Cross-lingual Language Model Pretraining : XLM 리뷰
Abstract
최근 연구들은 영어 자연어 이해를 위한 생성적 사전학습(generative pretraining)의 효율성을 증명했다. 본 연구에서는 이 방식을 여러 언어들로 확장해서 교차 언어(cross-lingual) 사전학습의 효과를 보인다. cross-lingual language model(XLM)을 학습하는 세가지 메소드를 제시한다.
- 단일 언어 데이터만 사용하는 비지도 학습 메소드
- 병렬 데이터와 XLM에 새로운 목적함수를 사용하는 지도 학습 메소드
교차 언어 분류, 지도 및 비지도 방식의 기계 번역에서 SOTA를 달성했다.
- XNLI 데이터셋에서 논문의 방법은 정확도를 4.9% 개선 (SOTA)
비지도 학습 방식의 기계 번역의 경우
- WMT'16 독일어-영어에서 34.3 BLEU로 이전 SOTA에 비해 9 BLEU를 개선
지도 학습 방식의 기계 번역의 경우
- WMT'16 루마니아-영어에서는 38.5 BLEU로 이전에 비해 4 BLEU를 개선
코드와 사전학습 된 모델이 퍼블릭하게 공개될 예정이다.
1 Introduction
문장 인코더의 생성적 사전학습은 많은 자연어 이해 벤치마크에 엄청난 개선을 이끌었다. 트랜스포머 언어 모델은 거대한 텍스트 말뭉치로 비지도 학습이 사용되고, 분류나 자연어 추론 같은 다른 자연어 이해 태스크에 파인튜닝 된다. 범용적인 문장 표현 학습이 급격한 관심을 받고 있지만, 단일 언어 특히 영어에 대해서만 초점이 맞춰져 있다. 교차 언어 모델의 학습과 검증에 대한 연구로 영어로 편향된 점을 완화하고 모든 언어의 문장을 공유 임베딩으로 인코딩 할 수 있는 범용적인 교차 언어 인코더를 제안한다.
이 연구에서는 교차 언어 모델의 사전학습 효과를 다중 언어 교차 이해 벤치마크로 증명한다. 이 논문에는 정확하게는 다섯 가지의 기여가 있다.
- 새로운 비지도 학습 메소드를 소개한다. 교차 언어 모델링으로 교차 언어 표현을 학습하기 위한 두 가지 단일 언어 사전 학습 목적 함수를 연구한다.
- 새로운 지도 학습 목적 함수를 소개한다. 병렬 데이터를 사용할 때, 교차 언어 사전학습을 개선한다.
- 교차 언어 분류로 SOTA를 달성했는데, 비지도 기계 번역과 지도 기계 번역 방식이었다.
- 교차 언어 모델이 리소스가 적은 언어의 perplexity를 개선함을 보인다.
- 코드와 사전 학습 모델을 공개한다.
Related Work
트랜스포머의 인코더 사전학습으로 언어 모델링으로 시작해서 GLUE 벤치마크의 태스크에서 엄청난 개선을 시켰다. 언어 모델의 사전학습이 기계 번역 태스크의 성능을 개선시키는 것을 보였다. 교차 언어 모델링 방법을 적용한 교차 언어 분류 결과도 BERT 저장소(Multilingual Bert)에 게시 되어있다. 섹션5에서 이 방법의 결과와 논문의 방법의 결과를 비교한다.
텍스트 표현 분포를 정렬하는 연구
단어 임베딩 정렬에서 시작해서 작은 사전을 활용해서 서로 다른 언어들의 단어 표현을 정렬하는 연구가 있다. 계속된 연구에서 교차 언어 표현이 단일 언어 표현 성능도 개선할 수 있다는 것을 보였고, 직교 변환이 이런 단어 분포를 정렬하기에 충분하다고 보였고, 그리고 이 모든 기술들은 여러가지 언어에 적용 될 수 있다. 이후에는 언어 간 감독의 필요성이 계속해서 감소되어 결국 없어졌다. 이 연구에서는, 문장 분포를 정렬하고 병렬 데이터의 필요성을 감소시켜서 이러한 아이디어를 한 단계 더 발전 시켰다.
병렬 데이터를 사용한 교차 언어 문장을 제로샷으로 하는 분류 연구
교차 언어 인코더를 사용한 가장 성공적인 방법은 다언어 기계번역이다. LSTM 인코더와 디코더를 공유한 seq2seq 모델이 많은 언어 쌍에서 기계 번역에 사용 될 수 있음을 보였다. 다중 언어 모델은 리소스가 적은 언어 쌍에서 SOTA를 달성했고 제로샷 번역을 가능하게 했다.
인코더의 결과를 교차 언어 문장 임베딩 생성에 사용하는 연구
이 연구는 이 억개 이상의 병렬 문장을 활용한다. 그래서 마지막에 나온 고정된 문장 표현에 분류기를 학습해서 XNLI 교차 언어 분류 벤치마크에서 SOTA를 달성 했다. 이런 메소드 들은 많은 병렬 데이터가 필요하다.
최근 비지도 방식의 기계 번역
문장 표현이 비지도 방식으로 완벽하게 정렬 됨을 보인다. 예를 들어, WMT'16 독일어-영어 에서 병렬 문장을 사용하지 않고 25.2 BLEU를 달성한 연구도 있었다. 이 연구와 유사하게, 본 연구에서도 비지도 방식으로 문장 분포를 분류 할 수 있음을 보이고, 그래서 교차 언어 모델이 기계 번역이 포함된 자연어 이해 태스크의 범용적으로 사용될 수 있음을 보인다.
본 연구와 가장 유사한 연구
LSTM 언어 모델을 서로 다른 언어의 문장으로 사용해서 학습한다. LSTM의 파라미터들은 공유하지만, 각 언어의 단어를 표현할 때는 룩업 테이블은 다른 걸 사용한다.단어 표현을 정렬 하는데 초점을 맞추었고 단어 번역 태스크에 잘 동작한다는 것을 보였다.
3 Cross-lingual language models
이 섹션에서는, 세가지 언어 모델링 방법을 제시한다.
- 단일 언어 데이터를 사용하는 두가지 비지도 학습 방법 ( +2 )
- 병렬 문장을 사용하는 지도 학습 방법 ( +1 )
언어를 N개를 다룬다. N 개의 단일 언어 말뭉치 ${{C_i}}_{i=1…N}$를 가진다고 가정하고, 말뭉치 $C_i$ 내의 문장의 수를 $n_i$로 표기한다.
3.1 Shared sub-word vocabulary($*$)
모든 실험에서는 모든 언어를 처리를 BPE로 생성한 동일한 vocab을 공유해서 사용한다. 이전 연구와 같이, vocab을 공유하는 것이 숫자나 고유 명사와 같은 동일한 알파벳과 기준 토큰을 공유하기 때문에 언어에 따른 임베딩 공간 정렬을 개선시킨다. 단일 언어 말뭉치에서 랜덤하게 샘플된 문장들의 결합으로 BPE 분할을 학습한다. 문장들은 확률 ${q_i}_{i=1…N}$을 사용하는 다항분포에 따라 샘플링 된다.
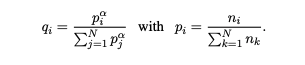
Figure 1
$\alpha = 0.5$로 사용한다. 이 분포로 샘플링 하면 리소스가 적은 언어와 연관된 토큰의 수가 증가하고 리소스가 많은 쪽으로 편향 되는 것을 완화한다. 특히, 리소스가 적은 언어들의 단어들이 한 글자 씩으로 분할 되는 것을 방지한다.
3.2 Casual Language Modeling (CLM)
CLM은 트랜스포머 언어 모델로 구성되는데 모델은 문장에서 이전 단어 토큰 들이 주어 질 때 현재 단어 토큰에 대한 확률을 내는 방식 $P(w_t | w_1,…,w_{t-1},\theta)$ ( 정통적인 RNN의 학습 방식 )으로 학습된다. RNN이 언어 모델링 벤치마크에서 SOTA를 했었지만, 트랜스포머 모델도 경쟁력이 있다.
LSTM 언어 모델의 경우, BPTT는 LSTM의 마지막 히든 스테이트를 제공해서 수행된다. 트랜스포머의 경우 이전의 히든 스테이트를 현재 배치로 전달해서 배치의 첫번째 단어에 컨텍스트를 제공할 수 있다. 그러나 이 기술은 교차 언어 환경에서는 사용할 수 없어서, 각 배치에 컨텍스트가 없는 첫 단어를 사용한다.
3.3 Maksed Language Model (MLM)
BERT와 같은 MLM의 방식
- 텍스트에서 15%의 BPE 토큰을 샘플링
- 80%의 확률로 [MASK] 토큰으로 변경한다.
- 10%는 랜덤한 토큰으로 변경한다.
- 10%는 그대로 둔다.
논문의 방식과 MLM의 차이는 문장의 쌍을 사용하는 것이 아닌 랜덤한 수의 문장(256개 토큰)을 사용하는 점이다. 자주 등장하고 자주 등장하지 않는 토큰 간 불균형을 처리하기 위해서, 자주 등장하는 토큰을 서브 샘플링한다. 텍스트 스트림의 토큰들은 단일 언어 분포에 따라 샘플링 되고, 샘플링 가중치로 그들의 발생 빈도 제곱근을 분모로 사용한다. 목적 함수는 그림 1에 있다.
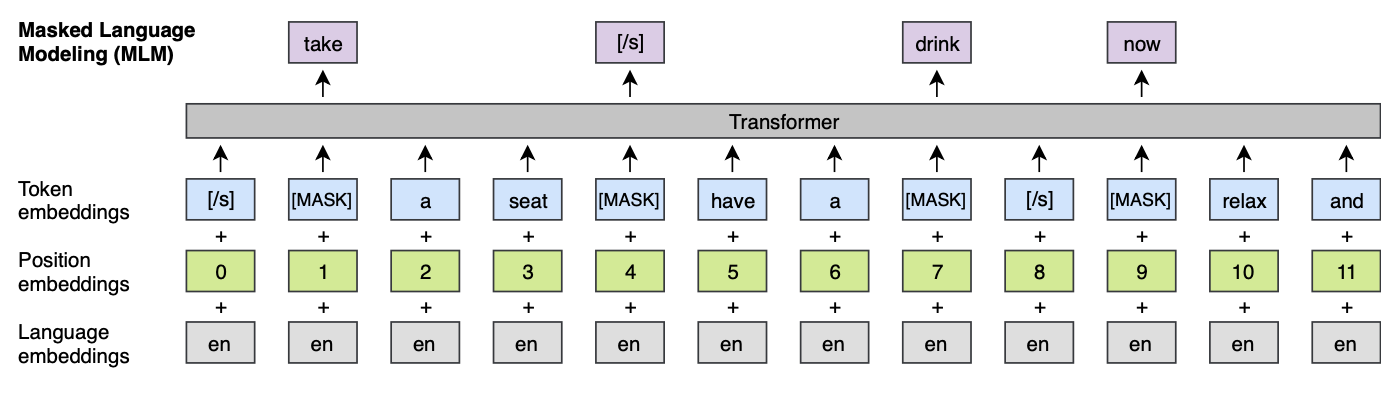
Figure 2
3.4 Translation Language Modeling (TLM)
TLM은 지도 학습 방법이다. CLM과 MLM의 비지도 방식이고 단일 언어 데이터만 사용한다. 병렬 데이터를 활용할 수 없다. TLM은 MLM이 확장된 형태로, 단일 언어 텍스트 스트림을 고려하는 하는 것이 아닌 그림 1에서 묘사된 것 처럼 병렬 문장(소스 문장과 타겟 문장)이 결합된 형태를 다룬다. 소스와 타겟 문장 둘 다에 랜덤하게 단어를 마스킹한다. 소스 문장에서 마스킹 된 단어를 예측하기 위해서, 둘러싼 소스 단어 들과 번역된 타겟 단어를 사용한다. 특히, 모델은 소스 문장으로 마스킹 된 소스 언어의 단어를 추론하기 부족할 때, 타겟 언어의 컨텍스트를 활용할 수 있다. 이 정렬 난이도를 낮추기 위해 타겟 문장의 위치도 재설정 한다.
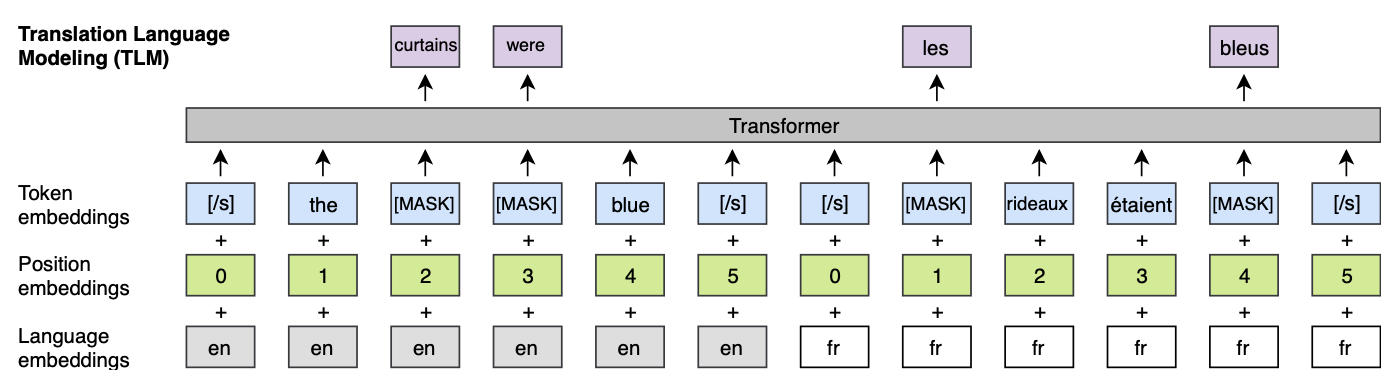
Figure 3
3.5 Cross-lingual Language Models
본 연구에서는 교차 언어 모델 사전학습에 CLM, MLM, TLM과 함께 사용되는 MLM을 함께 고려한다. CLM과 MLM 목적함수를 위해, 256개 토큰들로 구성된 연속된 문장을 배치 사이즈 64로 학습한다. 각 반복에서 배치는 같은 언어를 사용해서 구성된다. 분포 ${q_i}_{i=1…N}$에서 $\alpha=0.7$ 로 샘플링한 문장들로 구성된다. TLM이 MLM과 함께 사용 될 때에는, 두 목적함수를 번갈아가며 비슷한 방식으로 언어 쌍을 샘플링한다.
4 Cross-lingual language model pretraining
교차 언어 모델이 다운 스트림 태스크에서 어떻게 사용될 수 있는지 설명한다.
- 제로샷 언어 교차 분류를 위한 문장 인코더의 더 좋은 초기화
- 지도와 비지도 신경망 기계 번역 시스템의 더 좋은 초기화
- 리소스가 적은 언어를 위한 모델
- 비지도 학습 방식의 교차 언어 임베딩
4.1 Cross-lingual classification
사전학습 된 XLM 모델 들은 일반적인 교차 언어 텍스트 표현을 제공한다. 단일 언어 모델을 영어 분류 태스크에 파인튜닝하는 것과 유사하게,
- 교차 언어 분류 벤치마크로 XLM을 사전학습한다.
- 사전 학습된 트랜스포머의 첫번째 히든 스테이트에 선형 분류기를 추가한다.
- 영어 NLI 학습 데이터셋에 모든 파라미터를 파인튜닝한다.
교차 언어 자연어 추론 데이터 셋(XNLI, 15개 언어)을 검증하는데 사용한다. 또한 학습과 테스트 셋의 기계 번역 베이스라인을 포함한다. 결과는 테이블 1에 리포트한다.

Figure 4
4.2 Unsupervised Machine Translation
사전학습은 비지도 학습 기반 기계 번역(UNMT)의 핵심 요소이다. Lample et al. (2018b)의 연구에서는 룩업 테이블을 초기화에 사용하는 사전 학습된 교차 언어 단어 임베딩의 품질이 비지도 기계 번역 모델의 성능에 엄청난 영향을 미친다는 것을 보였다. 논문에서는 이 아이디어를 한 단계 더 발전 시키는 방식을 제시한다. UNMT 과정을 반복적 부스팅(여러 개를 생성, 활용 - 트리)하는 방법으로 트랜스포머의 전체 인코더와 디코더를 사전학습 하는 것이다. 다양한 스키마를 탐색하고 그 효과를 몇가지 표준 기계 번역 벤치마크로 검증한다. 벤치마크로 WMT'14 영어-프랑스어, WMT'16 영어-독일어 그리고 WMT'16 영어-루마니어 데이터셋을 사용한다. 결과는 테이블 2에 리포트 된다.
4.3 Supervised Machine Translation
지도 학습 기반에서의 사전학습의 효과를 기계 번역으로 테스트했다. 사전학습한 모델을 번역이 가능하도록 파인튜닝한다. Ramachandran et al. (2016)의 방법을 다중 언어 NMT로 확장 시킨다. WMT'16의 루마니아어-영어 벤치마크로 CLM과 MLM을 사전학습 해서 효과를 검증한다. 결과는 테이블 3에 리포트한다.
4.4 Low-resource language modeling
리소스가 적은 언어는 더 많은 리소스를 가지는 유사한 언어의 데이터를 활용하면 좋을 수 있다. 특히 유사한 언어 vocab의 상당한 부분을 공유할 때 좋다. 예를들어 위키피디아에 100k 네팔어 문장이 있고, 6배 더 많은 문장이 힌두어로 있다. 두 언어는 100k 서브 단어 단위의 공유된 BPE vocab에서 80%의 공통된 토큰을 가진다. 네팔어 모델과 네팔어로 학습을 했지만 힌두어와 영어 데이터의 다른 조합으로 풍부해진 교차 언어 모델의 복잡성을 테이블 4에서 비교한다.
4.5 Unsupervised cross-lingual word embeddings
Conneau et al. (2018a) 는 단일 언어의 단어 임베딩 공간을 적대적 학습(MUSE)으로 정렬해서 비지도 단어 번역 하는것을 보였다. Lample et al. (2018a)는
- 두 언어 간 공유 vocab을 사용한다.
- 언어 말뭉치의 결합에 fastText를 적용한다.
이 방법 공통 알파벳을 공유하는 언어에 대해 높은 성능의 교차 언어 임베딩을 직접 제공하는 것을 보였다. 이 연구에서 공유 vocab도 사용하지만 단어 임베딩은 교차 언어 모델의 룩업 테이블로 구해진다. 섹션 5에서, 이 세 방법을 서로 다른 세가지 메트릭들로 비교한다. 메트릭으로 코사인 유사도, L2 거리 그리고 교차 단어 유사도를 사용한다.
Figure 5
5 Experiments and results
일곱가지 벤치마크로 사전학습한 교차 언어 모델 사전학습의 효과를 실험적으로 증명하고 현 SOTA와 비교한다.
5.1 Training details
모든 실험에서 트랜스포머 구조를 사용한다. 트랜스포머의 구조는 1024 히든 유닛, 8 헤더, GELU, 0.1 드롭아웃 그리고 학습된 포지셔널 임베딩을 사용한다. 학습에는 아담 옵티마이저, 선형 웜업 그리고 학습율은 $10^{-4}$에서 $5.10^{-4}$ 까지를 사용한다.
CLR과 MLM 목적 함수에서는, 256 토큰에 미니 배치 사이즈 64를 사용한다. 미니 배치 시퀀스에 섹션 3.2에 설명 된 것 같이 두개 이상의 연속된 문장을 포함 될 수 있다. TLM 목적 함수에서는 4000개의 토큰으로 구성된 미니 배치를 비슷한 길이의 문장으로 샘플링한다. 학습 중지 기준으로 언어에 대한 평균 난이도를 사용한다. 기계 번역의 경우, 여섯개의 레이어 만 사용하고, 2000개의 토큰으로 구성된 미니 배치를 만든다.
XNLI로 파인튜닝을 할때, 미니 배치 크기를 8,16을 사용하고, 문장 길이를 256 단어들로 고정한다.
우리는 80k BPE 분할과 95k vocab 그리고 12 레이어 모델을 XNLI 언어들의 위키피디아에 학습한다. 아담 옵티마이저의 학습률을 $5.10^{-4}$에서 $2.10^{-4}$ 까지로 샘플링 하고, 이만개 랜덤 샘플의 작은 검증 과정을 사용한다. 랜덤하게 초기화된 마지막 선형 분류기에 트랜스포머의 마지막 레이어의 첫번째 히든 스테이트를 입력으로 사용하고 모든 파라미터를 파인튜닝한다. 실험에서, 마지막 레이어에 맥스 풀링과 평균 풀링을 사용하는 것은 첫번째 히든 스테이트를 사용하는 것보다 성능이 나빴다.
모든 모델은 파이토치로 구현했고 언어 모델링에 64개의 Volta GPU를 사용했고, 기계 번역 태스크에는 8개를 사용했다. 학습 속도를 올리고 모델 메모리 사용율을 낮추기 위해 float16을 사용했다.
5.2 Data preprocessing
$WikiExtractor$를 사용해서 위키피다이 덤프에서 raw한 문장들을 추출하고 CLM과 MLM 목적함수를 위한 단일 언어 데이터로 사용했다. TLM 목적함수에서, 영어가 포함된 병렬 데이터를 사용했다. 프랑스어, 스페인어, 러시아어, 아라비안어, 중국어를 위해서는 MultiUN을 사용했다. 힌두어를 위해서는 OPUS 웹사이트 에서 추출한 IIT 봄베이 말뭉치를 사용했다. 독일어, 그리스어, 불가리아어에는 EUbookshop 말뭉치, 터키어, 베트남어, 태국어는 OpenSubtitles 2018, 우르두어와 스와힐리어를 위한 Tanzil, 스와힐리어를 위한 GlobalVoices. 중국어, 일본어 그리고 태국어에는 $Kytea$ 토크나이저와 $PyThaiNLP$를 사용했다. 다른 언어에는 Moses가 제공한 토크나이저를 사용했다. fastBPE를 사용해서 BPE 코드를 학습하고 서브 워드 단위로 분할 했다. BPE 코드들은 모든 언어들에서 샘플링 되어 결합된 문장으로 학습되었다. 메소드에 대한 설명은 섹션 3.1에 있다.
5.3 Results and analysis
교차 언어 모델의 사전학습의 효과성을 증명한다. 이전 교차 어어 분류, 비지도 및 지도 기계 번역 태스크의 이전 SOTA에 비해 높은 성능을 보였다.
Cross-lingual classification ( 4.1 )
테이블 1에서 두 종류의 사전 학습된 교차 언어 인코더를 검증한다 :
- 단일 언어 말뭉치에 MLM을 사용한 비지도 학습 모델
- 병렬 데이터로 MLM과 TLM 로스를 결합한 지도 학습 모델
Conneau et al. (2018b)의 연구와 같이, 두 기계 학습 베이스라인을 포함하는데 :
- TRANSLATE-TRAIN, 영문 MultiNLI 학습 셋을 XNLI 셋의 각 언어로 기계 번역
- TRANSLATE-TEST, XNLI의 모든 언어 데이터셋을 영어로 번역
MLM 메소드는 제로샷 교차 언어 분류에서 SOTA를 이루었고, 223 백만 병렬 문장을 사용하는 Artetxe and Schwenk (2018)( 평균 정확도 70.2% )에 비해 월등한 성능( 평균 정확도 71.5% )을 냈다.
병렬 데이터를 사용하는 MLM+TLM은, 정확도 3.6%가 개선된 75.1를 달성했다. 적은 리소스 언어인 스와힐리어와 우르두어 에서는, 상대적으로 6.2%, 6.3%를 개선시켰다. TLM+MLM은 영문에서 MLM(83.2%)에서 85%로 정확도를 개선시켰다. Artetxe and Schwenk (2018)(11.1%) 그리고 Devlin et al. (2018)(3.6%)의 개선을 이루었다.
각 XNLI 언어(TRANSLATE-TRAIN)를 학습 셋으로 파인튜닝을 하면, 논문의 지도 모델은 우리의 제로샷 접근법에 비해 1.6% 우수 했고 평균 정확도 76.7%로 SOTA에 도달했다. 이 결과는 특히 접근 방식의 일관성을 증명하고 XLM이 높은 성능으로 어떠한 언어에도 파인튜닝 될 수 있음을 보여준다. 다언어 BERT( Devlin et al. 2018)과 유사하게, TRANSLATE-TRAIN이 평균 정확도 2.5%가 TRASLATE-TEST에 비해 높다는 것을 보았고, 제로샷 접근법에서는 0.9%가 높다는 것을 보였다.
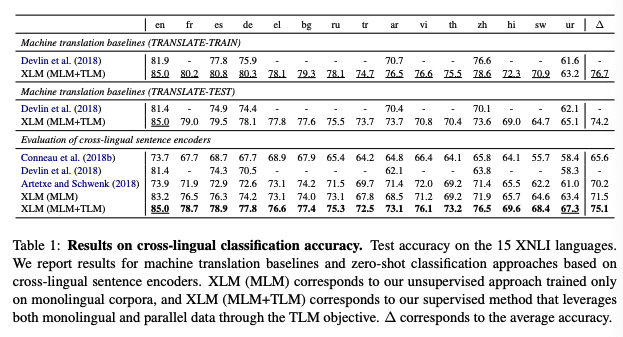
Table 1
Unsupervised machine translation ( 4.2 )
비지도 기계 번역 태스크의 경우 세가지 언어 쌍을 고려한다. : 영어-프랑스어, 영어-독일어, 영어-루마니아어. 세팅은 Lample et al. (2018b)의 세팅과 동일하지만, 룩업 테이블만 아니라 교차 언어 모델링을 사용해서 전체 모델을 사전 학습하는 초기화 단계는 제외한다.
인코더와 디코더에서는, 다양한 초기화를 다룬다.
- CLM 사전 학습
- MLM 사전 학습
- 랜덤 초기화
9개의 서로 다른 세팅이 나온다. 그리고 Lample et al. (2018b)를 따라 온라인 역 번역 로스와 함께 디노이징 오토 인코딩 로스를 사용해서 모델을 학습시킨다. 결과는 테이블 2에 리포트 되어있다. Lample et al. (2018b)의 결과와 비교했다. 각 언어 쌍에서 이전의 SOTA에 비해 상당한 성능 개선을 보았다. Lample et al. (2018b) (EMB)의 NMT 방법을 재구현했고, 보고된 성능에 비해 더 좋은 결과를 얻었다. 더 큰 배치를 사용하는 멀티 GPU 구현에 인한 것으로 예상한다.
독일어-영어에서 이전 비지도 방법에 비해 9.1 BLEU를 개선을 이루었고, 신경망 기반 비지도 방법에서는 13.3 BLEU가 개선 되었다. 룩업 테이블 (EMB)만 사전 학습 하는 것과 비교하면, MLM으로 인코더와 디코더를 사전 학습하면 독일어-영어에서 7 BLEU 이상의 지속적인 개선이 된다. MLM으로 사전 학습하는 것이 CLM에 비해 상당한 개선을 보임을 발견했다. 영어-프랑스어에서 30.4 ~ 33.4 BLEU, 루마니아어-영어에서 28.0 ~ 31.8 정도였다. 이러한 결과들은 NLU 태스크들에 MLM과 CLM을 비교 했던 Devlin et al. (2018)의 연구와 동일하다. 그리고 인코더가 사전학습에서 가장 중요함을 발견했다. 인코더와 디코더의 사전학습하는 것을 비교하면, 디코더 만을 사전학습 하는 것은 성능을 엄청나게 떨어트리는 것을 발견했고, 인코더만 사전학습 하는 것은 최종 BLEU 스코어에 미미한 효과가 있다는 것을 발견했다.
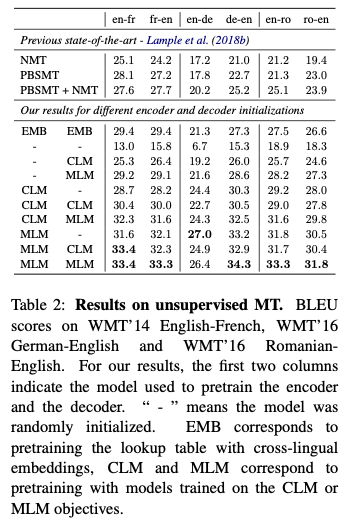
Table 2
Supervised machine translation (4.3)
테이블 3에서는 서로 다른 지도 학습 구성에서의 루마니아어-영어 WMT'16 의 성능을 보고했다.
- 단방향 ( 루 → 영 )
- 양방향 ( 루 → 영, 영 → 루 )
- 양방향과 back-translation ( 루 ↔ 영 + BT )
BT를 이용한 모델은 사전 학습에 사용하는 언어 모델과 동일한 단일 언어 데이터로 학습된다. 비지도 학습에서는 사전 학습이 각 구성에서 BLEU 스코어를 엄청난 개선을 보임을 발견했고, MLM을 사용한 사전학습이 최고 성능을 보였다. BT를 사용한 모델이 사전 학습 모델과 동일한 양의 데이터를 사용하지만 검증으로 사용할만큼 잘 생성하지는 못했다. 양방향+BT 모델은 최고 성능을 보였고 38.5 BLEU 점수를 달성했다. 이전 SOTA 였던 Senrich et al. (2016) ( BT + 앙상블 )에 비해 4 BLEU 의 성능 개선을 달성했다.
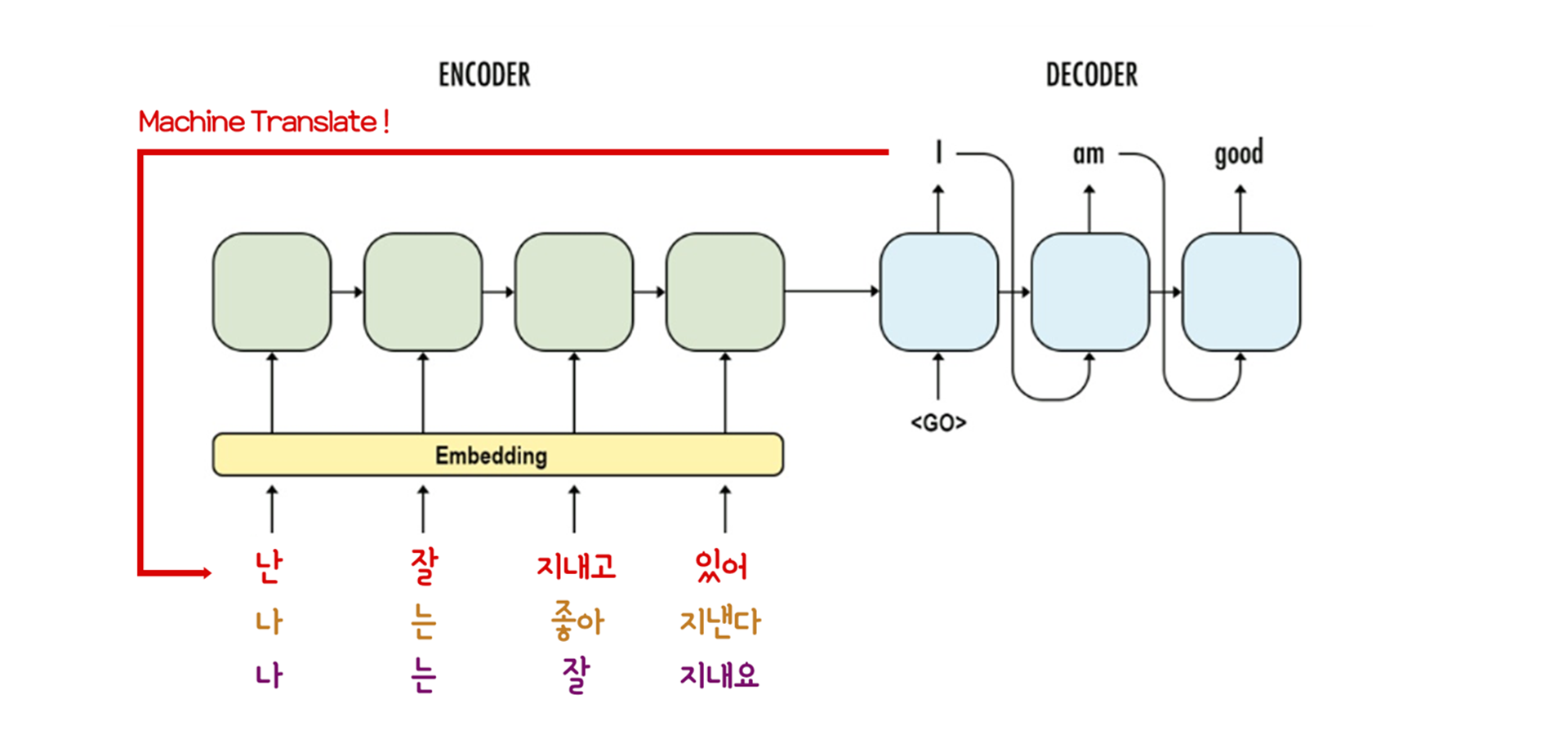
Figure 6
완벽하지는 않더라도 Target Sentence를 보고 인공적인 Source Sentence를 만드는 과정
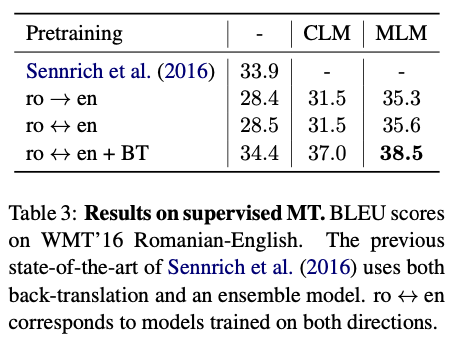
Table 3
Low-resource language model (4.4)
테이블 4에서는 네팔 언어 perplexity(모델 자체의 성능, 낮으면 좋다)을 개선시키기위해 교차 언어 모델링에 대해 조사했다. 그렇게 하기 위해서
- 위키피디아로 네팔 언어 모델을 학습한다.
- 추가로 영어와 힌두어를 사용한다.
네팔어와 영어가 거리가 좀 있는 언어지만, 네팔어와 힌두어는 유사한게 동일한 힌두어 알파벳을 공유하고 산스크리트 어에서 발전된 언어이기 때문이다. 영어 데이터를 사용했을 때, 네팔 언어모델의 perplexity를 17.1점을 낮췄고, 네팔어만 사용한 모델 157.2에서 시작해서 전체를 사용했을 때 109.3으로 41.6점을 낮췄다. 교차 언어 모델링으로 인한 perplexity 개선을 얻은 것은 위키피디아 기사와 같이 언어 간 공유되는 n 그램 기준 포인트로 부분적으로 설명할 수 있다. 그래서 교차 언어 모델은 네팔어 모델을 개선시키기 위해 이러한 기준 포인트로 힌두어나 영어 단일 말뭉치에서 제공하는 추가 컨텍스트를 트랜스퍼 할 수 있다.
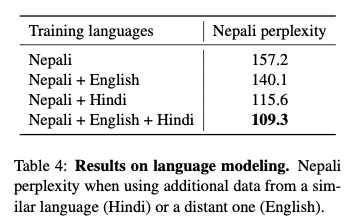
Table 4
Unsupervised cross-lingual word embeddings (4.5)
- MUSE
- Concat ( fastText )
- XLM(MLM) ( fastText )
위의 메소드들은 서로 다른 특성을 가지는 비지도 학습 방식의 교차 언어 임베딩을 제공한다. 테이블 5에서는 동일한 vocab을 사용한 세가지 메소드를 연구하고 MUSE 사전의 단어 번역 쌍에서의 코사인 유사도와 L2를 계산한다. Camacho-Collados et al.(2017)에서의 SemEval’ 17 교차 언어 유사도 태스크를 통한 코사인 유사도 측정법의 성능을 검증한다. 교차 언어에서 단어 유사도에서XLM이 Concat과 MUSE에 비해 더 좋은 성능을 보였고 피어슨 상관 계수 0.69를 달성했다. XLM이 Concat과 MUSE에 비해 임베딩 거리가 더 가까웠다. MUSE는 코사인 유사도 0.38, L2 5.13이고 XLM은 0.55, 2.64 였다. XLM 임베딩들은 이러한 근접성을 강화할 수 있는 문장 인코더와 함께 학습되는 특수성을 가지고 있지만, MUSE와 Concat은 fastText 단어 임베딩을 기반으로 한다.
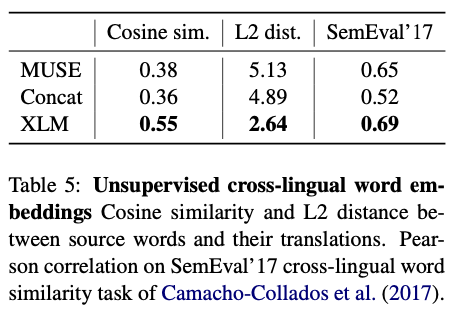
Table 5
6 Conclusion
이 연구에서 교차 언어 모델 (XLM) 사전학습의 강력한 효과를 처음으로 보였다. 단일 언어 말뭉치만을 사용하는 두가지 비지도 학습 목적함수를 조사했다. : Casual Language Modeling (CLM) 그리고 Masked Language Modeling (MLM). 두 접근법 모두가 모델을 사전학습 하기 위한 강력한 교차 언어 피처를 제공하는 것을 보였다. 비지도 학습 기반 기계 번역에서 MLM 사전학습이 굉장히 효과적인 것을 보였다. WMT'16 독일어-영어 데이터에서 34.3으로 새로운 SOTA를 달성했고, 이전 SOTA에 비해 9 BLEU를 개선했다. 지도학습 기반 기계 번역에서도 강력한 개선을 얻었다. WMT'16 루마니아어-영어에서 38.5 BLEU로 새로운 SOTA를 달성했고 4 BLEU 이상의 개선을 얻었다. 교차 언어 모델이 네팔어 모델의 perplexity를 개선 시키는데 사용할 수 있음을 보였고 비지도 교차 언어 임베딩에 제공 될 수 있음을 보였다. 단일 교차 문장을 사용하지 않고, 교차 언어 분류 벤치마크인 XNLI으로 파인튜닝한 교차 언어 모델은 이전 SOTA에 비해 평균 1.3% 정확도를 개선했다. 이 연구의 가장 중요한 기여는 번역 언어 모델링(TLM)의 목적함수로 병렬 데이터를 활용해서 교차 언어 모델의 사전 학습을 개선시킨 것이다. MLM을 확장시켜 연속적인 문장들 대신 병렬 문장들을 배치로 사용한 TLM을 사용한 방법이다. MLM에 TLM을 추가로 사용해서 상당한 개선을 얻었고, 그리고 이 지도 학습 접근법이 XNLI에서 이전 SOTA에 비해 평균 정확도를 4.9% 개선했음을 보였다. 코드와 학습된 모델이 공개될 것이다.
참고자료
[고려대 ICPS lab. 논문리뷰] Cross-lingual Language Model Pretraining