단어로 교체한다. 기존의 학습 분포를 유지하기 위해, 새로운 단어는 POS 태그로 부터 다시 정규화된 unigram 단어 분포에서 샘플링 된다. 이 규칙으로 각 예제의 의미를 혼동 시킨다. 예를 들어, “what do pigs eat?“와 “How do pigs eats"와 다르다.
n-gram sampling. 확률 $p_{ng}$로 예제의 n-gram을 랜덤하게 샘플링 하는데, n 은 {1,2,…,5}에서 랜덤하게 선택된다. 이 규칙은 예제에서 다른 모든 단어들을 제거하는 것과 컨셉이 동일하다 이 규칙은 마스킹을 더 과격하게 하는 것과 같다.
연구에서 데이터 확장 과정은 다음과 같다. 주어진 학습 예제 {${w_1,…,w_n}$}에서 모든 단어 들에 대해 반복하는데,
- $x_i$~UNIFORM[0,1] 분포를 사용해서 각 단어 $w_i$를 추출한다.
- 만약 $X_i < P_{mask}$면, $w_i$에 마스킹을 적용한다.
- 만약 $p_{mask} ≤ x_i < p_{mask} + p_{pos}$ 라면, POS-guided를 적용한다.
- 확률 $p_{ng}$로 n-gram 샘플링을 전체 합성 예제에 대해 적용한다.
- 마지막 합성 예제는 라벨링 되지 않은 확장된 데이터셋에 추가한다.
마스킹과 POS-guided 교체를 상호 배타적으로 다룬다. 한 규칙이 적용되면 다른 규칙은 고려되지 않는다.
문장이 하나인 데이터 샘플
- $n_{iter}$ 번 과정을 진행해서 $n_{iter}$ 개의 샘플을 생성하고 중복은 제거한다.
문장이 쌍인 데이터 샘플
- 앞의 문장에만 적용, 뒷 문장에만 적용, 두 문장에 모두 적용한다.
4 Experimental Setup
$BERT_{LARGE}$를 교사 모델로 사용했다. 네개의 모델로 Adam 옵티마이저에 학습율 {2, 3, 4, 5} $\times 10^{-5}$을 사용해서 파인튜닝 했고, 가장 좋은 모델을 선택해서 검증 셋으로 사용했다. 파인튜닝 중의 데이터 확장은 하지 않았다. 네개의 모델에 원본 데이터와 태스크 전용 변형 데이터셋을 함께 피딩했으며, 예측된 logits을 얻을 수 있도록 BERT 모델을 파인튜닝 했다고 한다. 소프트 로짓 타겟으로 증류된 BiLSTM은 $BiLSTM_{SOFT}$라고 하고, $\alpha = 0$으로 하는 것에 해당한다고 한다. 증류 목적 함수만 사용하는 것이 가장 좋았다고 한다.
4.1 Datasets
실험은 GLUE(General Language Understanding Evaluation) 벤치마크로 수행했다. GLUE는 여섯개의 자연어 이해 태스크로 단일 문장 태스크, 유사도, 페러프레이즈, 그리고 추론 태스크로 분류된다. 시간과 리소스 제한으로 가장 많이 사용되는 데이터를 사용했다고 한다.
SST-2. Stanford Sentiment Treebank 2는 영화 리뷰와 이진 감정 분류로 이루어진 데이터 셋이다. GLUE와 같이, 문장 단위 감정만 고려했다고 한다.
MNLI. Multi-genre Natural Language Inference는 거대한 규모의 함의 분류 데이터셋이다. 한 쌍의 문장의 관계 예측이 목적이다. MNLI-m은 학습 셋의 동일한 장르를 포함하는 개발과 테스트 셋을 사용하는 반면, MNLI-mm은 나머지 일치하지 않는 장르의 개발과 테스트 셋을 나타낸다.
QQP. Quora Question Pairs는 Quora에서 수집된 잠재적으로 중복인 질문 쌍으로 구성되고, 라벨은 중복을 이진으로 표현한 것이다.
4.2 Hyperparameters
검증 셋의 성능에 따라 BiLSTM에 히든 유닛 수를 150이나 300을 선택하고, Relu 히든 레이어의 유닛 수를 200이나 400을 선택했다. word2vec은 기존의 300 차원을 사용하고 구글 뉴스와 멀티 채널 임베딩을 사용해서 학습한다. 최적화를 위해, AdaDelta를 기본 학습율인 1.0과 $p=0.95$로 사용한다. SST-2는 50 배치사이즈를 사용하고 MNLI와 QQP는 사이즈가 커서 배치 사이즈를 256을 사용했다.
데이터셋 확장에서 사용하는 하이퍼파라미터로, $p_{mask} = p_{pos} = 0.1$ 그리고 $p_{ng} = 0.25$로 모든 데이터셋에 대해 적용한다. 모든 데이터셋을 사용해서 하이퍼파라미터 튜닝을 하지는 않았고 첫번째 값으로 선택한 것이라고 한다. SST-2로 $n_{iter}$를 선택하고, 데이터셋이 큰 MNLI와 QQP는 $n_{iter} = 10$를 사용했다.
4.3 Baseline Models
BERT는 멀티 레이어인 양방향 트랜스포머 인코더다. $BERT_{BASE}$와 $BERT_{LARGE}$가 있다. $BERT_{BASE}$는 12개 레이어와 768 히든 유닛, 셀프 어텐션 12개로 110M 파라미터를 가진다. $BERT_{LARGE}$는 24개 레이어, 1024 히든 유닛, 셀프 어텐션 16개로 340M 파라미터를 가진다.
OpenAI GPT는 BERT와 유사하지만, 단방향이고 각 타임스탬프에서 이전 context 만 사용했다.
GLUE ELMO baselines. GLUE 논문에 나온 모델은 BiLSTM 기반 모델로 ELMO를 기반으로 학습되고 모든 태스크에 대해서 공동으로 파인튜닝 된 모델이다. ELMo BiLSTM내의 4096개 유닛을 포함하고 파라미터 수가 9천 3백만 파라미터가 넘는다. BERT 논문에서 같은 모델이 나오는데 결과가 기존 논문과 좀 달랐다. 이것도 함께 리포트 되었다.
5 Result and Discussion
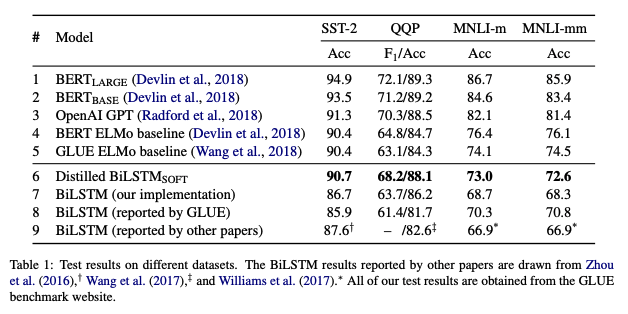
모델들의 결과는 테이블 1에 나타난다. QQP에서는 데이터셋이 대부분 라벨링 되지 않은 데이터셋이기 때문에, F1과 정확도를 리포트 했다. GLUE에서는 데이터셋에 대한 각 모델의 평균 점수를 리포트 했다.
6
5.1 Model Quality
테이블 1의 일곱번째 행은 기존 라벨로 BiLSTM 모델을 학습한 것으로 증류 과정은 없었다. 세 데이터셋 모두에서 행 8-9에 해당하는 이전 연구와 비교할만한 점수를 얻었고, 논문의 구현이 공정하다는 것을 보였다. MNLI에서는 두 베이스라인(행 8, 9)이 4% 정확도 차가 있다. 증류하지 않은 BiLSTM 베이스라인 들은 행 4에 해당하는 BERT ELMO 베이스라인 보다 좋지 않았지만, QQP에서는 더 높은 정확도는 보였지만, $F_1$ 점수가 낮다.
확장 학습 데이터셋을 사용해서 logits을 매칭하는 본 논문의 증류 방법을 적용해서, BiLSTM 베이스에 비해 1.5-4.5점이 개선 되었다. SST-2와 QQP에서의 성능은 행 4의 ELMo 모델을 능가했고, GPT에 거의 근접했다. MNLI에서는 ELMo에 조금 뒤쳐졌다. 그러나 BiLSTM에 대해 4.5 점 개선이 있었고, 행 8의 이전에 최고 였던 BiLSTM에 비해선 1.8-2.7점이 개선되었다. 전반적으로 증류 모델은 행 4-5인 이전의 ELMo BiLSTM에 비해 경쟁력이 있고, 이전에 평가 보다 작은 BiLSTM의 표현력이 높았다는 것을 제시한다.
그러나 행 1-3인 트랜스포머보다 성능이 낮았고, 평균적으로 4-7점 낮았다. 그렇지만 효율성 측면에서 더 높고 파라미터수가 확실히 더 작다.
5.2 Inference Efficiency
추론 속도와 파라미터 분석으로 파이토치로 구현한 BERT와 ELMo를 사용했다. NVIDIA V100 GPU 한장에서, SST-2 학습 셋의 모든 67350 문장에 대해 배치 512으로 모델 추론을 한다. 테이블 2에 보이듯이, ELMo에 비해 98배와 $BERT_{LARGE}$에 비해 349배 적은 파라미터를 사용한다. 상대적으로 15배와 434배 빠르다. 2.2백만 파라미터에서, 300 차원의 LSTM 유닛이 두배 크지만, ELMo 보다는 작다. 문장 쌍 태스크에서는, 이전의 SOTA와는 다르게 샴 구조에서 쌍 단위 단어 상호 작용 작업을 하지 않는다. 그래서 런타임이 문장 길이에 따라 선형적으로 늘어난다.
7
6 Conclusion and Future Work
본 논문에서는 BERT에서 간단한 BiLSTM 모델로 증류하는 것을 연구했다. 증류 모델은 ELMo에 비해 파라미터수가 훨씬 작고, 추론 시간이 더 짧지만 비교가능한 결과를 달성했다. 본 눈문의 결과는 작은 BiLSTM이 이전에 평가되었던 것보다 자연어 작업에 더 표현력이 높다는 것을 의미한다.
이후 연구 방향 중 하나는 CNN과 같이 극도로 단순한 아키텍처를 탐색하고, SVM과 로직스틱 회귀를 지원하는 것이다. 또 다른 연구 방향은 pairwise 단어 상호 작용과 어텐션 같은 트릭을 사용해서 더 복잡한 구조를 탐색하는 것이다.