ELMO : Deep contextualized word representations 리뷰
ELMO : Deep contextualized word representations 논문 리뷰
정리
ELMO의 특징
- 레이블 작업을할 필요가 없다.
- 문장을 바로 입력에 사용한다.
- 양방향 LM 구조를 가진다.
- 모든 레이어들의 출력값을 사용해서 임베딩을 출력한다.
구성요소
- Character 단위 CNN
- 양방향 LSTM 레이어
- ELMO 레이어 ( CNN의 출력과 LSTM 두개 출력, 세개 벡터를 가중합하는 방식으로 학습한 결과를 최종적인 벡터 표현 )
Abstract
(1) 단어의 복잡한 특징 (예를 들어, 구문과 의미 )
(2) 언어적 맥락에 따른 다양한 표현 ( 다형성 )
모델링 한 새로운 타입의 단어 표현인 deep contextualized word 표현을 소개한다. 단어 벡터는 거대한 말뭉치로 사전 학습된 언어 모델(biLM)의 내부 상태에 대한 학습된 함수이다. 논문에서는 이러한 표현들이 기존 모델에 쉽게 추가될 수 있음을 보였고, NLP 문제에서 질의응답, 감정 분석 그리고 텍스트 함의를 포함한 6개의 과제에서 SOTA를 했다는 것을 보였다. 또한 논문에서는 사전 학습된 네트워크의 내부를 노출하는 것이 중요하고, 다운스트림 모델이 다른 유형의 semi -supervision 신호들을 섞을 수 있게 허용한다 는 분석 결과를 제시했다.
1. Introduction
사전 학습된 단어 표현들은 많은 언어 이해 모델에서 중요한 컴포넌트다. 그러나 성능을 올리는 것은 챌린징하다. 이상적으로 Abstract의 (1),(2)의 두 부분을 모델링 해야한다. 이 논문에서는 두 부분을 직접적으로 해결한 새로운 유형의 deep contextualized 단어 표현을 소개하는데, 기존 모델과 쉽게 결합할 수 있고 모든 종류의 언어 이해 문제에서도 SOTA를 달성했다.
논문의 단어 임베딩은 각 토큰이 전체 입력 문장을 입력으로 하는 단어 표현 함수로 할당되는 표현으로 각 토큰이 한 표현으로만 할당되는 기존의 방식과는 차이가 있다. 양방향 LSTM 모델의 벡터를 사용하는데, 이 모델은 거대한 말뭉치에 대해 두개의 언어 모델의 목적 함수를 함께 사용해서 학습 한다. 이러한 이유로 ELMO(Embeddings from Language Model) 표현이라고 한다. contextualized(문맥적) 단어 벡터를 학습하기 위한 이전 접근법과 다르게, ELMO는 biLM의 모든 내부 레이어 함수라는 점에서 deep 하다고 할 수 있다. 좀 더 구체적으로, 논문에서는 각 태스크들에 대해 각 입력으로 만든 벡터의 선형 결합을 학습해서, 마지막 LSTM 레이어를 사용하는 것에 비해 성능을 많이 향상 시킨다.
이러한 방식으로 레이어의 내부 state 들을 결합하는 것은 굉장히 풍부한 단어 표현을 하게 만든다. Intrinsic Evaluation을 사용해서, 상단의 LSTM의 state들은 context에 의존적인 단어 의미를 캡처하고(예를들어, 변경 없이도 동음이의어 같은 태스크에서 사용할 수 있다 ), 아래의 CNN state는 모델의 구문을 캡처하는 것을 보였다( 스피치 태깅 태스크에서 사용할 수 있다 ). 이 모든 신호를 동시에 사용하는 것이 매우 유익한데, 학습된 모델에서 각 다운스트림 태스크에 가장 유용한 반 감독 형태로 사용 할 수 있다.
논문은 ELMO 표현들이 실제에서 굉장히 잘 동작하는 것을 다양한 실험으로 증명했다. 여섯 가지의 다양하고 챌린징한 언어 이해 문제(언어 함의, 질의응답 그리고 감정 분석)를 위한 기존 모델 들에도 쉽게 추가되었다. ELMO의 추가로 모든 케이스에서 상대적으로 최대 20%의 오류 감소 효과로 SOTA를 향상 시켰다. 직접 비교가 가능한 태스크의 경우에는, ELMO는 NMT의 인코더를 사용해서 contextualize한 표현들을 계산한 CoVE에 비해 뛰어난 성능을 보였다. 마지막으로, ELMO와 CoVE의 분석 결과가 LSTM의 최상단 레이어에서 도출된 것보다 월등한 성능을 보인다는 것을 알려준다. 학습된 모델과 코드 들은 공개 되어 있고, ELMO가 많은 다른 NLP 문제에 대해서도 유사한 이득을 제공할 것으로 기대한다.
2. Related work
거대한 스케일의 라벨링 되지 않은 텍스트로 단어들의 구문과 의미적 정보를 캡처하는 능력으로 인해 사전 학습된 단어 벡터 들은 text-entailment와 semantic role labeling을 포함한 대다수의 SOTA NLP 구조에서 표준 컴포넌트이다. 그러나 이런 단어 벡터 들을 학습하기 위한 접근법은 각 단어에 대해 context과는 독립적인 하나의 표현 만을 허용한다.
이전에 제시된 방식들은 sub-word 정보로 단어 벡터를 풍부하게 하거나 각 단어 센스에 대해 분리된 벡터를 학습 함으로 전통적인 단어 벡터 들의 단점을 극복했다. 이 논문의 접근법은 서브 단어 유닛에 character 단위에 컨볼루션을 사용하는데 그 부분에서 장점이 있고, 미리 정의된 클래스를 예측하는 명시적인 훈련 없이 단어의 다중 정보를 다운스트림 태스크에 문제없이 통합한다.
최근의 유사한 다른 연구는 context에 의존적인 표현을 학습하는 것에 집중 했다. context2vec은 양방향 LSTM을 사용해서 피봇 단어 주변의 context를 인코딩했다. contextual 임베딩 학습을 위한 다른 연구는 피봇 단어 자체를 표현에 포함하며 NMT 또는 비지도 언어 모델의 인코더를 사용한다. 이런 방법은 큰 데이터 셋일 때 강점이 있다. MT를 사용한 방법은 병렬 말뭉치의 크기 제한을 받기는 한다. ELMO는 풍부한 단일 언어 데이터에 대한 방법을 최대한 활용해서 거의 3천만 개 문장으로 biLM 모델을 학습한다. deep contextual 표현으로 단어 표현을 일반화해서 다양한 범위의 NLP 태스크들에서도 잘 동작하도록 했다.
또한 이전 연구에서 biRNN 의 서로 다른 계층은 서로 다른 종류의 정보를 인코딩 한다는 것을 보였다. 예를 들어, dependency parsing 이나 CCG super tagging과 같은 멀티 태스크 syntactic supervision 에서 아래의 LSTM은 더 상단의 태스크의 수준을 올렸다. Belinkov et al은 두 개의 레이어를 가지는 LSTM 인코더의 첫번째 레이어에서 학습된 표현은 두번째 LSTM 레이어 보다 POS 태깅을 더 잘 하는 것을 보였다. 마지막으로 단어 context를 인코딩 하기 위한 LSTM의 최상단 레이어가 단어의 의미 표현들을 학습하는 것으로 나타났다. 유사한 신호가 또한 ELMO의 표현의 수정된 언어 목적 함수에 의해 유도된다는 것을 보이는데, 서로 다른 종류의 semi-supervision을 합치는 다운 스트림 태스크 모델을 학습하는데 도움을 주는 것을 보였다.
Dai and LE (2015) and Raamchandran et al (2017)은 인코더-디코더 쌍을 언어 모델과 시퀀스 오토인코더와 태스크에 특정 supervision을 사용해서 보존했다. 반대로 ELMO의 경우 biLM을 라벨링 되지 않은 데이터로 사전 학습한 후에, 가중치를 수정하고 태스크 별 모델을 추가해서 다운스트림 학습 데이터의 크기가 더 작은 supervised 모델을 사용하는 경우에 대해 더 풍부하고 일반적인 biLM 표현을 활용할 수있다.
3. ELMO: Embeddings from Language Models
많이 사용하고 있는 단어 임베딩과 다르게, ELMO 단어 표현들은 입력을 문장으로 받는 함수의 결과다. biLM의 상위 두 레이어와 character CNN 들을 내부 네트워크 state 들의 선형 함수로 계산했다. 이 환경이 semi-supervised 학습을 할 수 있게 해서, biLM은 대규모로 사전 학습되고 광범위한 기존 NLP 아키텍처에 쉽게 통합된다.
3.1 Bidirectional language models
주어진 N 개의 토큰들의 시퀀스( $t_1, t_2, …, t_N$ )로, 전방향 언어 모델은 주어진 히스토리($t_1, …, t_{k-1}$)에서 토큰 $t_k$의 확률을 모델링 해서 시퀀스의 확률을 계산한다
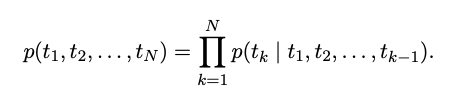
1
최근의 SOTA 언어 모델들은 context에 의존적인 토큰 표현 $x_k^{LM}$ 을 (토큰 임베딩이나 character 에 CNN을 사용해서)계산한다. 그리고 forward LSTM의 L 레이어로 보낸다. 각 위치 k에서, 각 LSTM의 레이어는 j = 1, …, L일 때 context에 의존적인 표현인 ${\overrightarrow{h}^{LM}{k,j}}$ 을 출력한다. LSTM의 최상단 레이어의 출력, ${\overrightarrow{h}^{LM}{k,L}}$ 은 소프트 맥스 레이어를 사용해서 다음 토큰 $t_{k+1}$을 예측하는데 사용한다.
backward LM은 forward LM과 유사한데, 역순으로 진행된다. 주어진 미래 context에서 이전 토큰을 예측한다.
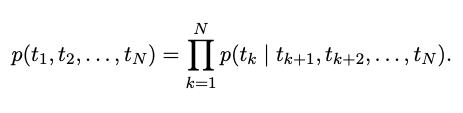
2
모델의 L 레이어에서 backward LSTM의 각 레이어 j가 주어진 ( $t_{k+1}, …, t_N$ )에서 표현 ${\overleftarrow{h}^{LM}_{k,j}}$을 forward LM과 유사한 방식으로 구현될 수 있다.
biLM은 forward와 backward LM을 결합했다. 전방향 후방향으로 log likelihood를 공식으로 함께 최대화 한다.
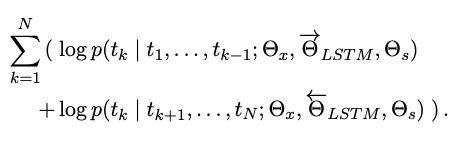
3
양방향에 있는 토큰에 대한 표현과 소프트맥스 레이어의 파라미터를 각 방향의 LSTM에 대한 파라미터를 따로 유지하면서 연결한다. 전반적으로 이 공식은 Peters et al (2017) 의 접근법과 유사한데 완벽하게 독립된 파라미터가 아닌 방향 끼리 공유하는 가중치도 있다.
3.2 ELMO
ELMO는 biLM에서 중간 계층 표현의 태스크 별 조합이다. 각 토큰 $t_k$에 대해서, L개의 레이어를 가지는 biLM은 2L+1개의 표현 셋을 계산한다.
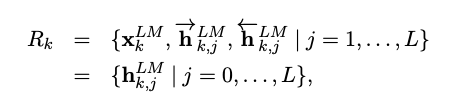
4
${{h}^{LM}{k,0}}$은 토큰 레이어고 각 biLSTM 레이어에 대해 ${h^{LM}{k,j}} = [ {\overrightarrow{h}^{LM}{k,j}};{\overleftarrow{h}^{LM}{k,j}}]$ 다.
다운스트림 모델에 추가하기 위해, ELMO는 R의 모든 레이어를 하나의 벡터로 만들고, $ELMO_k = E(R_k; \theta_e)$ 다. 가장 간단한 케이스에서, ELMO는 최상단의 레이어 $E(R_k) = {{h}^{LM}_{k,L}}$를 TagLM 과 CoVe에서 선택한다. 일반적으로, 모든 biLM 레이어의 태스크 별로 레이어의 결과를 결합하는 가중치를 계산한다.
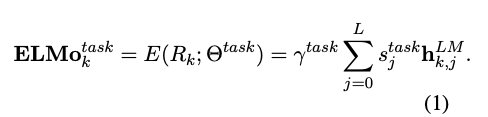
5
식 (1) 에서, $s^{task}$는 일반화된 소프트맥스 가중치이고 스칼라 파라미터 $\gamma^{task}$는 전체 ELMO 결과 벡터를 스케일링 한다. $\gamma$는 최적화 프로세스를 지원하기 위해 실질적으로 중요하다. $\gamma$도 파인튜닝 과정에서 학습되는 파라미터이다. 각각의 biLM 레이어의 활성화가 다른 분포를 가지고 있다는 점을 고려해서, weighting 전에 각각의 biLM의 레이어에 layer normalization을 적용하는 것이 도움이 되는 경우도 있다.
3.3 Using biLMs for supervised NLP tasks
주어진 사전 학습된 biLM과 타겟 NLP 태스크를 위한 supervised 구조에서, 태스크 모델의 성능 개선을 위한 biLM의 사용은 간단하다. biLM을 쉽게 실행할 수 있고 각 단어에 대해 모든 레이어의 표현을 저장한다. 그리고 다운 태스크 모델에 이러한 표현들의 선형 결합을 학습한다.
우선 biLM이 없는 supervised 모델의 가장 아래 레이어를 고려한다. 대부분의 supervised NLP모델은 가장 아래 레이어들의 공통된 구조를 공유하고, 거기에 ELMO를 더한다. 주어진 토큰 시퀀스 ( $t_1, … t_N$ ) 에서, 각 토큰 위치에 대해 사전 학습된 단어 임베딩과 선택적으로 character에 기반한 표현을 사용해서 context 에 독립적인 토큰 표현 $x_k$을 형성하는 방법은 표준이다. 그러면 모델은 context에 영향을 받는 표현 $h_k$를 형성한다. 일반적으로 bi-directional RNN, CNN 이나 FFN을 사용한다.
supervised 모델에 ELMO를 추가하기 위해서, 우리는 biLM의 가중치를 고정하고 ELMO 벡터 $ELMO_k^{task}$와 $x_k$를 합친 뒤, 태스크 RNN으로 ELMO 로 강화된 표현 $[x_k;ELMO_k^{task}]$을 전달한다. 몇 가지 태스크( 예 들어, SNLI, SQuAD )에 대해, $h_k$를 $[h_k;ELMO_k^{task}]$로 바꾸고 다른 출력 별 선형 가중치 셋을 도입해서 태스크 RNN의 출력에 ELMO를 추가함으로써 추가적인 성능 개선을 관찰한다. supervised 모델의 나머지 부분은 변하지 않고 그대로 남아있기 때문에, 이런 추가는 더 복잡한 모델의 context 내에서 발생할 수 있다. 예를 들어, SNLI의 실험에서 biLSTM이 다음에 bi-attention 레이어가 나오는데, biLSTM 최상단의 클러스터링 모델이 레이어화된 coreference resolution 실험이다.
마지막으로, ELMO에 dropout을 추가해서 개선하는지 보는 경우도 있었고, ELMO의 loss에 $\lambda||w||_2^2$를 추가해서 가중치를 정규화 했다. 정규화는 모든 biLM 레이어의 평균에 도달하기 위해 ELMO 가중치에 inductive bias을 부과한다.
3.4 Pre-trained bidirectional language model architecture
이 논문의 사전 학습된 biLM의 구조는 Jozefowicz et al. (2016)과 Kim et al. (2015)과 유사하다. 그러나 양 방향의 joint 학습과 LSTM 레이어 간 residual connection을 지원하기 위해서 수정되었다. Peter et al. (2017) 처럼 거대한 스케일의 biLM으로 집중했다. forward 만하는 LM과 거대한 스케일의 학습보다 biLM 사용의 중요성을 강조하였다.
순수하게 character 기반의 입력 표현을 유지하면서 다운스트림 작업에 대해 모델 크기 및 계산적 요구사항과 언어 모델의 전체적인 난이도의 균형을 맞추기 위해, jozefowicz et al (2016)의 단일 최고 모델 CNN-BIG-LSTM의 모든 임베딩 및 히든 차원을 절반으로 줄였다. 최종 모델은 L=2 biLSTM 레이어를 4096 유닛들과 512 차원 프로젝션 그리고 residual connection을 첫번째에서 두번째 레이어에 사용했다. context에 집약적인 타입의 표현은 2048 character n-그램 convolution 필터를 사용한 후 두 개의 highway 레이어와 linear projection을 512 표현으로 사용한다. 그 결과로, biLM은 순수하게 character 입력만으로 인해 외부 학습 셋을 포함해서 각 입력 토큰에 대해 세 레이어의 표현을 제공한다. 반대로 전통적인 워드 임베딩 메소드들은 고정된 vocabulary에서 토큰들에 대한 한 레이어 만을 제공한다.
1B 단어 벤치마크에 10 epoch의 학습 후에, 평균 forward 와 backward 의 perplexities는 39.7이고, forward CNN-BIG-LSTM은 30.0이다. 일반적으로, forward와 backward의 perplexities는 대략적으로 동일하다, backward가 조금 낮다.
한번 사전학습이 되면, biLM은 어떤 태스크에 대해 표현을 계산할 수 있다. 몇가지 경우에서, biLM에 도메인에 특화된 데이터를 파인튜닝 하는것은 perplexity를 떨어트리고 다운스트림 태스크의 성능을 증가시켰다. 이것은 biLM에 대한 도메인 트랜스퍼의 한 타입으로 볼 수 있다. 그 결과로 대부분의 경우에 다운스트림 태스크에서 파인튜닝한 biLM을 사용했다.
4. Evaluation
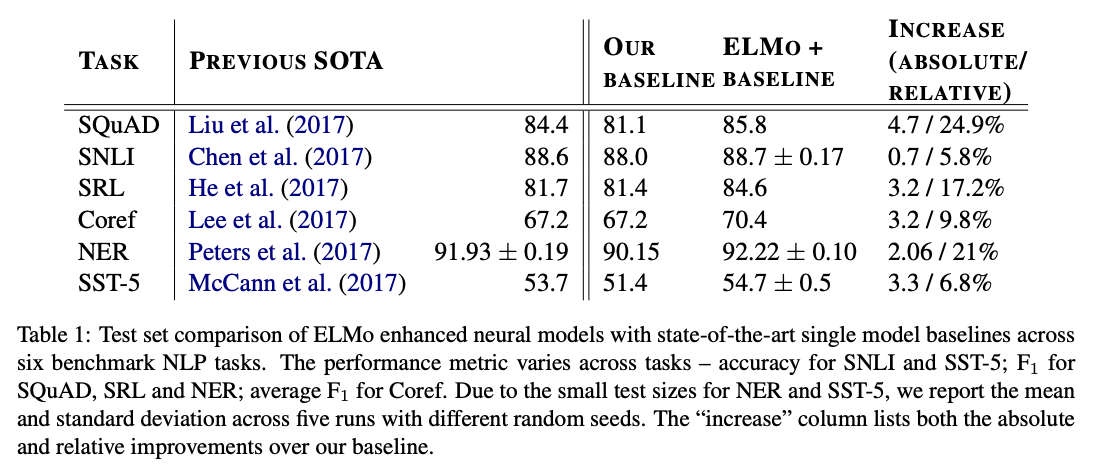
테이블 1은 여섯개의 벤치마크 NLP 태스크에 대한 성능을 보여준다. 모든 태스크를 고려했을 때, 간단하게 ELMO를 추가함으로 새로운 SOTA 결과를 세웠고, 강력한 베이스 모델에 대해 상대적인 에러 감소가 6-20%를 했다. 다양한 셋 모델 아키텍처와 언어 이해 태스크에 걸친 매우 일반적인 결과이다.
Question answering
스탠포드 질의 응답 데이터셋(SQuAD)는 100K+ 이상의 크라우드 소싱한 질문 답변 쌍으로 위키백과 단락에서 얻었다. 베이스 라인 모델은 Bidirectional Attention Flow 모델(BiDAF)의 개선된 버전이다. 모델은 bidirectional attention 컴포넌트 다음에 self-attention 레이어를 추가했고, 풀링 연산을 추가했고 LSTM을 GRU로 대체했다. 베이스 라인 모델에 ELMO를 추가한 후에 테스트 셋 $F_1$의 성능을 4.7% 개선해서 85.8%, 24.9%의 상대적인 에러 감소를 베이스라인 모델에서 개선했다. 그리고 전체적인 SOTA 단일 모델을 1.4% 개선했다. 모든 11 멤버의 앙상블은 리더보드에 제출 시에 $F_1$을 87.4로 올렸다. ELMO를 사용했을 때, 4.7%의 개선으로 CoVe를 추가했을 때 보다 1.8%의 개선을 달성했다.
6
Textual entailment
Textual entailment는 전제가 주어졌을 때 가정이 true 인지 결정하는 태스크다. 스탠포드 자연어 추론(SNLI) 코퍼스로 550K의 가정/전제 쌍으로 주어진다. 베이스라인 모델은 ESIM 시퀀스 모델로, biLSTM을 사용해서 전제와 가정을 인코딩하고, 매트릭스 어텐션 레이어를 추가했고, 로컬 추론 레이어, 또다른 biLSTM 추론 레이어, 그리고 마지막으로 출력 레이어 전에 풀링 연산을 두었다. 전체적으로, ELMO를 ESIM 모델에 추가 했을때 다섯개 랜덤 시드에 대해 0.7%의 평균 정확도를 개선했다. 다섯 멤버 앙상블은 전체적인 정확도를 89.3%로 올렸고, 이전 앙상블 최고 결과인 88.9%를 초과했다.
Semantic role labeling
SRL 시스템은 문장의 술어-인수 구조를 모델링해서, “누가 누구에게 무엇을 했는가"에 대답할 수있도록 만든다. He et al. (2017)이 SRL을 BIO 태깅 문제로 모델링 했고 forward 와 backward를 교차된 8-레이어 biLSTM을 사용했다. 테이블 1에서 보이듯이, 재구현된 SRL 모델에서 ELMO가 추가했을때 $F_1$이 84.6%로 3.2%f를 개선했다. OntoNotes 벤치마크에 새로운 SOTA, 이전 최고 앙상블 결과에서 1.2%를 개선시켰다.
Coreference resolution
Coreference resolution은 동일한 엔티티들을 참조하는 텍스트에서 멘션을 클러스터링 하는 태스크이다. 베이스라인 모델은 Lee et al. (2017)의 end-to-end 스팬 기반 신경망 모델이다. biLSTM과 attention 메커니즘을 사용해서 우선 span 표현을 계산하고 소프트맥스 멘션 랭킹 모델을 적용해서 coreference 체인을 찾았다. CoNLL 2012에서 공유된 태스크의 OntoNotes coreference 어노테이션들을 실험에서 사용했다. ELMO를 추가함으로, 평균 $F_1$을 70.4%로 3.2%를 개선하고, 새로운 SOTA, 앙상블 최고 결과를 $F_1$을 1.6% 향상 했다.
Named entity extraction
CoNLL 2003 NER 태스크는 네가지 다른 엔티티 유형(PER, LOC, ORG, MISC)로 태그가 지정된 로이터 RCV1 코퍼스의 뉴스와이어로 구성된다. 최근의 SOTA 모델에 따라서, 베이스 모델은 사전 학습된 워드 임베딩, character 기반의 CNN 표현, 두 biLSTM 레이어와 conditional random field(CRF) 로스를 사용해서 Collobert et al (2011)과 유사하다. 테이블 1로 보여주길, ELMO가 biLSTM-CRF를 강화 한 버전이 92.22 % $F_1$ 평균을 다섯번에 걸쳐서 달성 했다. 논문의 시스템과 이전 SOTA는 본 논문의 모델은 모든 biLM 레이어들에 가중 평균을 학습하는 것을 허용했다. 모든 레이어를 사용해서 다중 태스크에 대해서 성능을 개선했따.
Sentiment analysis
스탠포드 감정 트리 뱅크의 미세 감정 분류 태스크 (STT-5)는 영화 리뷰로 부터 다섯개 라벨 중 하나를 선택하는 것을 포함한다. 문장이 관용구와 같은 다양한 언어 현상과 모델이 학습하기 어려운 부정과 같은 복잡한 구조를 가진다. 베이스라인 모델은 biattentive classification network(BCN)로 McCann et al. (2017)이 했다. CoVe를 ELMO로 BCN 모델의 결합된 부분을 교체 했을 때 1.0의 정확도 개선을 이루었다.
5. Analysis
5.1 Alternate layer weighting schemes
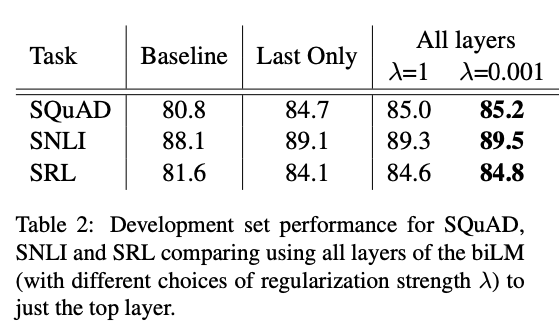
biLM 레이어들을 결합하기 위해 수식 1을 대체 할 수 있는 많은 방법이 있다. 이전 연구에서는 contextual 표현은 마지막 레이어에서만 사용되었다. biLM 이나 MT 인코더(CoVe)든 간에. 정규화 파라미터 $\lambda$의 선택은 중요하다. 람다가 커질 수록 가중치는 레이어에 대한 단순한 평균으로 감소 되지만, 작아질 수록 레이어 가중치를 변화 시킬 수 있다.
7
테이블 2는 이러한 다른 방법들을 SQuAD, SNLI, SRL을 사용해서 비교했다. 모든 레이어의 표현을 포함하면, 마지막 레이어를 사용하는 것보다는 전체적인 성능이 향상되고 마지막 레이어의 contextual 표현을 포함하면 베이스 라인 모델에 비해 성능이 향상된다. 전체적인 추세는 CoVe와 비슷하지만 베이스라인에 비해서는 증가가 적다.
5.2 Where to Include ELMO?
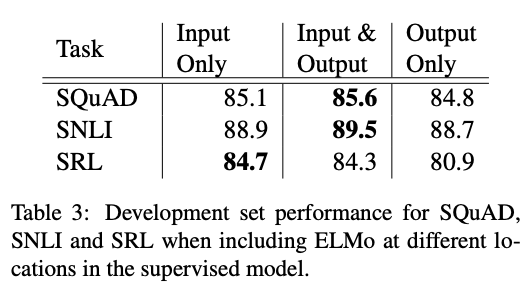
논문에서의 모든 태스크 아키텍처는 가장 하위 레이어의 biRNN에 대한 입력으로만 단어 임베딩을 가진다. 그러나 태스크 별 아키텍처에서 biRNN의 출력에 ELMO를 추가하면 일부 태스크에 대한 전반적인 결과가 향상 된다고 한다.
8
테이블 3은 ELMO를 SNLI와 SQuAD의 입력과 출력 레이어 양쪽에 추가 했고 입력 레이어에 추가 했을 때 보다 성능이 증가했다. SRL에서는 입력에만 추가 했을 때가 가장 좋았다. SNLI과 SQuAD의 경우 biRNN 레이어 이후에 attention을 사용하므로 이 레이어에 ELMO를 추가하면 모델이 biLM의 내부 표현을 직접적으로 사용할 수 있다. SRL에서는 태스크 별 context 표현은 biLM의 context 표현보다 더 주요할 수 있다.
5.3 What information is captured by the biLM’s representations?
ELMO를 추가하면 단어 벡터를 단독으로 사용 할 때 보다 태스크 성능이 향상되기 때문에, biLM의 contextual 표현은 단어 벡터에 캡처되지 않는 일반적으로 NLP 태스크에 유용한 정보를 인코딩 해야 한다. 직관적으로, biLM은 단어의 context를 사용해서 단어들의 의미의 차이를 분명하게 보여준다.
biLM은 소스 문장에서 음성 부분과 단어 센스 모두를 확실히 구분 하게 만들 수 있다.
biLM에 의해 인코딩 된 정보를 구분하기 위해서, 표현들은 세분화된 WSD(중의성 해소) 태스크 및 POS 태그 지정 태스크를 직접적으로 예측하는데 사용된다. 이러한 접근 방법을 사용하면 CoVe와 비교도 가능하며, 각각의 레이어에서도 비교가 가능하다.
Word sense disambiguation
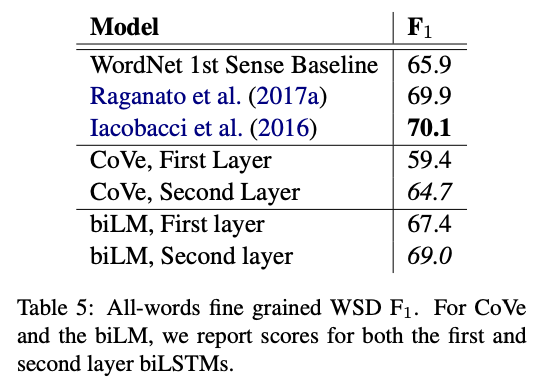
9
테이블 5는 WSD 결과를 Raganato et at (2017b)의 검증 프레임워크를 사용해서 비교한 결과이다. 네 개의 테스트 셋을 사용했다.
POS tagging
biLM의 표현은 CoVe의 표현보다 WSD와 POS 태깅에서 트랜스퍼가 더 쉽고 더 좋다는 거다. 그렇기 때문에 다운스트림 태스크에서도 CoVe 보다 성능이 좋은 이유가 설명이 가능해진다.
5.4 Sample efficiency
모델에 ELMO를 추가하면 SOTA에 도달하기 위한 파라미터 업데이트 수와 전체 학습 셋 사이즈 측면에서 샘플 효율성이 크게 향상된다. ELMO로 강화한 모델은 ELMO가 없는 모델 보다 더 작은 학습 셋을 더 효율적으로 사용한다. ELMO를 사용한 개선점으로 작은 소규모의 학습 셋의 경우 가장 크고 주어진 성능 수준으로 도달하는데 필요한 학습 셋의 양을 크게 줄일 수 있다.
5.6 Contextual vs. sub-word information
biLM의 biLSTM 레이어에서 캡처된 contextual 정보 외에도, ELMO 표현에는 fully character 기반 context 집약 타입 레이어 $x_k^{LM}$에도 sub-단어 정보가 포함되어 있다. 분석을 통해 다운스트림 태스크에서 얻는 대부분의 gain이 sub-word가 아닌 contextual 정보 때문이라는 결론을 내린다.
5.7 Are pre-trained vectors necessary with ELMO?
ELMO에서 추가로 Glove 사용하는 모델이 ELMO 만 사용했을 때에 비해 미미한 개선이 있었다.
6 Conclusion
이 논문에서는 biLM을 사용해서 고품질의 Context에 의존적인 표현을 학습하기 위한 일반적인 접근법을 소개했고, 광범위의 NLP 태스크에 ELMO를 적용할 때 큰 성능 향상을 할 수 있다는 점을 보였다. 여러가지 실험으로 BiLM 레이어가 context에서 단어에 대한 서로 다른 유형의 구문과 의미 정보를 효율적으로 인코딩하고, 모든 레이어를 사용하면 모든 태스크에 대한 성능을 개선시키는 것을 확인했다.