Sentence-BERT : Sentence Embeddings using Siamese BERT-Networks 리뷰
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
1. Introduction
본 논문은 Sentence-BERT에 대해서 소개한다. BERT 를 siamese(둘) triplet(셋) 구조로 변경한 네트워크다. 문장을 의미적으로 잘 표현한 문장 임베딩을 잘 도출 하는 네트워크다. 새로운 BERT 구조로 큰 규모의 의미적 유사도 비교, 클러스터링, 검색 태스크 등에 사용할 수 있다.
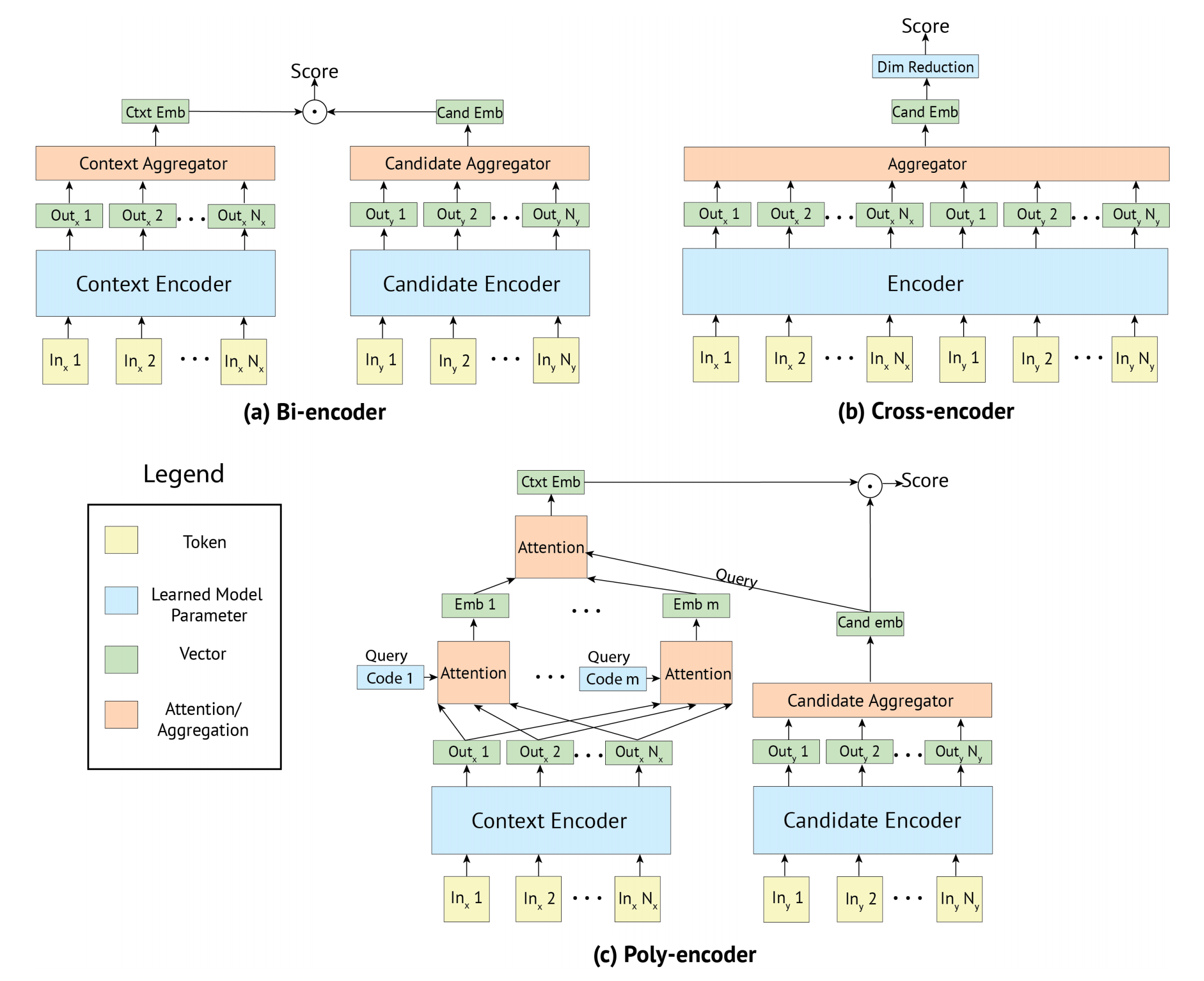
새로운 SOTA를 보였던 BERT는 cross-encoder 구조이다. cross-encoder는 두개의 문장이 트랜스포머 네트워크로 들어가고 타겟 값을 예측한다. context와 candidate를 결합 한 후 인코딩해서 더 풍부한 표현을 얻을 수는 있지만, 입력에 독립적인 토큰을 얻기가 힘들고, 느리다. 그리고 Cross-encoder 구조는 입력이 쌍으로 들어가는 태스크의 경우, 쌍은 조합의 경우의 수가 너무 많기 때문에 적절하지 않다.
예를들어, 10000개의 문장에서 가장 유사한 문장 두개를 찾는 태스크의 경우에는 Cross-Encoder 네트워크에서는 $n \cdot (n-1) / 2 = 49,995,000$ 의 연산이 필요하다. (자기 자신끼리는 빼니까). V100 GPU에서 65시간이 소요된다. 비슷한 사례로, 4천만 개가 넘는 quora 질문 중 새로운 질문과 가장 중요한 질문을 찾는 태스크를 BERT로 pair-wise로 할 경우에 쿼리 하나에 응답 시간이 50시간 넘게 걸린다고 한다.
클러스터링이나 검색 태스크에서는 문장을 의미적으로 유사한 문장 간 거리가 가깝도록 벡터를 만든다. BERT에 문장을 넣어서 고정 길이의 벡터로 뽑아내기도 하지만, 가장 흔하게 사용되는 방법은 BERT 임베딩으로 알려진 BERT의 결과를 평균하거나 첫번째로 출력되는 토큰 [CLS] 토큰을 사용한다. 그렇지만 이러한 방식들은 GloVe 임베딩 평균을 사용 하는 것 보다 나쁘다고 한다.
[CLS] 토큰은 Special Classification Token으로 토큰 시퀀스의 의미를 담고 있게 되는데, Classification Task에서 사용한다고 한다.
이러한 이슈를 해결하기 위해 본 논문에서 SBERT를 개발했다. 샴 네트워크 구조가 입력 문장들에 대해 고정된 길이의 벡터를 도출 할 수 있게 한다. 이렇게 나온 벡터에 cosine 유사도나 manhatten / eucliedean 거리를 계산해서 의미적으로 유사한 문장을 구할 수 있다.
최근 하드웨어는 벡터 연산이 굉장히 효율적으로 계산될 수 있어서, 검색이나 클러스터링에서도 SBERT를 사용 할 수 있다. 10000 문장 중 가장 유사한 문장 쌍을 구하는 태스크는 BERT로 65 시간이 걸렸었는데, SBERT에서 임베딩을 사용하면 5초 내, 코사인 유사도를 사용하면 0.01초 내에 해결할 수 있다. 인덱스를 최적화한 경우, 50시간이 걸리던 유사한 질문 검색 태스크가 수 초 내에도 해결 된다고 한다.
SBERT를 NLI 데이터로 파인튜닝을 했는데, InferSent와 Universal Sentence Encoder 같이 문장 임베딩을 생성해서 SOTA를 찍었다. 일곱 개의 STS 태스크들에 대해서, InferSent에 비해 11.7, Universal Sentence Encoder에서 5.5 점의 점수를 향상했다. 문장 임베딩 검증 툴킷인 SentEval을 사용했을 때 2.1과 2.6 점수를 향상했다.
SBERT는 또 다른 태스크에도 적용될 수 있다. challenging argument similiarity 데이터셋과 위키피디아의 서로 다른 섹션의 문장을 구분하는 triplet 데이터셋에도 SOTA를 했다.
2. Related Work
BERT는 여러개의 NLP 태스크에서 SOTA를 달성한 사전 학습 트랜스포머 네트워크이다. BERT에서는 sentence-pair regression 태스크를 아래와 같이 학습했다.
- BERT의 입력은 [SEP] 토큰을 경계로 두 문장을 결합해서 사용한다.
- 12개(base)나 24개(large)의 레이어에 대해 멀티 헤드 어텐션이 적용되고 출력이 간단한
- regression 함수로 전달되어 최종 라벨을 도출한다.
이 환경으로 기존의 BERT에서도 STS 벤치마크에 새로운 SOTA 달성했었다. 그리고 RoBERTa는 BERT의 성능이 사전 학습 과정을 변경해서 상당한 개선 할 수 있음을 보였다. XLNet에서도 테스트를 해봤는데 BERT 보다 나빴다.
BERT 구조의 큰 단점은 독립적인 문장 임베딩을 계산할 수 없는 것이다. 그래서 문장 임베딩을 도출해내기 어렵다. 기존의 BERT에서 문장 임베딩을 뽑아내는 과정은 아래와 같다.
- [CLS] 와 [SEP] 토큰을 추가
- 입력 채우기 ( padded_token, attention_mask 채우기 )
- 세그먼트 토큰 목록을 유지하기
- BERT 토크나이저에서 Token 을 Token Index로 변경하기
- BERT에 입력해서 결과 생성
추가로 CLS 토큰을 사용해서 고정된 크기의 벡터를 도출해냈다. 이 두가지 방법은 bert-as-service 리포지토리에도 이미 있을 정도로 유명하지만, 실제로 사용할 정도의 성능을 내는지는 검증 되지는 않았다고 한다.

문장 임베딩은 굉장히 잘 연구된 분야로 제시된 메소드가 많다.
- Skip-Thought ( Kiros et al., 2015 ) : 주변 문장을 예측하는 인코더-디코더 구조를 학습한다.
- InferSent ( Conneau et al., 2017 ) : 샴 BiLSTM 네트워크와 출력에 max 풀링을 사용해서 NLI 학습
- Universal Sentence Encoder ( Cer et al., 2018 ) : 트랜스포머 학습과 SNLI 데이터 비지도 학습 확장
- ( Yang et al., 2018 ) : 대화 데이터에 샴 DAN 과 샴 트랜스포머 네트워크를 사용해서 학습
기존의 연구 결과들은 이미 SNLI 데이터셋이 문장 임베딩을 학습하는데 적합하다는 것을 보여줬다.
Humeau et al. (2019)는 cross-encoder의 런타임 오버헤드를 해결하기 위해서 poly-encoder를 제시했다. poly-encoder는 m 개의 context 벡터들과 어텐션을 사용해서 미리 계산한 candidate 임베딩들 사이의 점수를 계산하는 방법이다. 거대한 컬렉션에서 가장 높은 점수를 구하는 태스크에서는 잘 동작하지만, 대칭적이지 않고 클러스터링 태스크의 경우에 계산 오버헤드가 너무 크다는 문제가 있다.
이전의 신경망 기반 문장 임베딩 메소드들은 학습을 랜덤 초기화로 시작했는데, 논문에서는 사전 학습된 BERT 나 RoBERTa 네트워크를 사용하고 문장 임베딩을 도출을 위해 네트워크를 파인튜닝을 한다. SBERT은 20분 내에 파인튜닝이 되고, 기존 문장 임베딩 보다 성능이 좋았다.
3 Model
SBERT는 풀링 과정을 BERT / RoBERTa에 추가해서 고정 길이의 문장 임베딩을 도출했다. 풀링 전략은 세가지가 있다.
- CLS 토큰의 출력
- 모든 출력 벡터의 평균 ( MEAN ) ( 기본 )
- 출력 벡터의 당시 최댓값 ( MAX )
BERT / RoBERTa 파인튜닝 과정으로 BERT를 샴과 triplet 네트워크 구조를 변형해서 가중치를 업데이트한다. 이렇게 생성되는 문장 임베딩에 의미가 포함 되고, 문장 임베딩은 코사인 유사도를 사용해서 비교할 수 있다.
Classification Objective Function
$o = softmax(W_t(u, v, |u-v|))$
- 문장 임베딩 u와 v를 |u-v|와 concatenate( n + n + n = 3n )한다.
- 학습 가능한 가중치인 $W_t \in R^{3n \times k }$를 곱한다. ( n →문장 임베딩의 차원, k → 라벨 수 )
- cross-entropy 로스를 최적화한다.
구조는 그림 1과 같다.
Regression Objective Function
두 문장 임베딩 u와 v 간의 코사인 유사도가 계산된다. MSE 로스가 사용된다. 그림 2와 같다.
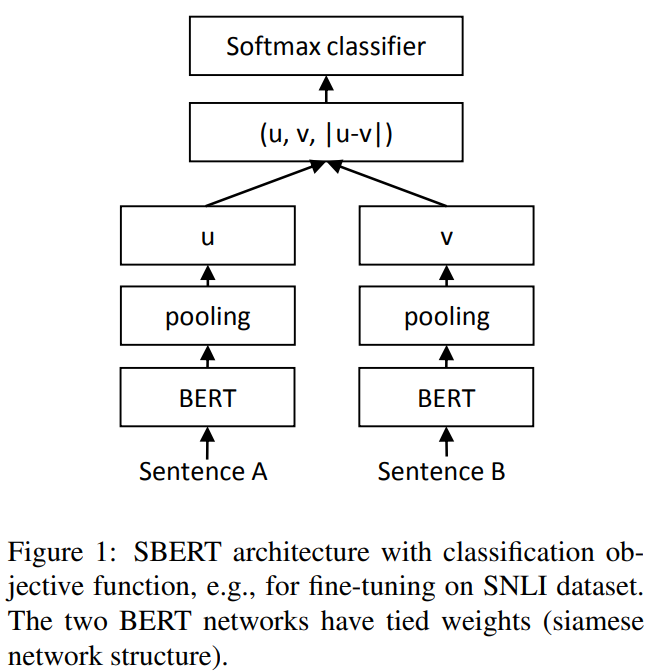
그림 1
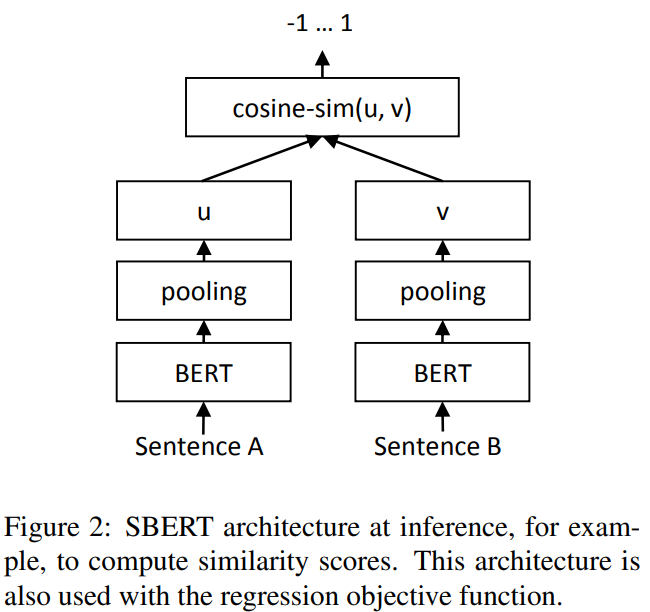
그림 2
Triplet Objective Function
주어진 고정 문장 a, 긍정 문장 p, 부정 문장 n이 있을 때, triplet 로스는 네트워크를 a와 p가 a와 n 보다 가깝게 만든다. 수학적으로 아래의 로스 함수를 최소화 한다.
$max(||(s_a - s_p|| - ||s_a - s_n|| + \epsilon, 0 )$
- $s_x$는 a/n/p에 대한 문장 임베딩
- $||\cdot||$은 거리 측정법이고 $\epsilon$은 마진이다.
마진 만큼 p가 n에 비해 a에 가까운 것을 보장한다. 메트릭에서 유클리디언 거리를 사용하면 $\epsilon$을 1으로 실험에 사용했다.
3.1 Training Details
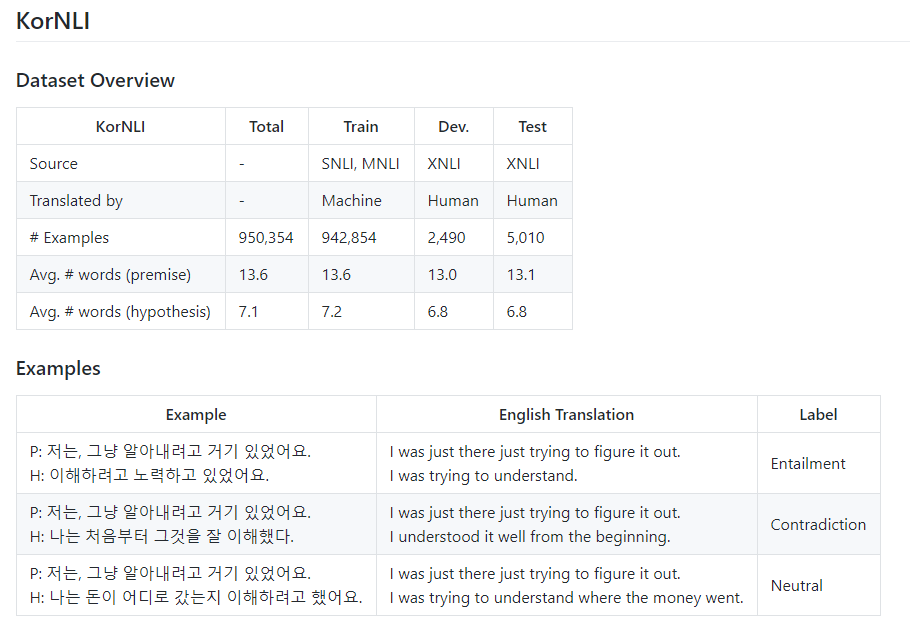
SBERT는 SNLI와 Multi-Genre NLI 두 데이터셋을 사용해서 학습했다.
- SNLI는 570,000 문장 쌍이 라벨과 함께 있는 컬렉션이고 라벨은 모순, 함의, 중립을 가진다.
- MultiNLI는 430,000 문장 쌍이고 발화와 서술된 텍스트 장르를 다룬다.
세가지로 분류하는 소프트 맥스 분류 목적 함수를 사용해서 파인튜닝한다. 배치 사이즈는 16으로 Adam 옵티마이저로 학습율은 2e-5를 사용했다. 그리고 linear learning rate 웜업을 학습 데이터의 10%로 사용했다. 기본 풀링 전략은 MEAN이다.
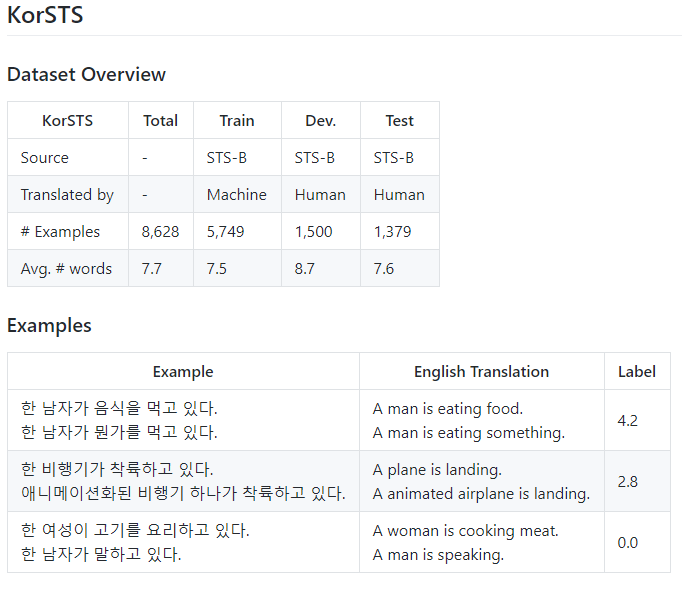
4 Evaluation - Semantic Textual Similarity
STS 태스크에서 SBERT의 성능을 검증했다. 기존 SOTA 였던 메소드들은 회귀 함수를 학습해서 문장 임베딩을 유사도 점수로 매핑 했다. 그러나 함수가 pair-wise로 동작하기 때문에 문장 컬렉션이 특정 크기 이상이 되면 조합이 폭발적으로 증가한다. 그래서 데이터셋을 확장 하기 힘들다. SBERT는 코사인 유사도를 사용해서 문장 임베딩 간의 유사도를 계산한다. 추가로 negative 맨해튼과 negative 유클리디언 거리를 사용해서도 유사도를 측정한다. 거리 측정법 별 성능은 거의 비슷했다고 한다.
4.1 Unsupervised STS
STS 용 학습 데이터가 없다고 가정하고 STS 태스크에 대해 SBERT의 성능을 검증 했다. STS 태스크 ‘12-‘16, STS 벤치마크 그리고 SICK-Relatedness 데이터셋을 사용했다. 이 데이터셋 들은 문장 쌍의 의미 관련성을 0-5라벨로 표현한다. 본 논문의 결과에서는 Pearson correlation이 STS에 적합하지 않았다고 한다.
- 문장 임베딩 간의 유사도를 계산한다.
- 계산 한 유사도와 라벨 사이의 상관 관계를 계산한다.
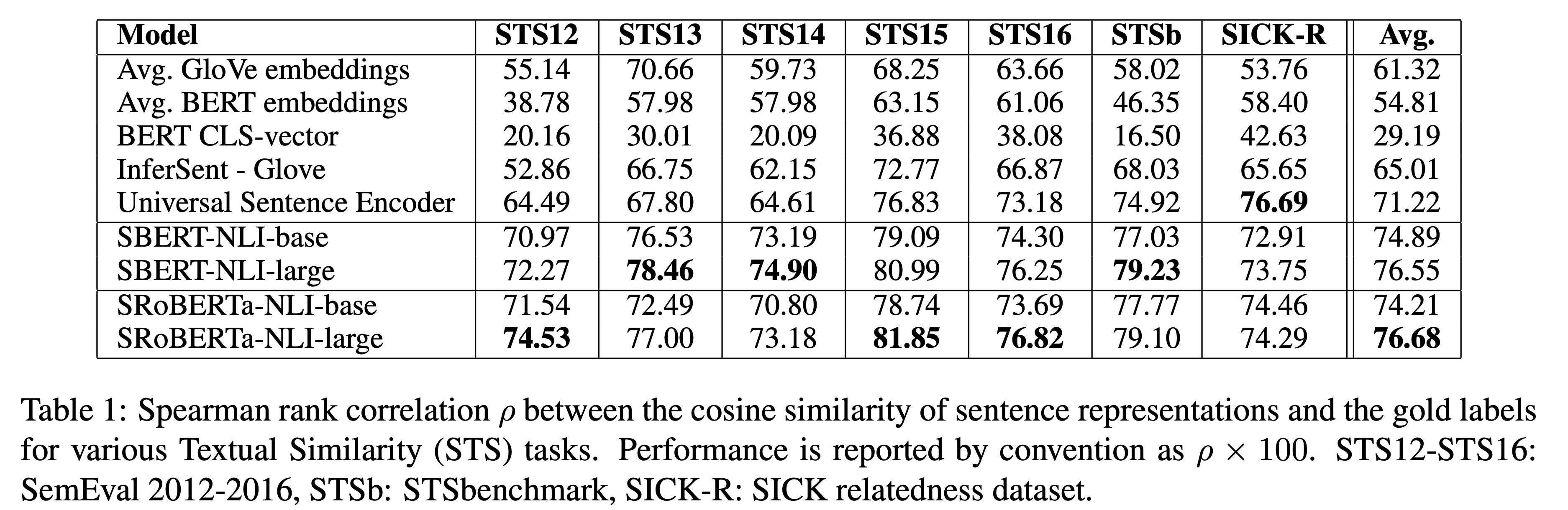
Spearman’s rank correlation을 계산한다. 다른 문장 임베딩 방법에 대한 것들도 동일하게 유사도는 코사인 유사도를 사용한다. 결과는 테이블 1에 있다.
- 피어슨 상관 관계 : 두 계량형 변수 사이의 선형 관계를 평가한다. ( 한 변수 변화가 다른 변수 변화에 비례적 )
- 스피어맨 상관 관계 : 두 계량형 변수 또는 순서형 변수 사이의 단순 관계 평가
테이블 1
테이블 1의 결과를 보면 BERT의 출력을 그대로 사용하는 것은 성능이 낮다. BERT 임베딩 평균을 사용 했을 때, 평균 correlation은 54.81, CLS 토큰을 출력으로 사용했을때, 평균 correlation은 29.19를 달성했다. 둘다 GloVe 임베딩 평균보다 나쁘다.
샴 네트워크 구조와 파인튜닝 메커니즘을 사용하는 것은 correlation을 상당히 개선했고 InferSent와 Universal Sentence Encoder 보다 더 성능이 좋았다. SICK-R에서만 Universal Sentence Encoder의 성능이 SBERT에 비해 높았다. SICK-R에 Universal Sentence Encoder가 더 적합한 이유는 다양한 데이터셋으로 학습 되었기 때문이다. SBERT는 NLI와 BERT의 학습에 사용된 Wikipedia 만 사용한 것으로 학습이 되었다.
RoBERTa는 몇 개의 지도학습 태스크에서 성능 개선을 보였으나, 문장 임베딩 생성에서는 SBERT와 SRoBERTa 간 성능 차이는 거의 없었다.
4.2 Supervised STS
STS 벤치마크는 이미 지도학습 된 STS 모델의 검증에 사용하는 데이터셋으로 유명하다. 8,628개의 문장 쌍으로 caption, news 그리고 forums 세가지 카테고리를 가진다. 5,749 쌍을 학습으로 1,500 쌍은 개발 그리고 테스트에 1,379 쌍으로 데이터 셋을 분할한다. BERT는 두 문장을 입력으로 받고 간단한 회귀 방법으로 출력으로 해서 SOTA를 달성했었다.
SBERT에서는 학습 데이터 셋을 회귀 목적 함수를 파인튜닝에 사용했다. 예측 할 때, 문장 간 코사인 유사도를 계산했다. 모든 모델들은 variance 문제를 해소하고자 10개 랜덤 시드로 학습했다. 결과는 테이블 2에 있다.

테이블 2
실험을 두 가지 환경에서 진행 되었다.
- STSb에서만 학습
- NLI로 우선 학습 한 뒤, STSb로 학습한다.
두번째의 학습 전략이 1-2 포인트 정도의 약간의 개선이 있었다. 이러한 두 접근법은 BERT cross-encoder 구조에 큰 영향을 주었고, 3-4 포인트의 개선을 했다. SBERT와 RoBERTa 간 차이는 거의 없었다고 한다.
4.3 Argument Facet Similarity
SBERT를 Argument Facet Similiarity 코퍼스로 검증했다. AFS 코퍼스는 세가지 주제에 대한 소셜 미디어 구문으로 구성된 6,000개의 sentential argument 쌍이다. 주제는 gun controll, gay marriage 그리고 death penalty이다. 데이터는 0(다른 주제)-5(완전 동일)으로 주석이 달린다. AFS 코퍼스 내의 유사도 개념은 STS 데이터셋의 유사도 개념과는 다르다. STS 데이터는 보통 설명인 반면, AFS 데이터는 대화에서 나온 논증이다. 유사하다고 판단 되려면, 논쟁에서는 유사한 주제를 다루는 것만이 아닌 유사한 근거도 함께 있어야 한다. 그리고 AFS가 문장 간 어휘의 간격이 더 크다. 그렇기 때문에 STS 시스템에서 SOTA 급의 비지도 메소드가 이 데이터셋에서 잘 동작하지 못한다.
이 데이터셋에 두가지 시나리오로 SBERT를 검증한다.
- 10-fold cross-validation : 다른 토픽들에 일반화가 잘 되는지 명확하게 검증할 수 없다.
- cross-topic 환경에서 SBERT를 검증한다.
학습 과정에서 토픽 두 가지가 제공되고 남은 한 토픽을 사용해서 검증을 한다. 모든 세가지 토픽에 대해서 반복하고 결과를 평균한다.
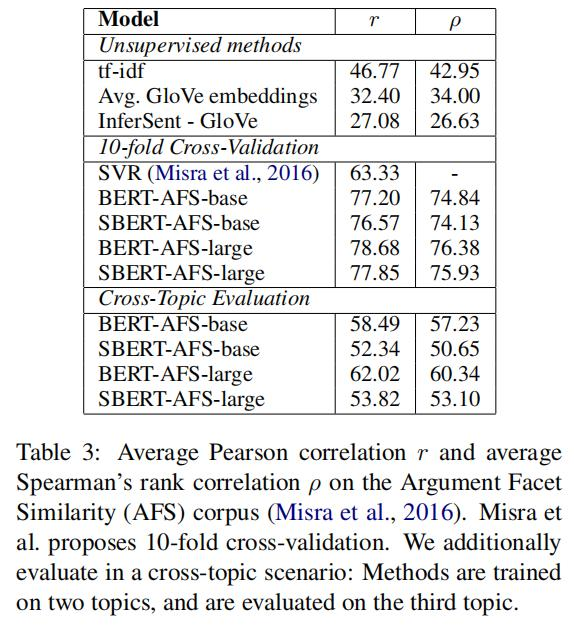
SBERT는 회귀 목적 함수를 사용해서 파인튜닝 한다. 유사도 점수는 문장 임베딩 간 코사인 유사도를 계산해서 구한다. 기존 결과와 비교로 피어슨 상관 계수 r를 사용했다. 피어슨 상관 계수가 꽤 심각한 결점이 있다는 것을 발견했고, 그렇기 때문에 STS 모델과 비교할 수 없다고 한다. 결과는 아래 테이블 3에 있다.
테이블 3
tf-idf, GloVe 임베딩 평균 이나 InferSent 같은 비지도 학습 방식은 낮은 성능 보였다. 10-fold cross validation 환경에서 SBERT를 학습하는 것은 BERT 성능과 거의 동등했다.
그러나 cross-topic 검증에서, 스피어만 상관계수에서 SBERT가 7 포인트 감소 한 것을 관측했다. 논쟁은 같은 주장을 다루어야하고 같은 논거를 들어야 유사하다고 할 수 있다. BERT는 두 문장들을 직접 비교하기 위해서 어텐션을 사용하고( word-by-word 비교 ), SBERT는 각 개별 문장들을 학습에서 보지 못한 topic에서 벡터 공간으로 매핑해야 한다. 매핑된 벡터는 유사한 주장과 근거라면 거리가 가까워야 한다. 그렇기 때문에 더 어려운 태스크라고 할 수 있다. BERT와 동급으로 동작하기 위해서는 두 개 이상의 주제가 필요한 것으로 보인다.
4.4 Wikipedia Sections Distinction
Dor et al. (2018)은 Wikipedia를 사용해서 문장 임베딩의 학습, 개발 그리고 테스트 할 수 있는 데이터 셋을 만들었다. 위키피디아 글들은 특정한 측면에 초점을 맞춘 별개의 섹션으로 구분 되어져 있다. Dor et al은 같은 섹션 내의 문장은 다른 섹션의 문장에 비해 주제적으로 유사하다고 가정했다. 그리고 문장 triplet을 약하게 라벨링하는 방법으로 거대한 데이터셋을 만들었다. 기준 문장과 긍정 문장은 같은 섹션에서 가져오고 부정 문장은 동일 글의 다른 섹션에서 가져왔다.
예를 들어, Alice Arnold 글에서
- Anchor : Arnold joined the BBC Radio Drama Company in 1988
- Positive : Arnold gained media attention in May 2012.
- Negative : Balding and Arnold are keen amateur golfers
Dor et al의 데이터셋을 사용했다. Triplet 목적 함수를 사용했는데, SBERT 학습의 한 epoch에 180만 triplet을 학습하고 222,957 triplet으로 검증했다. 검증 메트릭으로는 정확도를 사용했다 : 긍정 예제가 기준에 더 가까운가? 부정 예제 보다?
결과는 아래 테이블 4에 나온다. Dor et al은 이 데이터셋에서 문장 임베딩을 도출 하기 위해서 BiLSTM 아키텍처를 triplet 로스로 파인튜닝했다. 테이블에서 볼 수 있듯이, SBERT가 성능이 BiLSTM에 비해 좋았다.
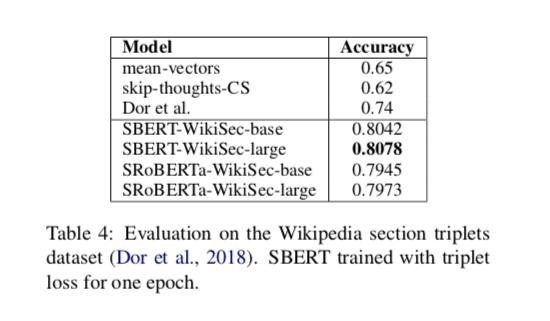
테이블 4
5 Evaluation - SentEval
SentEval은 문장 임베딩 수준을 검증하기 위한 툴킷으로 유명하다. 문장 임베딩은 로지스틱 리그레션 분류기의 피처로 사용된다. 이 분류기는 10-fold cross-validation 환경으로 다양한 태스크에서 학습이 되고 예측 정확도는 test-fold에서 계산된다.
SBERT의 문장 임베딩은 다른 태스크에 트랜스퍼 러닝으로 사용될 목적은 아니었다. BERT 파인 튜닝은 BERT 네트워크의 모든 계층을 업데이트 하기 때문에 더 문장 임베딩에 적합한 방법이라고 논문에서는 한다. 그러나, SentEval을 사용하면 다양한 태스크의 문장 임베딩을 표현할 수 있다.
검증에는 SBERT의 문장 임베딩을 다른 문장 임베딩 방법의 결과와 비교한다.
- MR : 영화 리뷰에 대한 감정 예측
- CR : 상품 리뷰에 대한 감정 예측
- SUBJ : 영화 리뷰와 플롯 요약의 문장의 주관성 예측
- MPQA : 뉴스와이어의 오피니언의 구문 수준 극성 분류
- SST : 스탠포드 감정 트리뱅크 이진 라벨
- TREC : TREC의 세밀한 질문 유형 분류
- MRPC : 병렬 뉴스 소스의 마이크로소프트 페러프레이즈 코퍼스
결과는 테이블 5에서 찾을 수 있다.
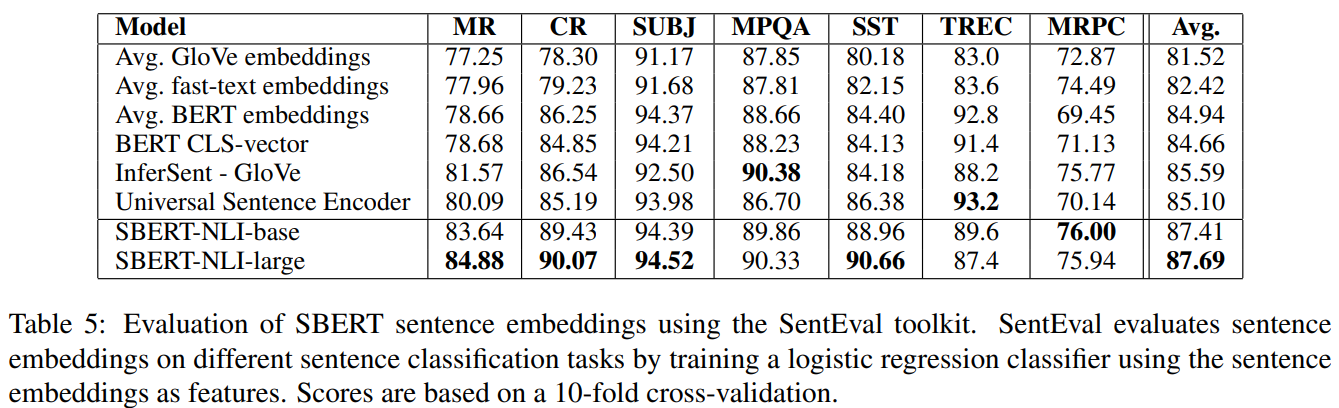
테이블 5
SBERT는 일곱 태스크 중 다섯 태스크에서 최고 성능을 달성했다. 평균 성능은 InferSent 점수로 비교했을 때 Universal Sentence Encoder에 비해 2 퍼센트 정도 상승 했다. SBERT의 목적이 트랜스퍼 러닝이 아님에도 불구하고, 이 태스크의 다른 문장 임베딩 SOTA 보다 월등한 성능을 보였다.
테이블의 결과로 보았을 때, SBERT의 문장 임베딩은 감정 정보를 잘 캡처 하는것 처럼 보인다 : 감정 태스크 ( MR, CR 그리고 STT)에서 상당한 개선을 보였다.
Universal Sentence Encoder가 더 잘 나온 태스크는 TREC 데이터셋이다. Universal Sentence Encoder가 질의 응답 데이터에서 사전 학습 되어서 질문을 분류하는 TREC 데이터셋에서 성능이 좋은 걸로 보인다.
평균 BERT 임베딩이나 CLS 토큰 출력을 사용하는 것은 테이블 1에서 확인 할 수 있듯 성능이 GloVe 평균보다 좋지는 않다. 그러나 SentEval 에서는 BERT 임베딩의 평균과 CLS 토큰 출력이 더 좋았다. STS 태스크에서 문장 임베딩 간의 코사인 유사도를 사용했고, SentEval은 반대로 문장 임베딩에 로지스틱 리그레션을 학습한다. 코사인 유사도는 모든 차원을 동일하게 본지만, SentEval의 분류에서 특정 차원이 더 높거나 더 낮은 효과를 준다는 것이다.
검증 결과로 BERT 임베딩 평균 / CLS 토큰 출력이 코사인 유사도나 맨해튼 / 유클리디언 거리에 사용할 수 없다는 결론을 낼 수 있다. 트랜스퍼 러닝에서는 InferSent 나 Universal Sentence Encoder에 비해 낮은 성능을 보인다. 그렇지만 NLI 데이터셋에 샴 네트워크 구조를 적용하는 파인 튜닝 방법은 SentEval 툴킷에서 새롭게 SOTA를 달성했다.
6 Ablation Study
- 풀링 전략 세가지(MEAN, MAX, CLS)를 검증했다.
- 분류 목적 함수에서는 서로 다른 결합 메소드를 검증한다.
이런 구성으로, 10개의 랜덤 시드로 SBERT를 학습하고 그 성능을 평균 했다. 데이터셋에 따라 다른 목적 함수( 분류 vs 회귀)를 사용했다. 분류 목적 함수의 경우에는 SNLI와 Multi-NLI 데이터셋에 대해서 SBERT를 학습했다. 회귀 목적 함수에는 STS 벤치마크 데이터셋을 트레이닝 셋으로 학습했다. 성능은 STS 벤치마크 데이터셋을 분리해서 성능을 측정 했다고 한다. 테이블 6에서 결과를 볼 수 있었다.
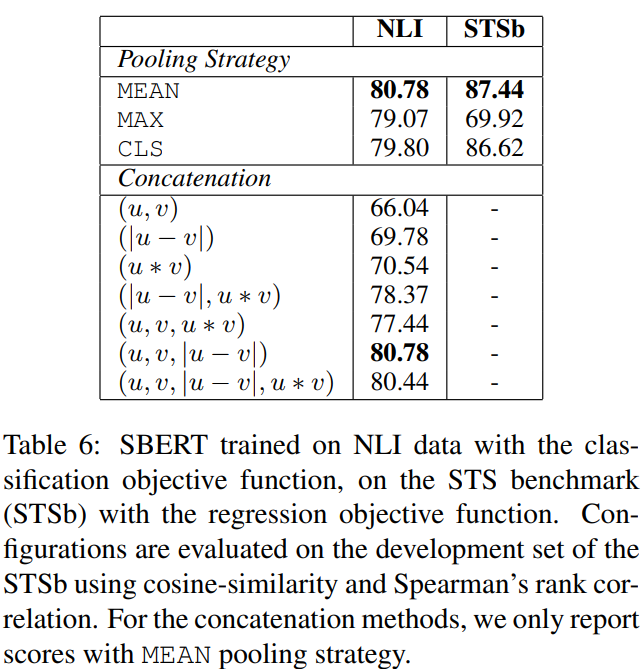
테이블 6
분류 목적 함수로 NLI 데이터에 학습 했을 때, 풀링 전략에 따른 성능에는 큰 차이는 없었다고 한다. 벡터의 결합 방식에서 효과가 더 컸다. InferSent와 Universal Sentence Encoder 둘다 (u, v, |u-v|, uv)을 입력으로 소프트 맥스 분류기에 사용했다. 원소 단위로 곱하는 uv를 추가하는 것은 성능을 감소 시켰다고 한다.
여기서 가장 중요한 컴포넌트는 원소 단위의 차인 |u-v| 였다. 결합 방식은 소프트 맥스 분류기를 학습 시에 영향을 주었다. 추론에서, STS 벤치마크 데이터셋 내 유사도 예측은 문장 임베딩 u와 v를 사용해서 코사인 유사도에 사용한다. 두 문장 임베딩의 원소 간 차이로, 유사한 쌍은 더 가깝게 다른 쌍은 더 먼 것을 보장하는 방식으로 문장 임베딩 간 거리를 계산한다.
회귀 목적 함수를 사용해서 학습 했을 때에는 풀링 전략이 큰 영향을 끼쳤다고 한다. MAX 전략은 MEAN 이나 CLS 토큰에 비해서 훨씬 나빴다. 기존 BiLSTM 레이어를 사용한 연구에서는 InferSent에서 MAX가 MEAN에 비해서 이점이 있다는 연구 결과와 SBERT의 연구 결과는 달랐다고 한다.
7 Computational Efficiency
문장 임베딩은 수백만의 문장들에 잠재적으로 계산 되어야 하기 때문에, 높은 계산 속도가 필요하다. 이 섹션에서 SBERT와 GloVe 임베딩의 평균, InferSent 그리고 Universal Sentence Encoder를 비교한다.
STS 벤치마크의 문장을 사용해서 비교를 했는데, GloVe 임베딩의 평균은 Numpy와 파이썬의 사전을 룩업하는 간단한 for-loop를 사용해서 계산 했다고 한다. InferSent는 Pytorch를 사용해서 개발 했다. Universal Sentence Encoder는 Tensorflow 허브의 모델 버전을 사용했다. SBERT는 Pytorch를 사용해서 개발 했다. 문장 임베딩 계산을 개선하기 위해, 스마트 배칭 전략을 구현했는데 스마트 배칭은 다음과 같다.
- 유사한 길이를 가지는 문장을 함께 그루핑 한다.
- 미니 배치 내에서 가장 긴 원소에 패딩 한다.
스마트 배칭을 사용함으로 패딩 토큰에 의해 유발되는 계산 오버헤드를 엄청나게 감소 시킬 수 있다고 한다.
성능은 Intel i7-5820k CPU @ 3.30GHz, Nvidia Tesla V100 GPU, CUDA 9.2 and cuDNN 서버에서 측정되었다고 한다. 결과는 테이블 7에 있다.

테이블 7
CPU 에서 InferSent가 SBERT에 비해 65% 더 빠른데, 더 간단한 네트워크 구조 때문이다. InferSent는 하나의 Bi-LSTM 레이어를 사용하고, BERT는 12개를 쌓은 트랜스포머 레이어를 사용한다. 그러나 GPU 연산에서 트랜스포머를 사용할 때는 이점이 있다. 추가로 SBERT의 스마트 배칭을 사용하면 InferSent 에 비해 9% 속도 향상이 있고 Universal Sentence Encoder에 비해 55% 빠르다. 스마트 배칭은 CPU에서 89% GPU에서 48%의 속도 향상을 했다. 평균 GloVe 임베딩 방법은 문장 임베딩을 연상하는 데에서 엄청난 차이로 빠르다고 한다.
8 Conclusion
본 논문에서는 BERT에 별도의 구성 없이 문장을 벡터 공간으로 매핑하는 메소드를 보였다. 그리고 그 방법 들이 흔하게 사용하는 코사인 유사도 기반 유사도 측정 방법에서는 적절하지 않다는 것도 보였다. 일곱 가지 STS 태스크의 성능에서 GloVe 임베딩의 평균보다 성능이 낮았다.
본 논문에서는 Sentence-BERT( SBERT )로 문제를 해결하고자 했다. BERT를 샴 / 트리플렛 네트워크 구조를 사용해서 파인튜닝을 한다. 그 결과 문장 임베딩 메소드 들에 대해서 상당한 개선을 달성했다. BERT나 RoBERTa 냐를 그다지 의미 없었다.
SBERT는 연산적으로서 효율적이다. GPU에서 InferSent에 비해 9%, Universal Sentence Encoder에서 55%가 더 빠르다. SBERT는 연산적으로 BERT를 사용해서 모델링 하지 못하는 태스크 들에도 사용할 수 있다. 예를 들어, BERT에서 Hierarchical Clustering 을 사용해서 10,000개 문장을 클러스터링 하는 것은 65시간이 소요되는데 5천만의 문장의 조합을 계산해야 하기 때문이다. SBERT를 사용하면 5초만에 가능하다.
9 ETC
NAACL 2021에 억셉된 Augmented SBERT