Kafka : a Distributed Messaging System for Log Processing 리뷰
Kafka : a Distributed Messaging System for Log Processing
ABSTRACT
로그 프로세싱은 인터넷 회사들을 위한 데이터 파이프라인의 중요한 컴포넌트가 되었다. 높은 볼륨의 로그 데이터를 낮은 Latency로 수집 그리고 전송할 목적으로 분산 메시지시스템을 개발 했다. 카프카는 이미 존재하는 로그 집계기 (Log Aggregator)와 메시지 시스템으로 부터 아이디어를 집약했는데, 그래서 온 오프라인과 모두의 메시지 Consumption에 적합했다. 시스템을 확장 가능하고 효율적이게 만들기 위해 파격적 이면서도 실용적인 디자인을 선택했다. 카프카를 프로덕션에서 사용했으며 매일 수백 기가의 새로운 데이터를 처리 했다.
1. Introduction
꽤 큰 인터넷 회사에서는 많은 양의 “로그” 데이터가 생성되는데
- 유저 액티비티 (로그인, 페이지뷰, 클릭, 좋아요, 공유, 댓글, 검색어 )
- 실행 메트릭 ( 서비스 호출 스택, 호출 지연, 에러, 시스템 메트릭 )
을 포함한다. 그리고 사용자 추적 분석, 시스템 사용성, 그리고 다른 메트릭 등에 사용된다. 최근 트렌드는 이러한 것들을 직접적으로 사이트 피처로 사용한다.
- 검색 관련도
- 추천
- 광고 타겟팅 과 리포팅
- 보안 ( 크롤링 이나 스팸 )
- 뉴스피드 피처
등으로 사용한다.
이러한 실시간 로그 데이터 사용으로 데이터 시스템에 새로운 과제들이 생기는데 볼륨이 실제 데이터 보다 크기 때문이다.
예를 들어 추천에서 사용하는 클릭율은 노출된 아이템 대비 클릭된 아이템을 사용한다.
중국 모바일은 전화 기록이 5-8TB 페이스북의 유저 활동 기록은 6TB 정도다 ( 일 )
과거에는 분석을 위해 프로덕션 서버에서 로그 파일을 물리적으로 스크래핑 했었다.
최근에 페이스북(Scribe), 야후(Data Highway), Cloudera(Flume) 에서는 분산 로그 수집기가 설계 되어서 데이터 웨어나 하둡으로 로그 데이터를 수집하고 로드한다. LinkedIn 은 실시간 어플리케이션을 몇 초 이내에 지원해야할 필요가 있었다.
로그 프로세싱을 위한 메시징 시스템인 Kafka
- 기존의 로그 수집기와 메시지 시스템의 장점을 결합했다.
- 분산 구조를 지원하고, 확장 가능, 높은 throuput
- 메시지 시스템과 유사한 API 제공
- application에 실시간 로그 이벤트 consume 지원
2. Relative Work
기존 메시지 시스템들은 비동기적인 데이터 흐름을 처리하는 이벤트 버스로 중요한 역할을 했지만, 로그 처리에서 적합하지 않은 부분이 몇가지 있었다.
-
전송 보장(Delivery Guarantee)은 로그 수집에 필수적이진 않다.
페이지뷰 이벤트 몇개가 없는 것으로 세상 종말하진 않는다.
-
주요 설계 제약 조건에서 이미 Throughput에 집중 하지 않았다.
각 메시지가 full TCP/IP 라운드 트립을 필요로 하지만, Throughput 관점에서는 적합하지 않다.
-
분산 시스템을 지원하지 않는다.
-
데이터의 즉각 소비가 아닌 주기적인 큰 처리를 할 경우에는 성능이 크게 저하된다.
Kafka 출시 몇년 전의 FaceBook(Scribe), Yahoo(data highway), Cloudera(Flume) 은 통합 분산 지원은 하지만, 로그 데이터를 오프라인으로 사용 하기 위해 설계 되었고, 구현 세부 정보를 불필요하게 노출하는 경우가 많았다. 게다가 broker가 consumer 들에게 데이터를 포워딩 하는 “push” 모델을 사용했다.
LinkedIn은 “pull” 모델을 사용해서 각 consumer가 메시지를 consumer가 받아 들일 수 있는 정도로 데이터를 핸들링 하기 전에 넘치지 않도록 받아 갈 수 있도록 한다. pull 모델은 consumer를 rewind(이전으로 되감다)를 쉽게 할 수 있도록 하는데 추후 알아 보게 된다.
Yahoo!에서 새로운 분산 pub/sub 시스템을 개발 했다. “HedWig"라고 하는데 높은 확장성과 사용성 그리고 지속 보장성을 제공하지만, 데이터 저장의 커밋 로그를 저장하는 것을 의도하고 만들어 졌다.
3. Kafka Architecture and Design Principles
카프카의 기본 컨셉에 대해서 다루어 보자면,
- 특정 타입의 메시지 스트림을 topic으로 정의한다.
- producer가 topic으로 메시지를 publish할 수 있다. publish 된 메시지들은 broker 라고 명명된 서버 들로 저장된다.
- consumer는 하나 이상의 topic들을 broker 들로 부터 subscribe 할 수 있고, broker 들로 부터 데이터를 pull 해서 subscribe 된 메시지들을 consume할 수 있다.
메시징은 컨셉적으로는 간단하고, 카프카 API에서도 간단하게 반영할 수 있도록 했다. 간단하게 코드로 보자면, 아래와 같다.
메시지는 바이트 페이로드를 포함하도록 정의되었다. 사용자는 메시지를 자유롭게 인코드 할 수 있다. 효율성을 위해, producer는 메시지들을 하나의 publish request로 보낼 수 있다.
Sample producer code:
producer = new Producer(...);
message = new Message("test message str".getBytes());
set = new MessageSet(message);
producer.send("topic1", set);
topic을 subscribe 하기 위해서는, consumer는 우선 하나 이상의 메시지 스트림을 topic을 위해 생성해야 한다. 해당 topic으로 publish 된 메시지들은 sub-stream 들로 분산된다. 각 메시지 스트림은 iterator 인터페이스를 가지고 있으니, consumer 들은 스트림 내에 모든 메시지에 대해 iterate 해서 메시지 페이로드를 처리하면 된다. 기존 iterator와 다르게 terminate 되지 않으며, 더이상 consume할 메시지가 없으면 블록해서 대기한다. point-to-point 전송 모델을 지원해서 여러개의 consumer를 구성해서 topic 내 모든 메시지들의 복사본을 함께 consume할 수 있다.
Sample consumer code:
streams[] = Consumer.createMessageStreams("topic1", 1)
for ( message: streams[0]) {
bytes = message.payload();
// do something with the byes
}
카프카의 전체 구조는 아래 Figure 1이다. 다중 broker로 구성한다. 로드 밸런싱을 위해 topic은 파티션 들로 나줘지고 broker 각각이 하나 이상의 파티션을 저장한다. producer 들과 consumer 들이 동시에 메시지를 처리할 수 있다.
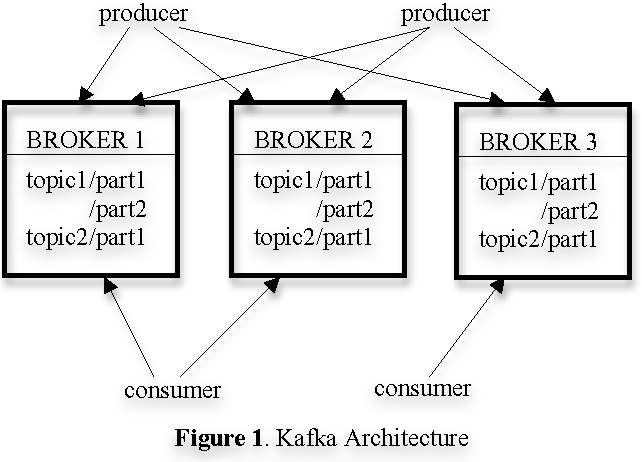
1
3.1 Efficiency on a Single Partition
시스템의 효율성을 위해 결정한 몇가지 들이 있다.
simple storage
카프카는 매우 간단한 저장 공간 구성을 가진다. topic에 할당된 각 파티션은 논리적 로그로 할당된다. 물리적으로, 로그는 같은 크기를 가지는 세그먼트 파일들을 가지도록 구현 되는데, producer 가 매 시간 partition으로 새로운 메시지를 publish 할 때, broker는 마지막 세그먼트 파일로 append 한다. 성능 개선을 위해, 구성 가능한 수 만큼의 메시지들이 publish 되거나 일정 시간이 지나면 디스크의 세그먼트 파일들을 flush 한다. 메시지는 consumer에게 flush 된 이후에 보여진다.
기존 메시지 시스템과 다르게, 카프카 내에 저장되는 메시지는 명시적인 메시지 id가 없다. 대신에 각 메세지는 로그 내 논리적 오프셋으로 할당 된다. 이렇게 해서 메시지 유지에 대한 오버헤드를 피할 수 있고, 실제 메시지 위치를 위해 메시지 id를 매핑하는 검색 집약적인 랜덤 액세스 인덱스 구조를 피할 수 있다. 메시지 id는 증가 하지만 연속이 아니다. 다음 메시지 id를 계산하기 위해서, 현재 메시지의 길이를 해당 메시지 id에 더해야 한다.
consumer는 항상 특정 파티션으로 부터 메시지들을 순차적으로 consume한다. 만약 consumer가 특정 메시지 오프셋을 받는다는 것은 consumer가 파티션 내의 해당 오프셋 이전의 모든 메시지를 모두 받았다는 것을 의미한다. 내부적으로 consumer는 비동기적인 pull 요청을 broker에게 해서, broker가 application에서 consume할 데이터 버퍼를 준비 할 수 있게 한다. 각 pull 요청은 메시지의 오프셋을 담고 있는데 consumption 을 시작할 부분과 받아올 바이트 수를 의미한다. 각 broker는 모든 세그먼트 파일 내의 첫번째 메시지 오프셋과 함께 오프셋들의 리스트를 메모리에 유지하고 있다. broker는 오프셋 리스트를 검색해서 요청된 메시지가 있는 세그먼트 파일을 찾은 다음에 데이터를 consumer에게 보낸다. 카프카 로그에 대한 레이아웃과 메모리 내 인덱스는 Figure 2에 그려져 있는데. 각각의 박스가 메시지의 오프셋이다.
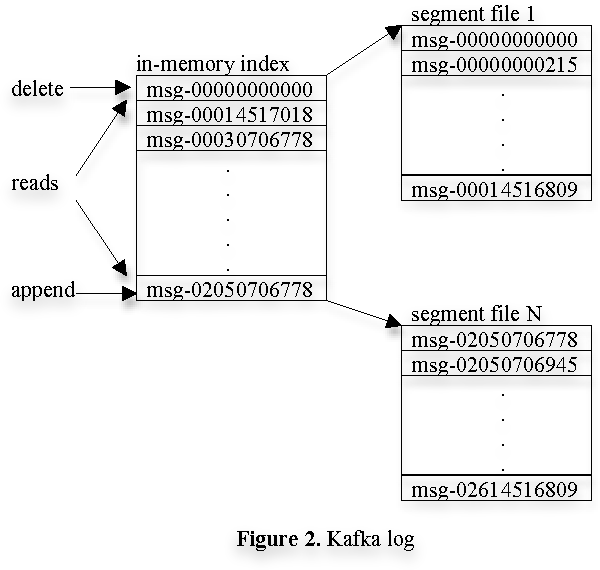
2
Efficient transfer
끝 단의 consumer API가 한 메시지에 대해 iterate 하더라도, 내부적으로 consumer의 각 pull 요청은 다중 메시지를 특정한 크기로 가져온다.
또 다른 선택은 카프카 단에서 메모리 내의 명시적인 캐싱을 회피하는 대신 파일 시스템 페이지에 의존 하도록 하는 것이다. 더블 버퍼링을 회피할 수 있는 이점이 있다. 메시지들은 페이지 캐시 내에만 캐시된다. broker 프로세스가 재시작 했을 때, 웜 캐시를 유지하는 추가 이점이 있다. 카프카가 프로세스 내에서 메시지를 캐시하지 않기 때문에, 메모리의 가비지 컬렉팅을 할 때 오버헤드가 매우 작고, VM 기반의 언어에서 효율적인 구현을 가능하게 한다. 마지막으로 producer와 consumer 둘 모두 세그먼트 파일들을 순차적으로 접근하기 때문에, consumer가 가끔 producer에 비해 처리가 조금 뒤쳐저 있을 때, 일반적인 시스템의 캐싱 휴리스틱이 매우 효과적이다. 데이터 크기에 비례해서 production과 consumption 모두 일관적인 성능을 보인다고 한다.
추가로 consumer를 위한 네트워크 접근을 최적화 했다. 카프카는 멀티 subscriber 시스템이고 메시지는 한 메시지가 다른 consumer 어플리케이션에서 반복적으로 consume 될 수 있을 것이다. 로컬 파일에서 원격 소켓 까지 바이트를 보내는 일반적인 접근법은 다음과 같은 과정을 가진다.
- OS 내에서 스토리지 미디어로 부터 페이지 캐시로 데이터를 읽기
- 페이지 캐시 내 데이터를 버퍼 어플리케이션을 카피
- 어플리케이션 버퍼에서 다른 커널 버퍼로 카피
- 커널 버퍼를 소켓으로 전송
네 개의 데이터 카피 과정과 두 개의 시스템 콜을 가진다. 리눅스와 다른 유닉스 OS에서는, 파일 전송 API가 있고 파일 채널로 부터 소켓 채널로 바이트를 직접 전송한다. 두 개의 카피와 한 시스템 콜을 2번 3번 방법을 일반적으로 회피한다. 카프카는 broker에서 consumer로 파일 전송 API를 활용해서 효율적으로 로그 세그먼트 파일로 바이트를 전송한다.
Stateless broker
대부분의 메시지 시스템과 다르게, 카프카에서는 각 consumer가 consume 한 정보를 유지하지 않는데, consumer가 스스로 유지 해야한다. 이러한 디자인으로 복잡도를 낮추고 broker의 오버헤드를 낮출 수 있었다. 하지만 broker가 모든 subscriber가 메시지를 consume 했는지 알 수 없기 때문에 데이터 제거가 까다로워졌다. 따라서 카프카는 데이터 제거 문제를 해결하기 위해서 데이터 보관 정책으로 간단한 시간 기반의 SLA를 사용했다. 메시지가 broker 내에 특정 기간 이상으로 유지되면 자동으로 제거 되는데, 일반적으로 7일로 지정했다. 이 솔루션은 실제에서 잘 동작했다. 대부분의 consumer에서, 오프라인의 것들도 포함해서, consume을 일, 시간, 실시간 단위로 완료했다. 카프카의 성능은 데이터의 크기가 커지더라도 떨어지지 않으므로 데이터의 장기간 보존이 가능하다.
이 디자인은 카프카의 중요한 특징으로 consumer가 이전 오프셋으로 되감아서 다시 consume 할 수 있다는 장점이 있다. 큐의 일반적인 규칙을 위반하지만, 많은 consumer 에게 필수적인 기능으로 증명되었다.
예를 들어, consumer 로직 내에 에러가 있다면, 어플리케이션은 에러가 수정된 후에 특정 메시지에 대해 다시 진행할 수 있다. 데이터 웨어하우스나 하둡으로 ETL 데이터를 로드 하는 측면에서 굉장히 중요하다. 다른 예로 consume된 데이터는 영구적인 저장소로 주기적으로만 전송(flush) 될 수 있다. 만약 consumer가 크러쉬되면, flush 되지 못한 데이터들은 잃는다. 이러한 경우에, consumer는 체크포인팅을 해서 재시작 한 후 다시 consume 할 수 있다. consumer를 되감는 것은 pull 모델에서 보다 push 모델에서의 지원이 더 쉽다.
3.2 Distributed Coordination
분산 환경에서의 producer 들과 consumer 들이 어떻게 동작하는 지에 대해서 설명한다. 각 producer는 랜덤하게 선택된 파티션 이나 결정된 파티셔닝 키와 파티셔닝 함수로 메시지를 publish 할 수 있다.
카프카에는 consumer groups 라는 개념이 있다. 각 consumer group은 하나 이상의 consumer로 구성되어 subscribed topics 셋을 함께 consume한다. 예를 들면, 메시지가 그룹 내의 consumer 들 중 하나에 보내진다. 서로 다른 consumer group은 각각 독립적으로 subscribe된 메시지들을 consume하고 다른 consumer group에는 별다른 조치가 필요가 없다. 같은 consumer group의 consumer들에서 다른 프로세스들이나 다른 머신이 있을 수 있다. 카프카의 목표는 consumer 단에서도 broker 내의 메시지를 분산해서 저장하는 것이다.
첫번째 결정은 topic내에 병렬 작업이 가능한 가장 작은 단위로 파티션을 만드는 것이다. 주어진 시간에서, 파티션의 모든 메시지가 각 consumer group 내의 단일 consumer에 의해서만 consume 된다. 여러 개의 consumer가 한 partition을 소비하는 것을 허용한다면, 누가 어떤 메시지들을 consume 할 것인지 조정할 필요가 있는데, 이러면 locking과 state 유지 오버헤드가 필요하게 된다. 카프카의 디자인 consuming 프로세스들은 consumer가 로드를 재조정 할 때에만 조정하면 된다. 올바르게 밸런싱된 로드를 위해, 각 consumer group 내의 consumer 보다 더 많은 수의 partition이 필요하게 된다. topic을 partition 하는 것으로 이러한 문제를 해결 했다.
두번째 결정은 중앙에 “master” 노드를 가지지 않고 탈 중앙화 된 방식으로 각 consumer가 스스로 조정하게 했다. 마스터를 추가하면 마스터 failure도 고려 해야 하기 때문에 복잡한 시스템이 될 수 있다. 튜닝을 위해서, Zookeeper를 도입했다. Zookeeper는 매우 간단한 파일 시스템과 유사한 API다. Path를 생성하고, path의 값을 읽고, path를 삭제하고 그리고 path의 자식을 리스트한다. 몇가지 더 흥미로운 점이 있는데
a. path에 watcher를 등록하고 path나 path의 값이 변경 되었을 때 알림을 받을 수 있다.
b. 경로는 영구적이 아닌 “emphemeral"로 생성 될 수 있다. 생성 클라이언트가 사라질 경우, Zookeeper에 의해 경로가 자동으로 제거 된다.
c. zookeeper가 다중 서버로 데이터를 복제할 수 있다, 높은 신뢰성과 사용성을 만든다.
카프카는 Zookeeper를 다음과 같은 태스크로 사용한다.
- broker 들과 consumer 들의 추가와 제거를 감지한다.
- 위의 이벤트가 감지가 되었을 때, 각 consumer에 리밸런싱 프로세스를 트리거한다.
- consume 관계를 유지하고 각 partition의 consume offset을 트래킹한다.
각 broker나 consumer가 스타트업 될 때, Zookeeper 내의 broker나 consumer 레지스트리에 정보를 저장한다. broker 레지스트리는 broker의 호스트네임이나 포트 그리고 topic와 partition 셋의 정보를 저장한다. consumer 레지스트리에는 consumer가 속한 consumer group 과 consumer가 subscribe 하는 topic 셋들이 포함된다. 각 consumer group은 Zookeeper 내의 오너쉽 레지스트리와 오프셋 레지스트와 연계 된다. 오너쉽 레지스트리는 subscribe된 모든 파티션에 대해 path를 가지며 path 값은 이 파티션에서 현재 consume하고 있는 consumer의 id이다. 오프셋 레지스트리는 각각의 subscribe된 파티션에서 마지막으로 사용한 메시지의 오프셋을 저장한다.
Zookeeper 내에 생성되는 path들은 broker 레지스트리에 대해 ephemeral ( 사라질 경우 자동 제거 )하다.
- broker가 fail 하면, broker의 모든 파티션들은 broker 레지스트리에서 자동적으로 제거된다.
- consumer가 fail 하면, consumer 레지스트리 내의 consumer에 대한 엔트리를 잃게되고, 오너쉽 레지스트리에서 가지고 있는 모든 파티션들이 사라지게 된다.
각 consumer는 Zookeeper watcher를 broker 레지스트리와 consumer 레지스트리 둘을 등록한다. broker 셋이나 consumer 그룹에서 변경점이 생길 때마다 알림을 받는다.
consumer가 초기 스타트업 상태나 consumer가 watcher로 부터 broker/consumer 의 변경을 알게 되었을 때, consumer는 consume 해야 할 파티션의 새로운 서브셋을 결정하기 위해 리밸런스 프로세스를 시작한다. 프로세스는 다음과 같다.
알고리즘 1: 그룹 G에 대한 consumer $C_i$에 대한 리밸런스 프로세스
$C_i$가 구독하는 각 topic T에 대해서 {
오너쉽 레지스트리에서 $C_i$ 가 가지고 있는 파티션을 제거
Zookeeper에서 broker와 consumer 레지스트리를 읽는다.
$P_T =$ topic T에 따라 모든 broker에 사용할 수 있는 파티션 / 를 구한다.
$C_T =$ topic T를 subscribe 하는 G의 모든 consumer / 를 구한다.
$P_T$와 $C_T$를 정렬한다.
$C_T$에서의 $C_i$의 인덱스 위치를 j 로 하고 $N = |P_T|/|C_T|$ 으로 $P_T$의 $j*N$ 부터 $(j+1)*N -1$ 까지 파티션을 consumer $C_i$ 로 할당한다.
각 할당된 파티션 p에 대해 {
p의 오너를 $C_i$로 오너쉽 레지스트리에 저장한다.
$O_P =$ 오프셋 레지스트리에 저장된 파티션의 오프셋으로 한다.
파티션 p의 오프셋 $O_P$에서 부터 데이터를 pull 한다.
}
}
consumer가 정기적으로 마지막으로 consume된 오프셋을 오프셋 레지스트리에 업데이트한다.
그룹에 여러 개의 consumer가 있을 때, 각각은 broker와 consumer의 변경이 생길 때마다 알림을 받을 것이다. 그러나 알림은 서로 다른 시간에 올 것이다. 그러면, 한 consumer가 이미 다른 consumer가 소유하고 있는 파티션의 소유권을 가져가려고 할 수 있다. 이러한 경우에, 첫번째 consumer는 현재 소유하고 있는 모든 파티션들을 릴리즈하고, 잠시 대기했다가 리밸런스 프로세스를 재시도한다. 실제로 리밸런스 프로세스는 몇 번의 재시도 만으로도 안정화 된다.
새로운 consumer group이 생성되면, 오프셋 레지스트리에 사용할 수 있는 오프셋이 없다. 이러한 경우에는, broker에서 제공하는 API를 사용해서 consumer들은 사용 가능한 각 subscribe한 파티션에서 가장 작은 사이즈의 가장 큰 오프셋으로 시작한다.
3.3 Delivery Guarantee
일반적으로는 카프카는 at-least-once 전송을 보장한다. 정확하게 한번 전송은 두 단계의 커밋을 필요로 하고 이것은 우리 어플리케이션에서 필요 한건 아니다. 대부분, 메세지는 각 consumer 그룹에 한번 보내진다. 그러나, consumer 프로세스가 깔끔하게 종료되는 것이 아닌 충돌이 난 경우, 실패한 consumer가 소유한 파티션을 넘겨 받는 consumer 프로세스는 마지막 오프셋이 zookeeper에게 성공적으로 커밋 된 후 상태의 중복된 메시지를 받을 수 있다. 어플리케이션이 중복에 대해 고려하게 되면, 스스로 중복에 대한 커밋을 추가해야한다. consumer에게 반환되는 오프셋이나 메시지 내의 고유한 키 같은 것들을 사용 해야 한다. 이런 방법들이 커밋 두 단계로 하는 것 보다 더 비용 효율적일 수 있다.
카프카는 한 파티션에서 consumer로 전송 하는 메시지의 순서를 보장한다. 그러나 서로 다른 파티션으로 부터 받는 메시지 들의 경우는 순서를 보장하지 못한다. 여기서 발생하는 로그 충돌을 피하기 위해서, 카프카는 로그 내 각 메시지의 CRC를 저장한다. broker에 I/O 에러가 있으면, 카프카는 리커버리 프로세스로 서로 다른 CRC들을 가지는 메시지들을 삭제한다. 메시지 단위에서 CRC를 가지는 것은 메시지가 생성되거나 소비된 후의 네트워크 에러를 체크 할 수 있게 한다.
broker가 죽는 경우에, 저장된 메시지 중 consume 되지 못한 메세지는 사용할 수 없게 된다. broker의 저장 시스템이 영구적으로 손상을 입는다면, consume 되지 않은 메시지는 영원히 사라진다. 추후에, 카프카에 replication을 추가해서 각 메시지를 여러 broker를 중복해서 저장할 계획이라고 한다.
4. Kafka Usage at LinkedIn
링크드 인에서 카프카를 어떻게 사용하는지? 그림 3은 배포된 간단한 버전이다. 카프카 클러스터가 사용자 대면 서비스들이 실행되는 각 데이터 센터에 하나가 있다. 프론트 엔드 서비스들은 다양한 로그 데이터를 생성하고 배치로 로컬 카프카 broker로 publish 한다. 각 broker 들이 publish 하는 요청은 하드웨어 로드 밸런서를 사용해서 분산 한다. 카프카의 실시간 consumer는 같은 데이터 센터 내의 서비스를 통해 운영된다.
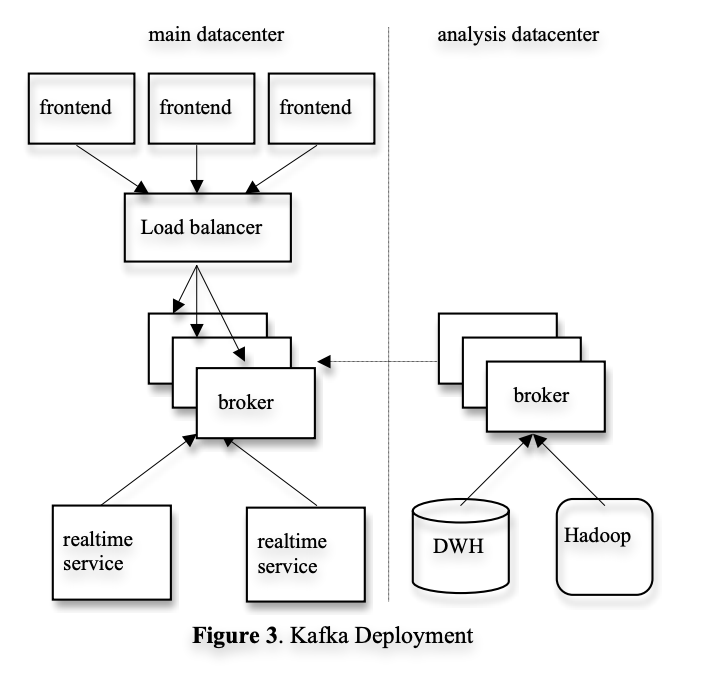
3
오프라인 분석을 위해 분리된 데이터센터로 카프카 클러스터를 배포했다. 하둡 클러스터와 다른 데이터 웨어하우스 인프라와 지리적으로 가까운 곳에 위치한다. 이 카프카는 실시간으로 돌아가고 있는 데이터센터 내의 카프카에서 데이터를 pull하는 임베디드 된 consumer 셋을 운영한다. pull한 데이터를 이 레플리카 카프카에서 하둡과 데이터 웨어하우스로 로드한다. 프로토타이핑을 위해 이 카프카를 사용하고 있으며 raw 한 이벤트 스트림에 대해 ad-hoc 성격의 쿼리를 위한 간단한 스크립트를 실행할 수 있다. 튜닝은 거의 하지 않았고, 완벽한 파이프라인을 위한 end-to-end 지연 시간은 평균적으로 10초로 요구사항에는 충분하다.
현재 카프카는 매일 수백 기가의 데이터와 10억에 가까운 메시지들을 축척하고 있는데, 카프카를 활용하기 위해 레거시 시스템을 변환하는 작업을 완료하면, 규모가 더 증가 할 것으로 예상하고 있다. 더 많은 유형의 메시지들이 미래에는 추가될 것이다. 운영 스탭이 소프트웨어나 하드웨어 유지 보수를 위해 broker를 시작하거나 종료하는 경우에 자동으로 consumer에 리다이렉팅 시키도록 리밸런스 프로세스가 동작되도록 할 수 있다.
트래킹은 전체 데이터 파이프라인에 대한 데이터 로스를 위한 auding 시스템을 포함한다. 그렇기 때문에, 각 메시지는 생성 당시의 타임스탬프와 서버 이름을 포함한다. 각 producer에게 정기적으로 모니터링 이벤트를 생성하도록 지시하며, 모니터링 이벤트는 고정된 타임 윈도우 내에 각 topic에 대해 해당 producer가 publish한 메시지 수를 기록한다. producer는 카프카에 모니터링 이벤트를 별도의 topic으로 publish한다. consumer들은 주어진 topic으로 부터 받은 메시지의 수를 카운트 할 수 있고 모니터링 이벤트와 비교해서 데이터 정합성을 검증 할수 있다.
하둡 클러스터로의 데이터 로딩은 카프카로 부터 데이터를 직접 읽을 수 있게 맵리듀스 작업이 가능한 특별한 카프카 입력 포맷으로 구현해서 데이터를 로드 할 수 있다. 맵리듀스 작업은 raw 데이터를 로드하고 그룹화 하고 압축해서 효율적인 프로세싱을 가능하게 한다. stateless broker와 client-side의 메시지 오프셋의 스토리지가 다시 여기에 적용되어, 맵리듀스 작업( 작업 실패와 재시작 허용)이 작업을 재시작 할 때 메시지를 복제하거나 손실 하지 않고 자연스럽게 데이터를 로드할 수 있다. 데이터와 오프셋은 모든 작업이 성공적으로 완료 될 때만 HDFS에 저장된다
효율적이고 schema evolution을 지원하기 때문에 직렬화 프로토콜로 Avro를 사용한다. 각 메시지 들에서, 페이로드 내 바이트를 직렬화 하고 Avro 스키마 id를 저장한다. 이 스키마가 데이어 producer와 consumer 들 간 호환성을 보장할 수 있다. 경량 스키마 레지스트리 서비스를 사용해서 스키마 ID를 실제 스키마에 매핑한다. consumer가 메시지를 받을 때, 바이트 들을 객체로 복호화 하는데 사용 되는 스키마 레지스트리를 검색해서 스키마를 가져온다. ( 값이 불변이므로, 스키마 당 한번 만 검색한다. )
5. Experimental Result
카프카와 아파치 ActiveMQ v5.4(JMS로 구현한 오픈소스 )와 RabbitMQ v2.4(성능적으로 유명한 메시지 시스템)을 비교 실험 했다. ActiveMQ의 기본 영구 메시지 저장소를 KahaDB를 사용했다. 이 논문에는 없지만, 다른 메시지 저장소로 테스트를 했는데 성능이 비슷했다고 한다. 가능한 가장 최적으로 모든 시스템을 사용했다고 한다.
두 리눅스 머신에서 실험을 진행했는데, 8 2GHZ 코어들과 16GB의 메모리, 6개의 디스크를 가지는 RAID 10으로 구성된 리눅스 머신이다. 두 머신은 1Gb의 네트워크 연결을 가진다. 한 머신은 broker는 다른 머신은 producer나 consumer로 사용되었다.
Producer Test: 모든 시스템의 broker를 비동기적으로 영구 저장소에 메시지를 플러쉬 하도록 구성했다. 각 시스템에서, 한 producer가 총 천만 메시지를 publish하게 했고, 각 메시지는 200 바이트다. 카프카 producer를 1-50 배치 사이즈로 메시지를 보내도록 구성했다. ActiveMQ와 RabbitMQ는 메시지를 배치로 처리하는 간단한 방법이 없었고 배치 사이즈 크기를 1로 사용했다고 가정한다. 그림 4이 그 결과다. x축은 MB로 시간에 따른 메시지 전송량을 표현하고 있고, y축은 초당 메시지 처리량을 표현한다. 평균적으로 카프카는 배치 크기 1-50에 대해 초당 50,000 에서 400,000 메시지들을 publish할 수 있다. ActiveMQ보다 훨씬 높고 RabbitMQ보다 최소 두배가 높은 수치라고 한다.
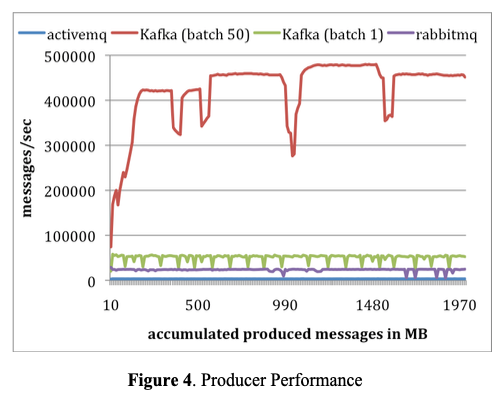
4
카프카 성능이 더 좋은 몇가지 이유가 있다. 첫째로, 카프카 producer는 broker의 acknowledgement 들을 기다리지 않으며 broker가 처리할 수 있는 최대한으로 메시지를 전송한다. 이게 publisher의 처리량을 엄청나게 향상 시켰다. 배치 사이즈 50으로, 싱글 카프카 producer가 거의 producer와 broker 간 1Gb 링크를 거의 포화 상태로 만들었다. 이건 실시간 제공 트래픽에 지연이 발생하지 않도록 비동기 전송을 해야하므로 로그 집계 케이스에 대해 올바른 최적화다. producer의 acknowledge가 없으므로, publish된 모든 메시지가 broker에 도달한다는 보장이 없다. 많은 로그 데이터 타입들 중에서, 상대적으로 삭제된 메시지 수가 적은 처리량에 대한 내구성을 처리하는게 바람직하다. 그러나 앞으로 더 중요한 데이터에 대한 내구성 문제를 해결할 계획이라고 한다.
다음으로 카프카는 더 효율적인 저장 포맷을 가지고 있다. 평균적으로 각 메시지는 카프카에서 9 바이트의 오버헤드를 가지는데 ActiveMQ는 144 바이트이다. 동일한 천만 건의 메시지를 저장하는데 ActiveMQ가 카프카에 비해 70%의 공간을 더 사용한다는 것을 의미한다. ActiveMQ의 오버헤드는 JMS에서 요구하는 메시지 헤더에서 발생하고, 또 다른 오버헤드는 다양한 인덱싱 구조를 유지하는데 발생한다. ActiveMQ에서 가장 바쁜 쓰레드 중 하나가 메시지 메타 데이터와 상태를 유지하기 위해 B-트리에 접근하는데 대부분의 시간을 소비하는 것을 발견 했다고 한다. 마지막으로 배치 처리는 RPC 오버헤드를 분할해서 처리량을 크게 향상 시켰는데, 카프카에서는 50개 배치 사이즈로 처리량이 10배에 가깝게 향상되었다.
Consumer Test: 두번째 실험으로 consumer의 성능을 측정했다. 모든 시스템에 consumer 하나를 사용해서 천만 메시지 전체를 검색했다. 모든 시스템 들을 구성해서, 각 pull 요청이 거의 같은 크기의 데이터( 최대 1000개 메시지나 약 200KB)를 prefetch 하도록 구성했다. ActiveMQ와 RabitMQ에서는 consumer acknowledge 모드를 자동으로 세팅했다. 모든 메시지가 메모리에 맞춰져 있기 때문에, 모든 시스템은 기본 파일 시스템의 페이지 캐시 또는 일부 메모리 내의 버퍼에서 데이터를 서빙했다. 결과는 그림 5에 있다.
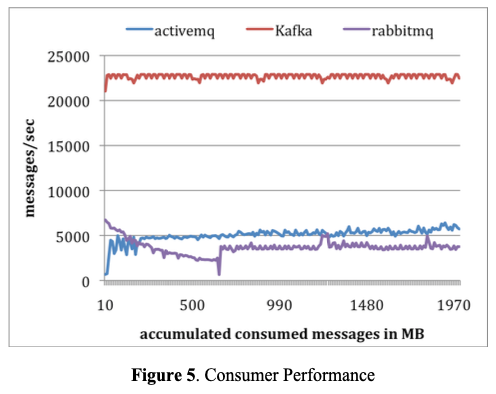
5
평균적으로 카프카는 초당 22,000 메시지를 consume 하는데, ActiveMQ와 RabbitMQ의 4배 이상이다. 몇가지 이유를 들 수 있는데 우선, 카프카는 효율적인 메시지 포맷을 가지고 있기 때문에, broker에서 카프카의 consumer로 더 작은 바이트가 전송된다. 다음으로, ActiveMQ와 RabbitMQ의 broker는 모든 메시지의 전송 상태를 유지한다. 이 테스트로 ActiveMQ의 스레드 중 하나가 KahaDB 페이지를 디스크에 쓰는데 많은 비용이 발생하는 것을 발견했다. 반대로, 카프카 broker에는 디스크에 쓰는 활동이 없다. 마지막으로 파일 전송 API를 사용해서 카프카의 전송 오버헤드를 줄일 수 있다.
ActiveMQ와 RabbitMQ는 사실 카프카 보다 많은 기능을 가지고 있기 때문에 카프카 보다 열등하다는 의미는 아니지만, 잠재적인 성능 향상을 카프카를 사용해서 달성할 수 있다고 한다.
6. Conclusion and Future Works
거대한 양의 로그 데이터 스트림을 처리하기 위한 시스템인 카프카를 본 논문에서 제시했다. 메시지 시스템과 같이, 카프카는 pull 기반의 consumption 모델을 채택해서 어플리케이션이 본인 고유의 비중으로 데이터를 consume 할 수 있게 하고 필요 하다면 rewind 할 수 있게 했다. 로그 프로세싱 어플리케이션에 초점을 맞추어서 카프카는 기존 메시지 시스템에 비해 높은 처리량을 달성했다. 통합 분산 지원과 스케일 아웃을 제공한다. 링크드인의 온-오프라인 어플리케이션에서 사용되고 있다.
앞으로 할 방향성은 다음과 같다. 첫째, 복구 불가능한 시스템 장애가 발생하는 경우에도, 내구성과 데이터 가용성을 보장하기 위해 여러 broker에 메시지의 빌트인 replication을 추가할 계획이다. producer 지연과 보장 강도 사이의 트레이드 오프를 하기 위해서 비동기 및 동기 replication 모델을 모두 지원하려고 한다. 어플리케이션이 내구성, 가용성 그리고 처리량 과 같은 요구 사항에 따라 적절한 수준의 중복을 선택할 수 있다. 둘째, 카프카에 스트림 처리 기능을 추가하고 싶다. 카프카에서 메시지를 검색한 후에, 실시간 어플리케이션은 윈도우 기반 카운팅과 각 메시지를 보조 저장소나 다른 스트림의 메시지와 합칠 수 있는 것과 같은 기능을 수행한다. 최하위 수준에서는 조인 키로 메시지를 의미론적으로 분할하는 것을 지원해서 특정 키로 전송되는 메시지가 같은 파티션으로 이동해서 하나의 consumer 프로세스에 도달하도록 지원한다. 이는 consumer 클러스터에서 분산 스트림을 처리하기 위한 기반을 제공한다. 여기에 유용한 스트림 유틸리티가 있는데 다른 윈도우 기능이나 조인 기술은 이러한 종류의 어플리케이션에 유용하다.