Collaborative Filtering Bandits 논문 리뷰
Collaborative Filtering Bandits 리뷰
ABSTRACT
기존 추천 방식
- Collaborative filtering
- Content-Based Filtering
주어진 학습 데이터로 부터 모델을 학습하는 메소드( 정적인 모델 ).
뉴스 추천 이나 광고 도메인에는 적용이 힘듬 → 아이템과 유저 셋의 계속된 변경
Contextual MAB 기반 적응형 클러스터링
유저 클러스터링 + 아이템 클러스터링
데이터 내의 선호 패턴을 이용한다. ( collaborative filtering )
SOTA
Regret 분석
1. INTRODUCTION
Collarborative Filtering
아이템에 대한 상호작용한 정보를 사용한다.
유저 피처와 아이템 피처의 내적 메소드와 같은 기술로 재현하고,
유저와 아이템을 그룹핑 가능한 형태로 만들어 추천하는 방법이다.
Cold-Start 문제
아이템에 대한 유저의 누적된 상호 작용의 부족하다.
계속해서 변화하는 유저 + 아이템 + 선호도, CF 메소드들이 망가짐.
MAB
Exploration-Exploitation 메소드
표준 contextual 밴딧은 상호작용 정보를 처리하지 못한다.
- 유저가 유사한 아이템들을 경험했다는 과거 만으론 비슷한 취향을 가진 것으로 판단 못한다.
- 동일한 유저 그룹에서 선택한 아이템도 유사한 것으로 고려하지 못한다.
멀티 암드 밴딧과 + 온라인 클러스터링 같은 알고리즘을 사용
Stochastic multi-armed bandit에 기반한 Collaborative Filtering 메소드
Standard Contxtual Bandit 메소드에 Collarborative 정보를 녹여낸다.
Bandit의 Reward를 추천하는 아이템에 대한 유저의 선호도로 사용한다.
유저 사이드 클러스터링 + 아이템 사이드 클러스터링( 밴딧 기반 클러스터링 )
sparse한 그래프 표현으로 MF 기술을 회피한다.
exploration vs exploration 딜레마를 해결하기 위해 (contextual) multi-armed bandits 적용한다.
가정
컨텐츠의 각 아이템이 유저 클러스터를 결정해서 유저에게 컨텐츠를 제공하고, 그 클러스터 내 유저들은 아이템을 추천 받을 때 유사하게 반응하는 경향을 보인다.
아이템의 수가 많으면, 아이템도 유저에 의해 결정된 클러스터링 함수로 클러스터링 될 수 있다.
증명
실제 세 벤치마크 데이터셋에 실험으로 증명한다.
regret 분석을 제공한다.
2. LEARNING MODEL
유저 행동 유사도는 피처벡터 $x$(컨텍스트 혹은 아이템 )에 적용한 클러스터링으로 인코딩 된다고 가정한다.
- $U = {{1,…,n}}$ : 크기가 $n$인 유저셋
- $x \in R^D$: 아이템 피처 벡터 $x$ ( 아이템 자체, 컨텍스트)
유저 셋 $U$가 $U_1(x), U_2(x), …, U_m(x)$ 인 $m(x)$ 개의 클러스터로 파티션 된다.
- 여기서 $m(x)$는 상수 $m$에 결정이 된다.
- $x$와는 독립적이다.
- 유저 클러스터 수 $m$은 전체 유저 수 $n$보다 작다. ( 필수는 아님 )
- 동일한 클러스터 $U_j(x)$에 속한 유저는 유사한 행동을 하는 경향이 있다.
아이템 피처 $x$를 사용한 클러스터로 유저셋 $U$를 파티션 한다. ( 유저 클러스터링 )
$x → {{ U_1(x), U_2(x), …, U_{m(x)}(X) }}$
- : 클러스터 내 공통된 유저 행동은 유저 피드백으로 추론 해야한다.
선형 함수 $x→ u_i^Tx$에 의해 클러스터링이 결정된다 ( 간소화 )
유저 $i \in U$에서 제공되는 $u_i \in R^d$에 의해 파라미터화 되는 각각은
- 유저 $i$와 $i’$가 같은 클러스터 인 경우 → $u_i^Tx = u_{i’}^Tx$
- 유저 $i$와 $i’$가 다른 클러스터 인 경우 → $|u_i^Tx - u_{i’}^Tx| >= \gamma$
*: 갭 파라미터 $\gamma > 0$는 $x$와 관계 없음
벡터 $u_i$는 유저 $i$의 행동 패턴 벡터이다.
아이템 벡터 $x$를 받았을 때 유저 $i$의 반응 하는 것을 가치 보상 값(payoff, actual reward)으로 본다.
$a_i(x) = R_{i_t} = u_i^Tx + \epsilon_i(x)$ ( Linear Regression 과 유사한 형태, Contxtual-MAB )
- $\epsilon_i(x)$는 평균 0인 경계 분산 노이즈 텀으로, 과거에 영향을 받는다.
- 퀀티티 $u_i^Tx$는 컨텍스트 벡터 $x$에 대해서 유저 $i$에서 관측된 기대 보상 가치이다.
- 유저 벡터 $u_i$는 시간 불변. ( 개선 가능성 )
학습은 여러 라운드로 구성된다.
유저에게 새롭게 받은 정보를 계속 적용해야하는 환경에 직면하기 때문이다.
- 라운드 마다 추천을 제공할 유저 인덱스 $i_t \in u$ 와 추천 아이템 리스트 $C_{i_t}$를 받는다.
- 유저 시퀀스 $i_1, i_2, …$는 외부 프로세스에서 결정 된다. ( 중복 가능 )
- $C_{i_t} = {{ x_{t,1}, x_{t,2},…,x_{t,c_t}}} \subseteq R^d$, 라운드 t에서 유저 $i_t$에게 추천 가능한 컨텐츠의 벡터 셋
-
$\bar{x}t = x{t,k_t} \in C_{i_t}$를 선택하고 $i_t$에게 추천한다.
-
$a_t \in R$ 인 기대 보상의 형태로 (조건부) 기대 값이 $u_{i_t}^Tx_t$인 인 $i_t$의 피드백을 관측한다.
학습 시스템의 목표 : T 라운드에 대해 전체 기대 보상( $\sum_{t=1}^T a_t$)를 최대화
사용자 피드백이 클릭/논클릭 인 경우 → 보상 $a_t$는 이진 형태의 피드백.
if (추천 아이템을 유저( $i_t$)가 클릭 ):
$a_t=1$
else
$a_t = 0$
전체 T 라운드에 대한 동작에 대한 누적 보상인 $\frac{\sum_{t=1}^{T}a_t}{T}$는 클릭율(CTR)이 된다.
이론적 관점 ( cumulative regret bound )
시간 $t$에서 학습자의 regret $r_t$을 돌이켜 봤을 때, 유저 $u_i$가 최선의 선택을 했을 때의 평균 가치 보상이 알고리즘이 선택한 가치 보상의 평균을 초과하는 시점.
$r_t = ( \underset{x \in C_{i_t}}{\max} \ u_{i_t}^Tx) - u_{i_t}^T\bar{x_t}.$
아래의 것들을 최소화 하려고 한다.
- 누적 regret $\sum_{t=1}^T r_t$,
- 추정 가치 보상에 대한 노이즈 텀 $\epsilon_{i_t}(\bar{x}_t)$
- 기차 가능 추가 원인
비교 하고 싶은 regret bound는 $x$에 대한 $U$에 대한 사후 클러스터링 구조를 알게된 시점이다.
아이템 클러스터
CF 처럼 유저의 선호도 유사성을 기반으로 아이템들을 클러스터로 그룹핑할 가치가 있다.
아이템 셋은 크기 때문에 사전 정보가 있을 때만 클러스터링을 한다.
Collarborative Filtering based on adaptive two-sided clustering
유저를 아이템에 대한 선호도로 그룹핑하는 동시에 유저 유사도로 아이템을 그룹핑을 한다.
- 아이템 셋 $I = {{ x_1, x_2, …, x_{|I|} }}$
- 아이템 $x_h$로 유도된 파티션된 유저셋 $P(x_h) = {{ U_1(x_h), U_2(x_h), …, U_{m(x_h)}(x_h) }}$
$P(x_h) = P(x_{h’})$ 일때, 두 아이템이 같은 클러스터에 속한다고 정한다.
- $g$ : 클러스터 수
- 전체 아이템 수 보다 아이템 클러스터 수를 작다고 가정한다.
추천될 아이템들이 특정 피처들을 소유하지 못한 경우
기존의 non-contextual stochastic 멀티 암드 밴딧 세팅에 의존한다.
- $d=|I|$ ( 유일한 아이템 ) ( One-Hot )
- 아이템 셋 $I$가 $R^d$에 기초한 d 차원의 벡터들 $e_h, h = 1,…,d$로 구성된다고 가정한다.
인덱스 h( h번째 아이템)에 대해
- 유저 i의 기대 가치 보상이 벡터 $u_i$의 h 번째 요소가 된다.
- 두 유저 $i$와 $i’$가 같은 클러스터 일때, $u_i$의 h번째 요소와 $u_{i’}$의 h번째 요소가 같다.
3. RELATED WORK
배치 CF 이웃 메소드 연구
- 타겟 유저-아이템 쌍과 유사한 유저 그룹이나 아이템 그룹을 찾는다.
- 결국에는 CF 기반의 메소드들이 co-clustering 기법과 통합 되었다.
- co-cluster를 사용해서 유저-아이템의 선호 관계를 모델링.
동적 클러스터링을 통한 멀티 암드 밴딧 알고리즘에 대한 연구
16번 연구
유저들은 피처 벡터들을 사용해서 정의된다는 가정
유저 간의 차이가 저 차원이라고 가정해서 저차원의 히든 서브 공간을 학습하려고 한다.
저차원 매트릭스 복구와 고차원의 가우시안 프로세스 밴딧을 결합
규모가 있는 문제에는 실용적이지 못하다.
27번 연구
모델 파라미터들이 몇가지 (알려지지않은) 타입들로 클러스터링 된다는 가정
non-contextual stochastic bandit을 사용한다.
온라인 클러스터링(K-means와 같은)을 contextual bandit 세팅과 결합
유저 사이드에서의 밴딧 클러스터링에 의존(그것만)해서 시간이 지남에 따라 동일한 사용자에 대한 추천을 다양하게 만드는데 중점한다.
22번 연구
k개의 가장 매력적인 아이템들을 발견하기 위해 유저 행동에 대한 cascading 밴딧을 제시한다.
stochastic combinatorial partial 모니터링 문제로 공식화 한다.
1, 2, 26번 연구
중앙 집중화 되거나 분산 환경에서 유저 사이드로 클러스터링 했을 때의 COFIBA의 특수한 사례
7번 연구
태스크에서 사용 가능한 모델 셋이 사전 분포로 정의된 stochastic multi-armed bandit 세팅의 트랜스퍼 러닝 문제를 정의한다.
9번 연구
모델 파라미터 유사도에 기반한 마코프 결정 프로세스 클러스터링에 의존한다.
10번 연구
n개의 알려지지 않은 분포들 중에서 특정 메트릭에 의해 가장 평균이 큰 k개 아이템을 선택하는 방법.
20번 연구
온라인 MF에 대해 Rao-Blackwellizaiton을 사용한 파티클 톰슨 샘플링을 연구해서, $n \times m$ 랭크 1 매트릭스인 특별한 케이스에 대해 regret bound를 표시한다.
위의 어떤 연구들에서도 stochastic multi-armed bandits에 적용되는 아이템 의존적인 클러스터링에 대해 연구하지 않았다.
25번 연구
contextual bandit의 앙상블로 추천 시스템의 콜드 스타트 문제를 해결
32번 연구
추정 모델의 분포를 도출하기 위한 온라인 부츠스트랩을 사용해서 파라미터가 없는 밴딧에서 확률 매칭 기반 콜드 스타트 해결
4. THE ALGORITHM
- 유저와 아이템 사이드에서 적응형 클러스터링
- upper-confidence 기반 exploration-exploitation Trade-Off
매 라운드마다 유저 $i \in U$와 관련된 벡터 $u_i$의 추정치 $w_{i,t}$는 저장된다.
벡터 $w_{i,t}$ 는 $u_i$에 할당된 가치 비용 피드백으로 업데이트 된다. ( 선형 최소 제곱 근사값 )
모든 유저 $i \in U$에 대해 가능한 컨텐츠 $C_{i_t}$에서 선형 밴딧과 같은 알고리즘으로 추천을 제공한다.
$w_{i, t-1}$
가중치 벡터 $w_{i,t-1}$로 인코딩된 유저 정보와 신뢰 한계인 $CB_{i,t-1}(x)$를 기반으로, 유저 셋 $U$의 클러스터과 아이템 $I$에 대한 단일 클러스터링을 유지하고 업데이트 해야한다. 클러스터링은 방향성 없는 그래프로 표현된다. (노드 = 아이템 + 유저 )
-
첫번째 업데이트 대상 inverse correlation matrix $M_{i,t-1}^{-1}$ ( dxd 차원 매트리스 )
매트릭스 $M_{i,t-1}^{-1}$는 아이템 추천을 위한 두 연산에 사용된다.
- 아이템 피처 $x$에 따른 $w_{i,t-1}$~ $u_i$ 근사치 계산
- 근사치에 대한 노이즈 텀 $CB_{i,t-1}(x)$(UCB) 계산.
-
부가적인 업데이트 대상인 벡터 $b_{i, t-1}$에 의해 결정된다. ( d 차원 벡터 )
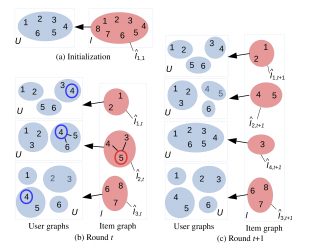
COFIBA 초기화
- 매트릭스 $M_{i,t}$들은 $d \times d$ 모양의 단위 행렬
- 벡터 $b_{i,t}$는 d 차원의 영 벡터
매 라운드 마다의 COFIBA의 동작
입력
- 현재 유저 인덱스 $i_t$
- 사용 가능한 아이템 벡터 셋 $x_{t,1} …, x_{t, c_t}$

1
추천 ( 사용 가능한 아이템 벡터 중 하나를 선택 )
- 유저 $i_t$가 속한 클러스터를 기준으로 아이템 벡터 $x_{t,k} \in C_{i_t}$ 마다 $c_t$ 개의 클러스터 $N_k$를 계산한다. $N_k$는 아이템 벡터 기준으로 클러스터링 됬을 때의 사용자가 속한 클러스터이다.
- 각 $N_k$에 대해 복합 가중치 벡터 $\bar{w}{N_k,t-1}$를 정의한다.( 해당하는 매트릭스 $M{i,t-1}$와 벡터 $b_{i,t-1}$로) 그러면 신뢰 한계값 $CB_{N_k, t-1}(x_{t,k})$이 결정된다. 벡터 $\bar{w}{N_k, t-1}$과 신뢰 한계 $CB{N_k, t-1} (x_{t,k})$는 upper-confidence exploration-exploitation 형태로 결합되어 유저 $i_t$를 위한 특정 아이템 $x_t \in C_{i_t}$로 전달된다.
업데이트 ( 추천한 아이템에 대한 피드백 )
- 추천한 아이템에 대한 가치 보상 $a_t$가 받아지고, 알고리즘은 $\bar{x_t}$를 사용해서 $M_{i_t, t-1}$를 $M_{i_t, t}$로 $b_{i_t, t-1}$를 $b_{i_t, t}$로 업데이트한다. ( 업데이트는 아이템을 추천 받은 유저 $i_t$에 대해서만 수행된다. )
- 유저 사이드 클러스터링과 (유일한) 아이템 클러스터링을 업데이트한다.

2

3

4
그래프 초기화
- 유저 사이드의 여러개 그래프 $G_{t,h}^U = (U, E_{t,h}^U)$ (h로 인덱싱된 U에 대한 많은 클러스터링)
- 아이템 사이드의 하나의 그래프 $G_t^I = (I, E_t^I)$ (I에 대한 하나의 클러스터링)
유저수 만큼 각각 클러스터링 된 결과는 아이템 측의 하나의 클러스터에 할당된다.
- $g_t$ 수 만큼의 아이템에 대한 클러스터들 $\hat{I}{1,t},…,\hat{I}{g_t, t}$
- 전체 유저에 대해 $g_t$개 클러스터를 가진다.
그래프 업데이트 (엣지 제거 )
유저 그래프 업데이트
만약 라운드 t가 시작할 때, 아이템 $x_h$이 아이템 $\bar{x}t$와 직접 연결되어 있었고, 엣지 제거로 $x_h$에 대해서 $i_t$와 근접한 유저 셋이 $\bar{x_t}$에 대해서는 더이상 동일하지 않게 되었을 때 그래프가 업데이트 된다. 선택된 아이템 $x_t = x{t, k_t}$가 가리키는 그래프 $G^U_{t,\hat{h}_t}$에 만 수행된다.
아이템 사이드 업데이트
$x_h$가 $\bar{x}_t$와 같은 유저 파티션을 유도하지 않게 되면, $edge(\bar{x}_h, x_h)$가 제거된다. 엣지 제거가 전체 아이템 셋$I$에 대해 두 아이템이 다른 클러스터에 속한다게 되는건 아니다. 두 아이템들이 간접적으로 연결 되어 있을 수도 있다. 이전 라운드($t-1$)의 유사한 두 아이템을 고려했을 때, 유저 이웃이 크게 변경 되는 경우 수행된다.
5
COFIBA 구현
$|I|$-many $n$-node 그래프($O(n^2|I|)$)를 유지하기 위한 메모리 할당이 필요하다. 매 시간 아이템에 대해 새로운 클러스터가 생성 될 때마다 Erdos-Renyi 초기화 그래프로 전체 그래프를 희소화한다.
업데이트 되는 클러스터들 $U_i(x_h)$의 크기가 너무 작지는 않다는 가정 아래서 동작한다. [1]의 논쟁을 보면, 실제에서는 초기 그래프가 $O(n^2)$이 아닌 $O(n\log n)$ 의 엣지를 가진다.
아이템 그래프의 변경이 엣지 제거만 이루어지므로, 높은 확률로 아이템 클러스터의 수 $g_t$는 COFIBA 실행 동안 상한인 $g$를 유지한다. 실제 저장 공간 → $O(ng \log n)$이다.
$I$와 $U$는 사전 지식으로 이미 알고 있다는 설정에도 불구하고, 새로운 컨텐츠나 새로운 사용자가 나타날 때, COFIBA를 조정해야 한다는 것을 막을 수는 없다. 메모리 동적 할당으로 데이터 구조를 유지하면서, 아이템이나 유저 사이드에서 그래프에 새로운 노드를 추가해야 한다. 실제로 굉장히 큰 아이템이나 유저 셋의 경우 이러한 방식으로 알고리즘을 구현했다. ( Telefonica와 Avazu 데이터셋 )
5. EXPERIMENTS
- 뉴스 추천 데이터 셋 1EA
- 광고 데이터 셋 2EA
- 표준 밴딧 베이스라인으로 비교했다
모든 경우에서 아이템에 대한 피처는 사용 되지 않았다. 그리고 이전 연구와 동일한 실험 환경을 따랐다. CTR을 사용해서 성능 검증을 한다.
5.1 데이터셋
$Yahoo!$.
ICML 2012 Exploration & Exploitation Challenge 에 릴리즈 된 공개 벤치마크 데이터셋
목표 - 뉴스 기사를 제공하는 정책을 효율적으로 학습하는 알고리즘
야후의 “Today Module"의 작은 박스로 표시되는 뉴스 트래픽 레코드로 데이터셋이 구성된다.
이주 동안의 3천만 방문에 대한 데이터이다.
18K 유저와 323개 아이템. 레코드 수는 2.8M으로,
300K는 파라미터 튜닝, 나머지 테스트
70K 라운드 테스트
$Telefonica$.
스페인 브로드 밴드와 통신사로 유럽과 남미에 비즈니스를 한다.
텔레포니카가 운영하는 웹사이트의 광고의 클릭을 포함한다.
유저 수 n은 수백만 규모, 아이템은 300 정도, 총 15M 레코드
첫 1, 5 M은 파라미터 튜닝, 나머지 테스트
제공된 광고와 아이템 셋에 포함된 다른 9개 아이템 총 10개 추천 리스트
350K 라운드 테스트
$Avazu$.
디지털 광고 비지니스 분야의 세계적 기업이다.
목표 모바일 광고에서 CTR을 예측
40M의 샘플 수, 수백만 규모 유저
첫 4M은 파라미터 튜닝, 나머지 테스트
데이터셋 전처리
피처 값이 결측된 레코드를 필터링, 아웃라이어 제거. 유저를 디바이스-ID로 식별한다
20개의 추천 리스트
900K 라운드 테스트
5.2 Algorithms
COFIBA를 SOTA 밴딧 알고리즘과 비교한다.
- LINUCB-ONE : 몇년동안 학계의 높은 관심을 받았던 UCB1 알고리즘 단일 객체
- DYNUCB : 다이나믹 UCB 알고리즘. K-Means 와 유사한 클러스터링을 채택해서 시간에 따라 변화하는 컨텍스트와 유저 선호도를 클러스터에 동적으로 할당하는 기술
- LINUCB-IND : 유저 당 하나의 UCB1 객체로, 각 유저에게 완전 개인화를 제공한다.
- CLUB : 온라인 클러스터링의 SOTA 알고리즘으로 confidence ellipsoids 를 기반으로 유저 다이나믹 클러스터링
- LINUCB-V : 더 정교한 confidence bound를 가지는 UCB1 단일 객체; ICML 2012 챌린지의 우승자 야후 데이터셋
실험 결과는 알고리즘 3번 실행의 평균치가 된다. (3번 해도 서로 낮은 분산)
5.3 Results
그림 5-7
- CTR 대 획득된 레코드들 (라운드).
- 콜드 스타트 문제를 ( 즉, x축인 시간대에서 상대적으로 작은 부분인 첫번째 ) 다룬다.
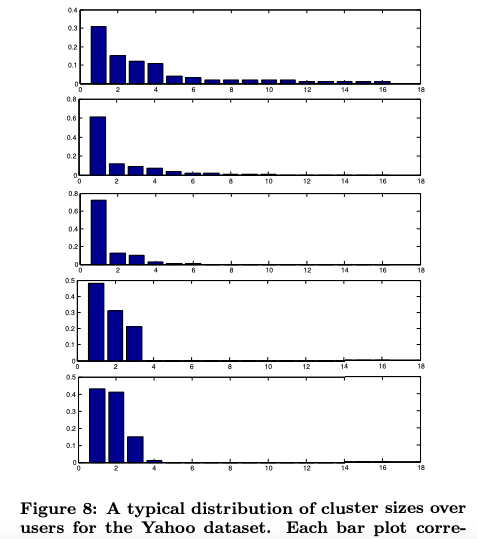
그림 8
- 이론적인 모델을 보조하는 것을 목표한다.
- 실행 종료 시, 최종 생성된 클러스터링 에 대한 결과를 제공한다.
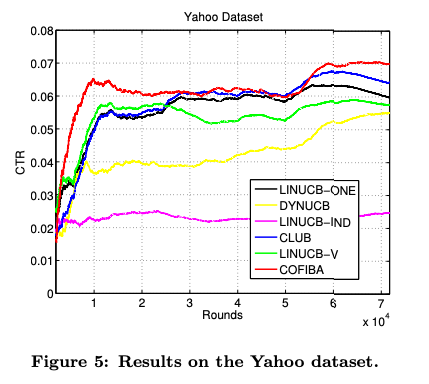
Yahoo!
유저들은 광범위한 데모그라픽 특징을 가질 수 있다.
모든 사용자가 흥미를 가질 수 있는 몇 개의 특정 핫 뉴스가 있음을 시사함. ( 인기 있는 뉴스가 따로 있다.)
Yahoo! 데이터셋에서 LINUCB-ONE과 LINUCB-V(모든 사용자에게 동일한 뉴스를 제공한다.)
어떠한 클러스터링도 하지 않는 LINUCB-IND은 낮은 성능을 보인다.
CLUB은 유저와 아이템 클러스터링을 동시에 진행하기 때문에 뉴스 추천 시스템에서 클릭 수를 올리는 훨씬 더 효과적인 전략일 수 있다.
6
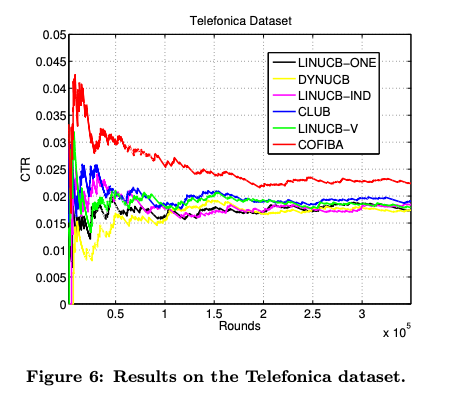
텔레포니카
많은 유저는 스페인의 다양한 사람들 협력 효과가 훨씬 더 분명하다
CLUB은 성능이 우수
DYNUCB는 초기 단계에서 성능이 저하되고 나중에 따라 잡는다.
COFIBA는 다른 모든 알고리즘의 성능을 능가하고, 특히 콜드 스타트 문제에서도 능가.
7
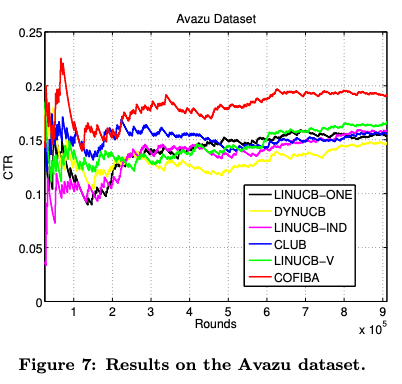
아바주
LINUCB-ONE 과 LINUCB-IND는 콜드 스타트에서 경쟁력 있는 성능을 보이지 못한다.
DYNUCB는 전체적으로 성능이 떨어짐
LINUCB-V는 상대적으로 높은 CTR을 보인다.
CLUB은 초기에는 좋았지만, 이후에 CTR이 떨어진다.
COFIBA는 콜드 스타트에서 굉장히 잘 동작하고, 뒤이은 스테이지에서도 최고였다.
8
그림 8에서 COFIBA의 동작이 완료 된 후의 클러스터 사이즈의 일반적인 분포를 낸다. 패턴은 항상 같다. 굉장히 불균형한 사이즈의 아이템 클러스터는 몇개 있으며, 아이템 클러스터에도 크기가 불균형한 크기의 유저 클러스터가 몇개 있다. 이러한 반복적인 패턴은 섹션 2의 가정으로 인해 발생하며, 이러한 데이터의 특성은 COFIBA 알고리즘이 강점을 가질 수 있다.(섹션 6). 이러한 막대 그래프는 비교적 우수한 COFIBA의 성능과 결합되어 데이터셋이 양 쪽에서 클러스터링이 가능한 특성을 가지는 것을 의미한다.
9
요약하자면, 각기 다른 세 데이터셋에도 불구하고 실험적인 결과는 거의 비슷하며, 다른 알고리즘에 비해 좋은 성능을 보였다. 콜드 스타트 기반 동안에도 그렇다. 동일한 상대적인 동작이 실험 내내 기본적으로 나타난다. COFIBA는 구현해야하는 문제가 있고 다소 느리다. ( LINUCB-ONE 과 LINUCB-IND에 비해 놀라울 정도로 느림 ) 그러나 COFIBA는 데이터 내 임베딩 되어 있는 협력 효과를 exploiting 하는데 효과적이고 대규모 데이터셋에서 실행 될 수 있다.
6. REGRET ANALYSIS
COFIBA를 이론적으로 보장하는 정리. COFIBA의 누적 regret을 아이템셋 $I$에 대한 유저셋 $U$의 클러스터링 구조와 관련시킨다.
표현의 단순화를 위해, $u_i \in R^d, i=1, …, n$ 그리고 $I= {{ e_1, …, e_d }}$인 원-핫 인코딩 케이스로 만든다.
좀 더 일반적인 구문은 $I$는 일반적인 피처셋 $I={{x_1, …, x_{|I|}}}$ 이고 벡터의 기하학적 특성에 의존해서 regret bound 인 경우를 증명할 수 있다.
클러스터링 가능성 가정을 증명하기 위해서는, $i_t$와 $C_{i_t}$ 생성 방식에 추가 조건이 필요하다.
-
가정 : 대부분의 파티션들 $P(e_h)$의 경우, 유저 클러스터의 크기가 불균형하다.
클러스터 불균형은 전체 아이템들 $I$이 유저들에게 영향을 주어
- 소수의 중요한 공통 행동
- 여러가지 사소한 행동
실제 상황에서도 빈번하게 나타나는 현상이다.
정리 1
그림 1의 COFIBA 알고리즘이 아래와 같은 세팅에서 동작한다고 가정한다.
- 유저셋 $U={{1,…,n}}$ 과 연관된 프로파일 벡터 $u_1,…,u_n \in R^d$,
- $U$에 대해 h번째 유도된 파티션 $P(e_h)$가 카디널 $v_{h,1}, v_{h,2}, …, v_{h,m_h}$인 $m_h$(의 유니크한 특성을 가진) 클러스터 들로 구성된 아이템 셋 $I={{e_1, …, e_d}}$ ( 파티션의 수를 $g$ )
매 라운드 t 마다
$i_t$는 $U$에서 랜덤 유니폼하게 얻어진다고 가정한다.
$i_t$가 선택 되면, $C_{i_t}$ 내의 아이템수 $c_t$는 아래 항목을 입력 받는 함수로 부터 임의로 생성된다.
- 과거 인덱스 $i_1, …, i_{t-1}$,
- 가치 보상 $a_1, …, a_{t-1}$
- 아이템 집합 $C_{i_1}, …, C_{i_{t-1}}$
- 현재 인덱스 $i_t$
$C_{i_t}$인 아이템 시퀀스는 아래의 항목들 에 영향을 받은 독립적이고 같은 확률 분포를 가지도록 생성된다.
- $i_t$
- $c_t$
- 모든 과거 인덱스들 $i_1, …, i_{t-1}$, 가치 보상 $a_1, …, a_{t-1}$ 그리고 아이템셋 $C_{i_1},…,C_{i_{t-1}}$
가치 보상 $a_t$는 [-1, 1] 구간에 위치한다고 가정한다.
- $a_t$의 기댓값은 $u_{i_t}^T \bar{x}_t$가 된다.
마지막으로 $\alpha$(exploration)와 $\alpha_2$(그래프 edge를 제거) 파라미터들을 $log(1 / \delta)$ 함수라고 가정한다.
If $c_t ≤ c \forall t$면 → T가 증가할 때마다, 최소 $1-\delta$ 확률로 누적 후회가 된다.
$\sum_{t=1}^{T} r_t = \tilde{O}((E[S] + \sqrt{c\sqrt{mn}VAR(S)} +1)\sqrt{\frac{dT}{n}})$
$S = S(h) = \sum_{j=1}^{m_h}\sqrt{v_{h,j}}$와 h는각각 $e_h \sim D$, $E[\cdot]$ 그리고 $VAR(\cdot)$가 랜덤 인덱스에 대해서 expectation과 variance를 나타내는 랜덤 인덱스이다.
극단적 시나리오 1
각 $P(e_h)$가 크기 $v_{h,1} = n - ( m - 1)$인 클러스터 하나를 가지고, $v_{h,1} = 1$인 $m-1$개의 클러스터를 경우($m < \sqrt{n}$ )
→ $E[S] = \sqrt{n-(m-1)} + m-1$ 이고 ${VAR}(S) = 0$ 이다. 그러면 결정되는 regret bound는 단일 d차원 유저를 학습하기 위해 달성되는 $\tilde{O}(\sqrt{dT})$가 된다.(일명, d개의 액션을 가지고 그들간에 차가 없는 표준 noncontextual bandit bound)
극단적 시나리오 2
$P(e_h)$가 n 개의 클러스터를 가지는 경우
→ $E[S]=n, VAR(S)=0$이 되고, 결과로 regret bound는 $\tilde{O}(\sqrt{dnT})$가 된다.
극단적 시나리오 3
$VAR(S) > 0$이 되는 경우
느슨한 upper bound가 되고, 여기서 부터 c와의 상호작용이 관련이 있다.
정리 1 증명
Ground Truth인 유저 클러스터를 $V_{h,1}, V_{h,2}, …, V_{h,m_h}$라고 하고 $|V_{h,j}| = v_{h,j}$라고 하자.
각각의 유저 $i$가 라운드 t에서 제공될 확률이 $1/n$이기 때문에, t가 커질 수록, 모든 $i$에 대해 $w_{i,t} → u_i$가 된다.
파라미터 $\gamma$를 적용한 갭 가정으로, 각 유저 $i$가 적어도 $O(\frac{1}{\gamma^2})$ 번 추천을 제공받은 후에는 서로 다른 클러스터에 속한 유저들을 연결하는 엣지는 제거된다.
그래프 $G_{t,h}^U$의 연결된 구성요소에 의해서 인코딩되는 현재 유저 클러스터들이 참 유저 클러스터 $m_h$로 수렴한다. 따라서 라운드 t에서 exploration vs exploitation의 Trade-Off로 알고리즘에 의해 계산되는 결합 가중치 벡터 $\bar{w}{N_k, t-1}$는 아래 형태의 식으로 $u{i_t}$로 수렴한다.
$E[ \frac{1}{\sqrt{1+T_{h_t, j_t, t-1}/d}}]$
- $h_t$는 $\bar{x}_t$가 속한 참 아이템 클러스터의 인덱스이다.
- $j_t$는 $i_t$가 속한 참 유저 클러스터의 인덱스이다. ( $h_t$에 의해서 결정된 $U$의 파티션)
- $T_{h_t, j_t, t-1}$는 클러스터 $V_{h_t, j_t}$에 히트 한 라운드의 수이다.
즉 $T_{h_t, j_t, t-1} = |{{s<= t-1; i_s \in V_{{h_t},j_t}}}|$
기댓값은 아래의 값에 영향을 받는다.
- $i_t$의 (유니폼)분포
- $C_{i_t}$에서 아이템을 생성하는 분포 $D$
- 모든 과거의 이벤트들
Azuma-Hieffding inequality에 의해서 $T_{h_t, j_t, t-1}$는 아래의 식이 된다.
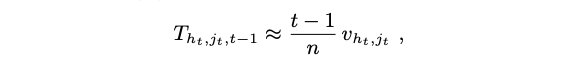
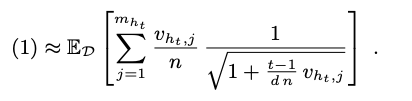
COFIBA의 누적 regret에 로그 계수 까지 고려하면 아래의 표현식이 된다.
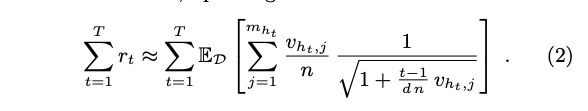
Eq. (2)(로그 계수와 생략된 부가적인 텀까지)는 U에 대한 사후 클러스터링 구조를 미리 알고 있으면 얻을수 있는 regret bound.
$h_t \in C_{i_t}$는 $C_{i_t}$내 아이템들의 함수이기 때문에, 다음과 같은 stratification argument를 통해 $h_t$에 대한 의존성을 제거할 수 있다.
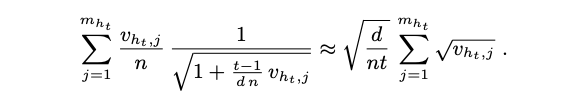
간결함을 위해 $S(H) = \sum^{m_h}{j=1}\sqrt{v{h,j}}$로 하고, $h_{t,k}$를 $x_{t,k}$가 속한 참 아이템 클러스터의 인덱스로 한다. ($h_{t,k}$는 랜덤 변수이다. ) $S(h_{t,k}) ≤ \sqrt{mn}$이기 때문에 standart argument는 다음을 보인다. )
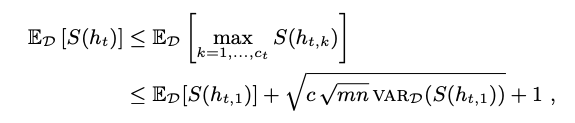
그래서 몇번의 과도한 가정 이후에, 결론을 내는데 $\sum_{t=1}^{T}r_t$는 높은 확률로 upper bound가 된다. 다음에 의해서
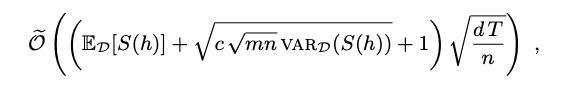
랜덤 인덱스($e_h \sim D$)에 대한 기댓값과 분산
7. CONCLUSION
collaborative filtering bandit 알고리즘에 대한 연구
- cold start 문제를 효과적이다.
- 클러스터들을 연결된 그래프 컴포넌트(최소한 유저 사이드로)로 인코딩
- 큰 데이터셋에서 계산적으로 저렴하게 유저와 아이템을 적응적으로 클러스터링하는 방법
- 추후 연구의 방향
- 데이터의 피처 보완
- 초기 학습 페이즈 동안 표준 MF 기술으로 피처들을 추론한다 .
- 추론된 피처들로 묘사된 아이템들로 알고리즘을 적용한다.
- 서로 다른 밴딧 알고리즘(학습 프로세스의 서로 다른 단계에서)을 결합
- 또 다른 하나는 MF 기술과 결합하는 것이다.
- 데이터의 피처 보완