LightGCN : Simplifying and Powering Graph Convolution Network for Recommendation 리뷰
ABSTRACT
그래프 컨볼루션 네트워크는 CF에서 새로운 SOTA가 되었다. 그럼에도 불구하고, 추천에서의 효과에 대한 근거는 잘 알려지지 않았다. 추천에 GCN을 적용한 연구 들은 GCN에 대한 ablation 분석이 부족했는데, GCN은 애초에 그래프 분류를 위해 설계 되었고 많은 뉴럴넷 연산과 함께 사용된다.
실험으로 GCN의 가장 공통적인 설계인 feature transformation과 non-linear activation이 CF에선 기여도가 낮다는 것을 발견했다. 심지어, 그 두 부분의 추가가 학습 난이도는 올리고 추천 성능을 감소 시키는 것을 발견했다.
본 연구에서는 GCN 설계를 단순화해서 정확하고 적절한 추천을 하는 새로운 모델인 LightGCN을 제안하는데, CF를 위한 GCN의 가장 필수적인 컴포넌트 neighborhood aggregation만 포함한다. 자세하게는 유저와 아이템 임베딩을 선형적으로 유저-아이템 상호작용 그래프로 전파하고 모든 레이어의 가중합으로 최종 임베딩을 학습한다.
간단하고 선형적이고 neat한 모델은 구현과 학습이 간단하고, GCN 기반 SOTA 추천 모델인 Neural Graph Collaborative Filtering(NGCF)에 비해 충분한 개선(평균 16.0% 개선)을 보였다.
추가로 LightGCN의 합리성을 증명하기 위해 분석적이고 실험적인 측면의 분석 결과를 제공한다.
Tensorflow와 PyTorch 구현체가 있다.
1 INTRODUCTION
웹 상의 과도한 정보를 alleviate하기 위해, 개인화된 정보 필터링을 수행하는 역할로 추천 시스템이 널리 배포되었다. 추천 시스템의 핵심은 유저가 아이템과 상호작용(클릭, 이용률, 구매 등등)을 할지 예측하는 것이다. CF는 효과적인 개인화 추천을 위한 초기 태스크로 과거의 유저-아이템 상호작용 활용에 초점을 맞춰 예측을 하려한다.
CF의 공통된 패러다임은 유저와 아이템을 표현하는 잠재 요소(임베딩이라는)를 학습하고, 임베딩 벡터에 기반해서 예측을 수행하는 것이다. MF는 초기 모델로, 유저 ID를 그 유저의 임베딩으로 직접적으로 투영한다. 그 후에, 몇 연구 들에서 유저 ID를 그 유저의 과거 상호작용 들로 확장해 입력으로 사용하는 것이 임베딩 퀄리티를 개선하는 것을 발견했다. 예를 들어 ) SVD++는 유저의 레이팅 수치 예측에 유저의 과거 상호작용을 사용하는 이점을 증명했다. Neural Attentive Item Similarity(NAIS)는 상호작용 히스토리 내 아이템 들의 중요도를 구분해서 아이템 랭크 예측을 개선했다.
-
유저-아이템 상호작용 그래프의 관점에서, 이런 개선들이 유저의 서브 그래프 구조를 사용하는 것으로 해석 할 수 있다.
그 유저의 1홉 이웃들로 임베딩 학습을 개선 시킨 것이다.
더 깊은 서브 그래프 구조를 사용하기 위해, Wang et al.은 Graph Convolution Network(GCN)에서 영감을 받아 NGCF를 제안했고 CF에서 SOTA를 달성했다. 임베딩 재정의를 위해 동일한 전파 규칙을 따랐다 : 피처 변환, 그리고 비선형 활성화. NGCF가 훌륭하지만 무겁고 과하다. 많은 연산 들이 당위성 없이 그대로 사용되었다. CF 태스크에 필수적으로 유용하지는 않다. 자세하게는, GCN은 태초부터 어트리뷰트를 가지는 그래프의 노드 분류를 위해 제안되었다.
- 어트리뷰트 그래프의 각 노드는 입력 피처 같은 풍부한 어트리뷰트를 가진다
- 유저-아이템 상호작용 그래프는 각 노드(유저 혹은 아이템)이 원-핫 ID로 표현되고, 추가적인 의미는 가지지 않는다.
이러한 경우, ID 임베딩이 입력으로 주어지고, 여러 개의 비선형 피처 변환 레이어가 수행되는데 이점이 없고, 모델 학습 난이도만 증가 시킨다.
이 주장을 검증하기 위해, NGCF에 추가적인 ablation 연구를 진행하고 결론을 도출했다.
-
GCN을 따른 두 연산 - 피처 변환과 비선형 활성화 -이 NGCF에 기여가 없다는 점이다. 제거 했을 때 상당한 정확도 개선이 있었다.
GNN에서 타겟 태스크에 사용할 가치가 없는 연산을 추가하는 것이 이점이 없고, 오히려 모델 성능을 떨어트리는 것을 반영한다.
실험 결과에 동기부여해서 새로운 모델인 LightGCN을 제안한다. CF를 위해 GCN의 가장 필수적인 컴포넌트인 이웃 집계를 포함한다. 자세하게는, 각 유저(아이템)을 ID 임베딩과 관련시킨 후에, 유저-아이템 상호작용 그래프에 임베딩을 전파해서 임베딩을 재정의한다. 그리고 서로 다른 전파 레이어에서 학습된 임베딩을 가중합으로 조합해 예측을 위한 최종 임베딩을 획득한다. 전체 모델은 단순하고 elegant한데, 학습이 쉬울 뿐만 아니라, NGCF와 Multi-VAE 같은 다른 SOTA 에 비해 더 나은 성능을 달성했다.
요약하자면, 본 연구는 다음 같은 기여가 있다.
- 실험적으로, GCN의 공통적인 설계 중 두가지인 피처 변환과 비선형 활성화가 CF에 긍정적인 효과가 없다는 것을 발견했다
- LightGCN을 제안한다. 추천을 위한 GCN의 가장 필수적인 컴포넌트 만을 포함해서 설계를 단순화한 모델이다
- LightGCN을 NGCF와 비교해 동일한 세팅에서 충분한 개선을 보였다. 자세한 분석 결과로 LightGCN의 합리성을 기술적이고 실험적인 측면에서 보인다.
2 PRELIMINARIES
대표적인 GCN 기반 SOTA 모델 NGCF를 소개한다.
NGCF에 Ablation 연구를 진행해 각 연산의 유용성을 판단한다.
GCN에서 공통적으로 사용되는 두 설계 부분인 피처 변환과 비선형 활성화가 CF에 긍정적인 효과가 없다는 점을 보인다.
2.1 NGCF Brief
첫 스텝에서, 각 유저, 아이템이 ID 임베딩으로 연결되어 있다.
- $e_u^{(0)}$는 유저 $u$의 ID 임베딩
- $e_i^{(0)}$는 아이템 $i$의 ID 임베딩이다.
유저-아이템 상호작용 그래프를 활용해 임베딩을 다음과 같이 전파한다.
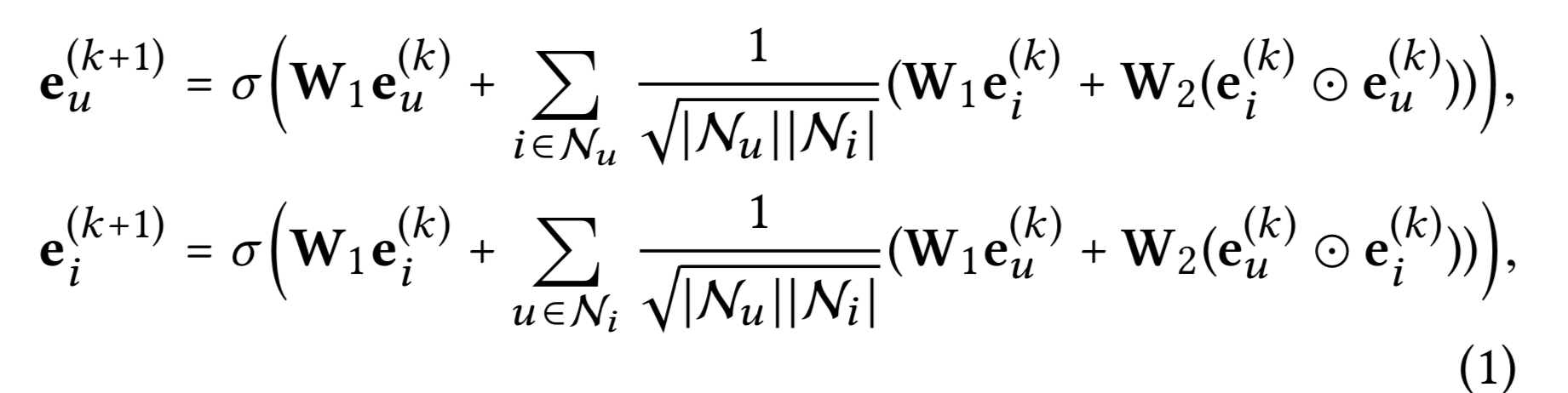
- $e_u^{(k)}$, $e_i^{(k)}$: 유저 $u$와 아이템 $i$의 $k$ 레이어 전파 후의 재정의된 임베딩
- $N_u$ , $N_i$ : 유저 $u$와 상호작용한 아이템 셋. 아이템 $i$와 상호작용한 유저 셋
- $W_1$, $W_2$ : 각 레이어에서 피처 변환을 수행하기 위한 학습 가능한 가중치 행렬
$L$ 번째 레이어에 전파하면, NGCF는 $L+1$ 임베딩을 획득해서 유저( $e_u^{(0)}$, $e_u^{(1)}$, …, $e_u^{(L)}$)와 아이템($e_i^{(0)}$, $e_i^{(1)}$, …, $e_i^{(L)}$)을 묘사한다.
이런 $L+1$ 임베딩을 결합해서 최종 유저 임베딩과 아이템 임베딩을 획득한다.
예측 스코어를 생성하기 위해 내적을 사용한다.
-
NGCF는 표준 GCN을 많은 부분 따랐다. 그러나 CF에서는 필요없다!
비선형 활성화 함수 $\sigma(\cdot)$와 피처 변환 행렬 $w_1$과 $w_2$을 포함한다.
semi-supervised 노드 분류에서는, 제목이나 논문의 추상적인 단어와 같은 각 노드의 풍부한 의미론적 피처를 입력으로 사용한다. 그래서, 여러 레이어의 비선형 변환 수행이 피처 학습에 유용하다.
CF에서는, 유저-아이템 상호작용 그래프의 각 노드에 의미가 없는 ID만 있다.
→비선형 변환을 여러번 수행하는 것은 더 나은 피처 학습에 기여할 수 없다. 심지어, 학습 난이도를 증가시킨다.
다음 섹션에서 이 주장에 대한 실험적 증거를 제공한다.
2.2 Empirical Explorations on NGCF
비선형 활성화와 피처 변환의 효과를 실험한다. NGCF의 저자가 릴리즈한 코드를 그대로 사용하는데, 공정함을 위해 동일한 데이터 분할과 검증 프로토콜을 사용한다.
GCN의 코어가 전파를 통한 임베딩 재정의 이기 때문에, 동일한 임베딩 사이즈에서의 임베딩 퀄리티에 관심이 있다. 그래서, 최종 임베딩 획득하는 방식을 concatenation에서 sum으로 변경했다. 이 변경점이 NGCF의 성능에 큰 영향을 주지 않지만, ablation 연구를 더 indicative하게 만든다.
세가지 간단한 변형체를 구현한다.
- NGCF-f, 피처 변환 행렬 $w_1$, $w_2$를 제거한다.
- NGCF-n, 비선형 활성화 함수 $\sigma$를 제거한다.
- NGCF-fn, 피처 변형 행렬들과 비선형 활성화 함수 모두를 제거한다.
모든 하이퍼 파라미터 들은 NGCF의 최적 세팅과 동일하게 사용한다. Gowalla와 Amazon-Book 데이터셋에서 2-레이어 세팅 결과를 테이블 1에 리포트한다.
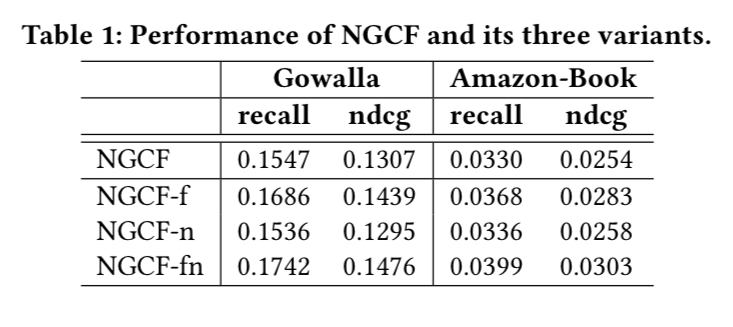
피처 변형을 제거한 버전(NGCF-f)은 세가지 데이터셋 모두에서 NGCF와 비교해 상당한 개선을 달성했다.
반대로, 비선형 활성화를 제거한 버전은 정확도에 그정도로 영향을 미치지는 못했다.
그러나 피처 변형(NGCF-fn)에 기반해 비선형 활성화를 제거한다면, 성능이 상당히 개선 되었다.
따라서 결론은 다음과 같다.
- 피처 변환이 NGCF에 부정적인 효과를 impose하는데, 그 이유는 NGCF와 NGCF-n 모델 들에서 제거하는 것이 성능을 상당히 많이 개선 했기 때문이다.
- 비선형 활성화 추가는 피처 변환 시에는 영향력이 적지만, 피처 변환을 하지 않을 때는 부정적인 효과를 impose한다.
- 전체적으로, 피처 변환과 비선형 활성화는 NGCF에 부정적인 효과를 impose한다. 그 이유는 동시에 제거 했을 때, NGCF-fn이 NGCF에 대해 상당한 개선(recall에서 상대적으로 9.57%)을 달성했기 때문이다.
왜 NGCF가 두 연산으로 deteriorates 하는지 이해하기 위해, 학습 로스와 테스트 recall로 모델 상태 커브를 그림 1에 그린다.
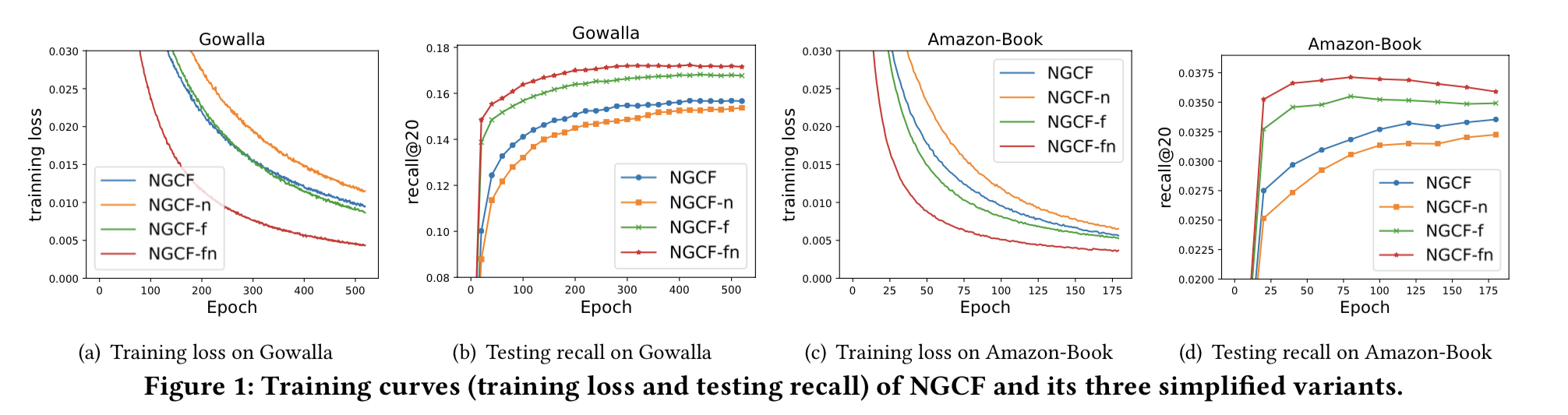
- NGCF-fn은 NGCF, NGCF-f 그리고 NGCF-n에 비해 학습 로스가 전체 과정에서 훨씬 적다.
- 테스팅 recall로 커브를 나열하면, 낮은 학습 로스가 성공적으로 정확도로 전이 된 것이 보인다.
- NGCF와 NGCF-f 간의 비교는 개선 정도가 더 작다는 것을 제외하고는 유사하다.
이러한 근거들로 부터, NGCF의 성능 저하는 오버피팅이 아니라 학습의 어려움이라 결론낼 수 있다.
-
이론적으로는 NGCF가 NGCF-f 보다 표현력 좋아야 한다.
가중치 행렬 $w_1$, $w_2$를 identity 행렬 $I$로 세팅하는 것으로 NGCF-f 모델을 recover할 수 있기 때문이다.
그러나, 실제에서는, NGCF가 NGCF-f에 비해 더 높은 학습 로스를 가지고 일반화 성능이 떨어졌다. 그리고 비선형 활성화의 incorporation이 표현력과 일반화 성능 간의 차이를 aggravate 한다.
-
추천을 위한 모델을 설계할 때, 각 연산의 효과를 분명하게 하기 위해 엄격한 ablation 연구가 필요하다!
상대적으로 유용하지 않은 연산 들을 포함 시키는 것이 모델을 불필요하게 복잡하게 해서, 학습 난이도를 증가시키고, 모델의 성능을 저하시킨다.
3 METHOD
단순화의 장점은 몇가지가 있다.
- 해석 가능성이 높아진다
- 학습과 유지보수가 쉬워진다
- 모델의 동작을 기술적으로 분석하기 쉬워진다
- 효과적인 방법으로 revise 하기 쉬워진다
이 섹션에서는 그림 2에 설명된 것 같이 Light Graph Convolution Network (LightGCN) 모델을 제안한다.
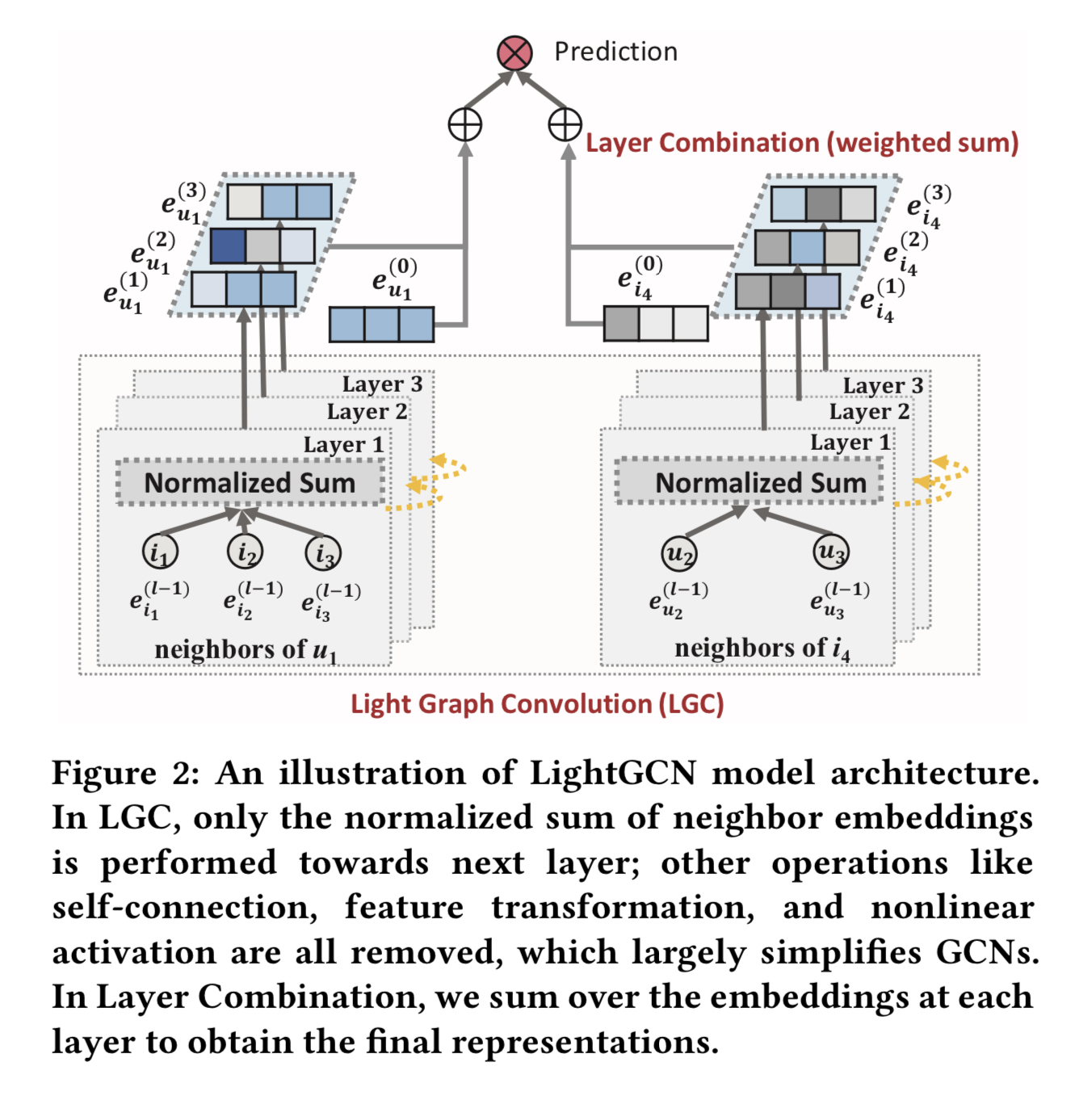
3.1 LightGCN
GCN의 기본 아이디어 : 그래프에 대해 피처들을 스무딩해서 노드 들의 표현을 학습
이를 위해, 그래프 컨볼루션을 반복적으로 수행한다. 즉, 이웃의 피처로 타겟 노드의 새로운 표현을 생성한다.
이러한 이웃 집계는 다음과 같이 추상화 될 수 있다.
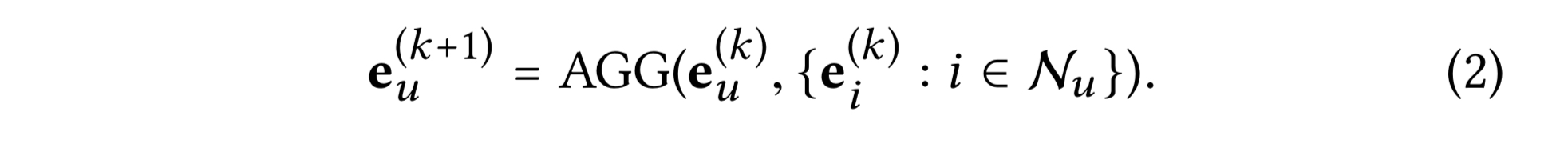
- AGG : 그래프 컨볼루션의 핵심인 집계함수
타겟 노드의 k번째 레이어에서의 표현과 그 이웃 노드들을 다룬다. 많은 연구들이 특화된 AGG를 가진다.
- GIN : 가중 합 집계기
- GraphSAGE :LSTM 집계기
- BGNN : bilinear 상호작용 집계기 등등
그러나 대부분의 연구는 피처 변환 혹은 비선형 활성화와 AGG 함수가 묶여있다. 의미가 있는 입력 피처 들을 가지는 노드 혹은 그래프 분류 태스크에서는 성능이 좋았을 수도 있지만, CF에서는 burdensome 할 수 있다.
3.1.1 Light Graph Convolution (LGC)
단순한 가중합 집계기를 적용하고 피처 변환과 비선형 활성화를 금지한다. LightGCN에서 정의된 그래프 컨볼루션 연산(전파 규칙)은 다음과 같다.
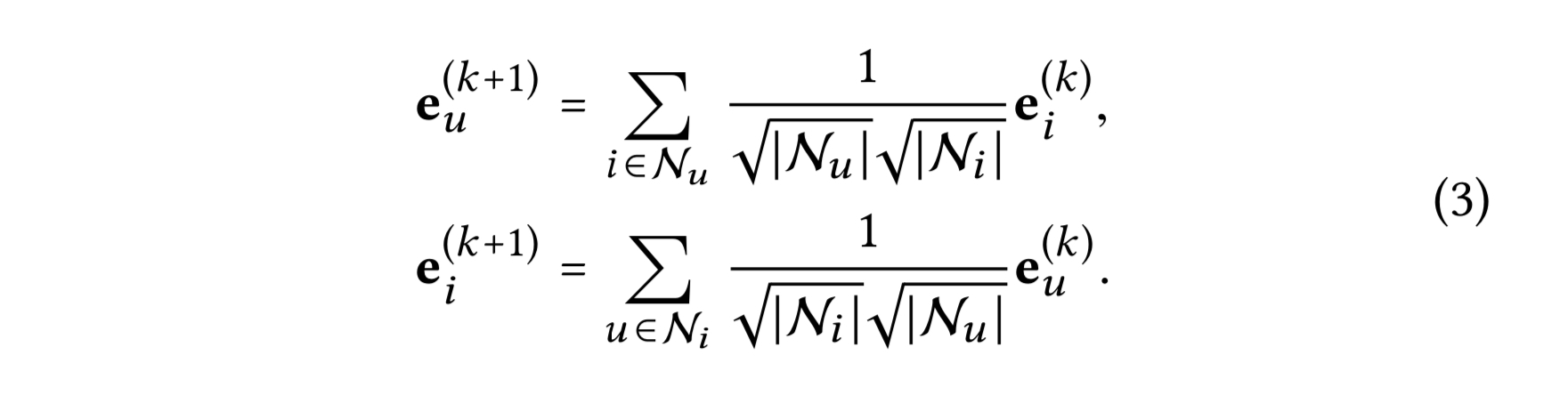
대칭 정규화 텀 $\frac{1}{\sqrt{|N_u|}\sqrt{|N_i|}}$는 표준 GCN의 설계를 따르는데, 임베딩 스케일이 그래프 컨볼루션과 함께 증가하는 것을 회피할 수 있다. $L_1$ 정규화도 적용될 수 있는데, 실험적으로 이 대칭 정규화의 성능이 좋았다.
LGC에서 연결된 이웃 들만을 집계하고 타겟 노드 그 자체(셀프 커넥션)는 통합하지 않는 것 이 더 좋다. 기존의 대부분의 그래프 컨볼루션 연산이 셀프 커넥션을 별도로 처리 하는 것과는 다르다.
다음 섹션에서 소개 될 레이어 조합 연산이 셀프 커넥션과 같은 효과를 가진다. 그래서 LGC에서는 셀프 커넥션이 필요하지 않다.
3.1.2 Layer Combination and Model Prediction
LigntGCN 모델에서 학습 가능한 모델 파라미터는 0번째 레이어의 임베딩 들이다. 즉 모든 유저 들에 대해 $e_u^{(0)}$ 그리고 모든 아이템 들에 대해 $e_i^{(0)}$이다. 그것들이 주어졌을 때, 더 높은 레이어들의 임베딩 들은 LGC의 수식 3에 정의된 방식으로 계산 될 수 있다.
LGC의 $K$ 레이어 후에, 각 레이어에서 획득한 임베딩을 조합해서 유저(혹은 아이템)의 최종 표현을 형성한다.
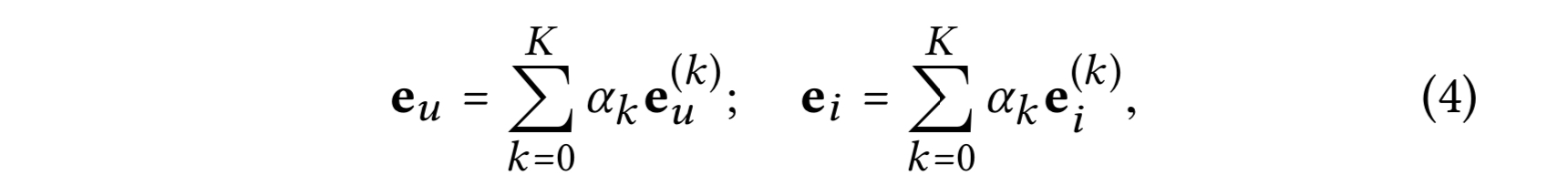
- $\alpha_k ≥ 0$ : 최종 임베딩을 구성하는 $k$번째 레이어 임베딩의 중요도이다. 메뉴얼하게 하이퍼 파라미터로 튜닝을 해도 되고, 자동적으로 어텐션과 같이 모델 파라미터로 학습해도 된다.
실험으로, $\alpha_k$를 유니폼하게 $1/(K+1)$로 세팅하는 것이 일반적으로 좋은 성능을 보이는 것을 발견했다. 그래서 $\alpha_k$ 최적화를 위한 별도의 컴포넌트를 설계하지 않았다. LightGCN을 불필요하게 복잡하지 않고 단순함을 유지한다.
최종 표현을 얻기 위해 레이어 결합을 수행하는 이유가 세가지 있다.
-
레이어 수가 증가 할수록, 임베딩이 오버 스무딩 될 것이다. 그래서 마지막 레이어만 사용하는 것은 문제가 있다.
-
서로 다른 레이어의 임베딩 들은 서로 다른 의미를 담고 있다.
- 첫번째 레이어는 상호작용을 가지는 유저와 아이템의 smoothness를 강제하고,
- 두번째 레이어는 상호작용한 아이템(유저)이 서로 겹치는 유저(아이템) 들을 smooth 하고,
- 더 높은 레이어는 고차 proximity를 담는다.
그래서 임베딩 들을 결합하는 것이 표현을 더 comprehensive하게 만든다.
-
서로 다른 레이어 들의 임베딩 들을 가중합으로 결합하면 셀프 커넥션이 있는 그래프 컨볼루션 효과를 포함하는데 GCN에서는 중요한 트릭이다.
모델 예측은 유저와 아이템의 최종 표현 들의 내적으로 정의된다.
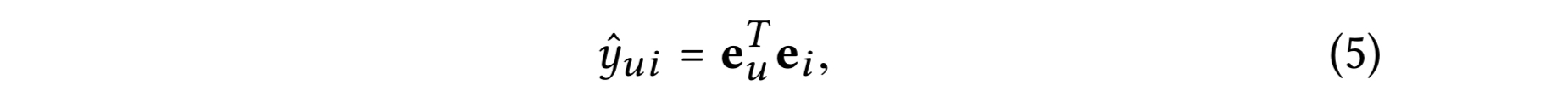
추천을 위한 랭킹 스코어로 사용된다.
3.1.3 Matrix Form
유저-아이템 상호작용 행렬을 $R \in R^{M \times N}$으로, 여기서 $M$은 유저 수, $N$은 아이템 수다. 엔트리 각각은 $R_{ui}$로 $u$가 아이템 $i$와 상호작용을 했다면 1이고 아니면 0이다. 그러면 획득하는 유저-아이템 그래프의 인접 행렬은 다음과 같다.
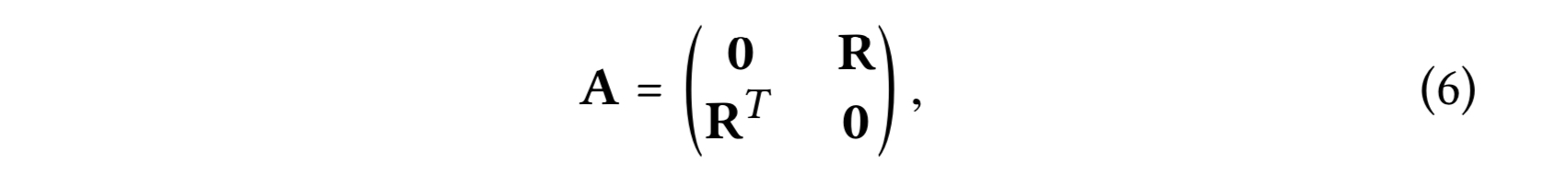
0번째 레이어의 임베딩 행렬은 $E^{(0)} \in R^{(M+N) \times T}$로 한다. $T$는 임베딩 사이즈이다. 그러면 다음과 같은 LGC의 matrix equivalent form을 얻을 수 있다.
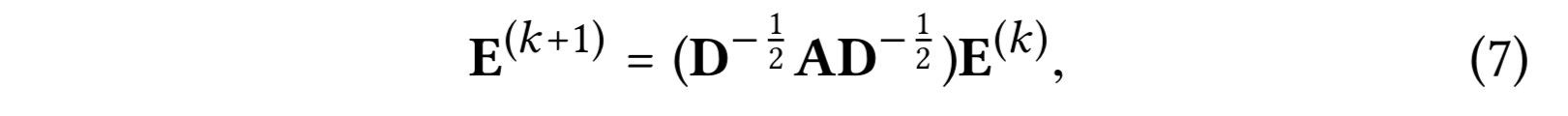
- D : $(M+N) \times (M+N)$인 대각 행렬로 $D_{ii}$는 인접 행렬 A(degree 행렬이라고 도 한다)의 $i$번째 행 벡터 중에서 0이 아닌 엔트리들의 수를 의미한다.
마지막으로, 모델 예측에 사용할 최종 임베딩 행렬을 얻는다.
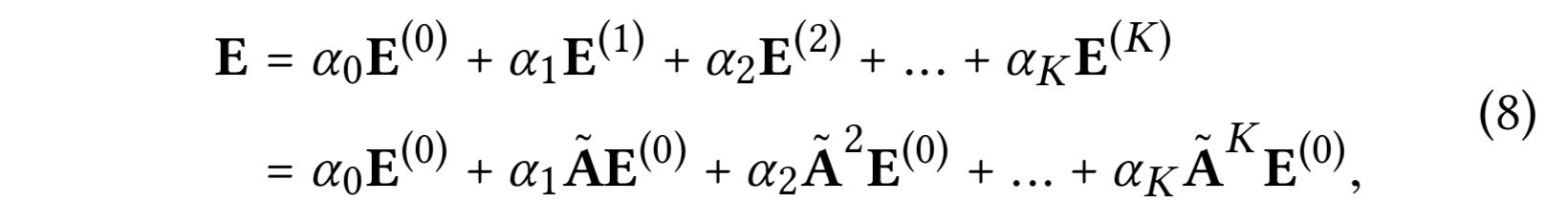
$\hat{A} = D^{-\frac{1}{2}}AD^{-\frac{1}{2}}$은 대칭 정규화 행렬이다.
3.2 Model Analysis
Simplified GCN(SGCN)과의 관련성에 대해서 의논한다. 선형 GCN 모델로 셀프 커넥션을 그래프 컨볼루션으로 통합했다; LightGCN이 레이어 조합으로 셀프 커넥션 효과를 포함시켰기 때문에 이 분석으로 인접 행렬에 셀프 커넥션을 따로 포함할 필요가 없다는 것을 보인다.
그리고 Approximate Personalized Propagation of Neural Predictions (APPNP)와의 관계에 대해 논의한다. 오버 스무딩을 해결 하기 위해 Personalized PageRank의 방식을 사용한 GCN의 변형체다. 분석 결과로 LightGCN과 APPNP가 동등함을 보이고, 그래서 LightGCN이 제어 가능한 오버스무딩으로 장기적인 범위로 전파하는 이점이 있다고 한다.
마지막으로, LGC의 두번째 레이어를 분석해서 유저를 그 유저의 이차 이웃과 스무딩하는 방법을 보이고, LightGCN의 동작 메커니즘에 대한 인사이트를 제공한다.
3.2.1 Relation with SGCN
SGCN의 저자는 노드 분류에서 GCN의 불필요한 복잡성을 주장하고 SGCN을 제시했는데, 비선형성을 제거하고 가중치 행렬 들을 하나의 가중치 매트릭스로 collapsing 해서 GCN을 단순화한다. SGCN의 그래프 컨볼루션은 다음과 같이 정의된다.
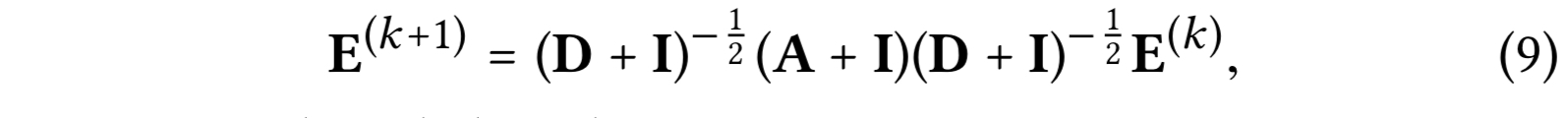
$I \in R^{(M+N) \times (M+N)}$ : 단위 행렬로, $A$에 셀프 커넥션을 포함시킨다. 분석 결과를 따라 $(D+I)^{-\frac{1}{2}}$ 텀을 단순화를 위해 omit하는데, 임베딩을 리스케일만 하기 때문이다. SGCN에서 마지막 레이어에서 획득한 임베딩이 다운스트림 태스크인 예측에 사용되고 다음과 같이 표현된다.
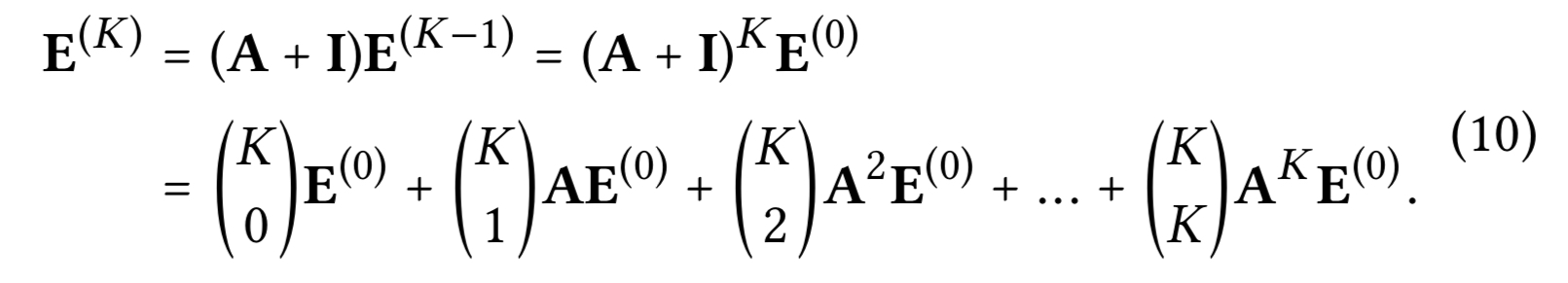
위의 전개는 셀프 커넥션을 $A$에 추가하고 이것에 임베딩을 전파하는 것은 LGC 레이어 각각에 전파된 임베딩 들의 가중합과 동일하다는 것을 보인다.
3.2.2 Relation with APPNP
APPNP는 개인화된 PageRank와 GCN을 연결하는데, 오버 스무딩에 대한 리스크 없이 장기적인 전파가 가능하다. 개인화된 PageRank의 teleport 디자인에 영감을 받아, APPNP는 각 전파 레이어를 스타팅 피처(즉 0번째 임베딩)와 complement 하는데, 지역성을 보존할 필요성을 밸런싱(오버스무딩을 완화하기 위해 루트 노드와 가깝게 둔다) 할 수 있고 그리고 거대한 이웃으로 부터의 정보를 활용한다. APPNP의 전파 레이어는 다음과 같이 정의된다.
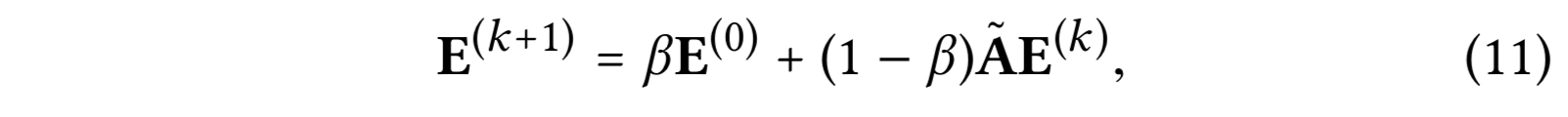
- $\beta$ : 전파에서 스타팅 피처들의 retaining을 컨트롤하는 teleport 확률
- $\hat{A}$ : 정규화된 인접 행렬
APPNP의 마지막 레이어는 최종 예측에 사용된다.
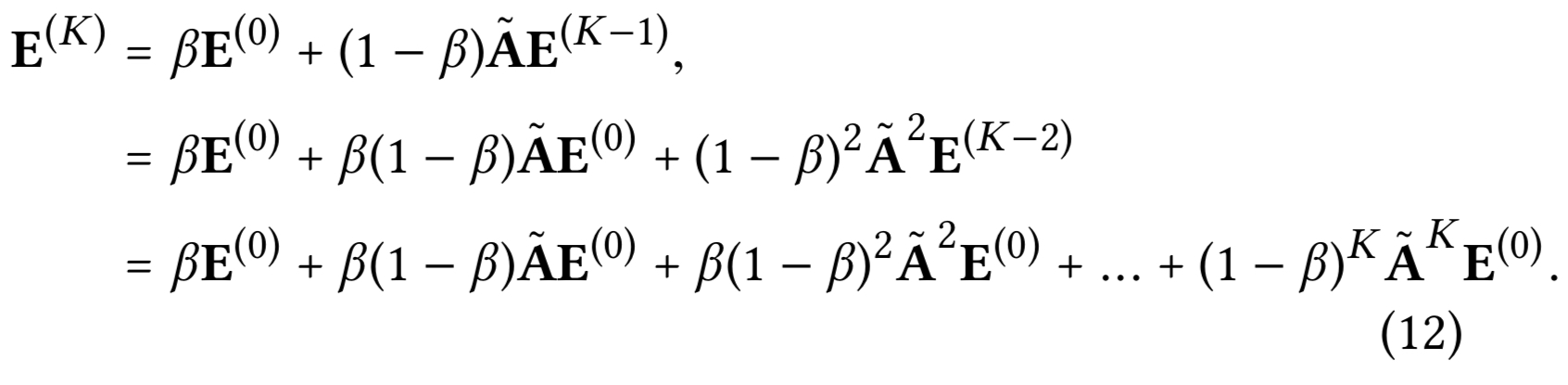
수식 (8)과 Aligning하면, $\alpha_k$를 세팅함에 따라서, LightGCN은 APPNP에서 사용하던 예측 임베딩을 완전히 recover할 수 있다. 따라서, LightGCN은 오버 스무딩을 방지하는 APPNP의 강점을 공유한다. — $\alpha$를 적절히 세팅해서, 컨트롤 가능한 오버 스무딩으로 장기 모델링을 위한 거대한 $K$를 사용할 수 있다.
마이너한 차이는 APPNP는 셀프 커넥션을 인접 행렬에 추가하는 것이다. 그러나 이전에 보였듯, 서로 다른 레이어조합으로 의미가 없어진다.
3.2.3 Second-Order Embedding Smoothness
LightGCN의 선형성과 단순함으로, 임베딩을 어떻게 스무딩 하는지 인사이트를 얻을 수 있다. 2 레이어 LightGCN을 분석해서 합리성을 증명한다. 예로) 유저 사이드를 취한다. 직관적으로 둘째 레이어는 유저를 스무딩하는데 상호작용한 아이템이 겹치는 유저들이다. 정확하게는 다음을 가진다.
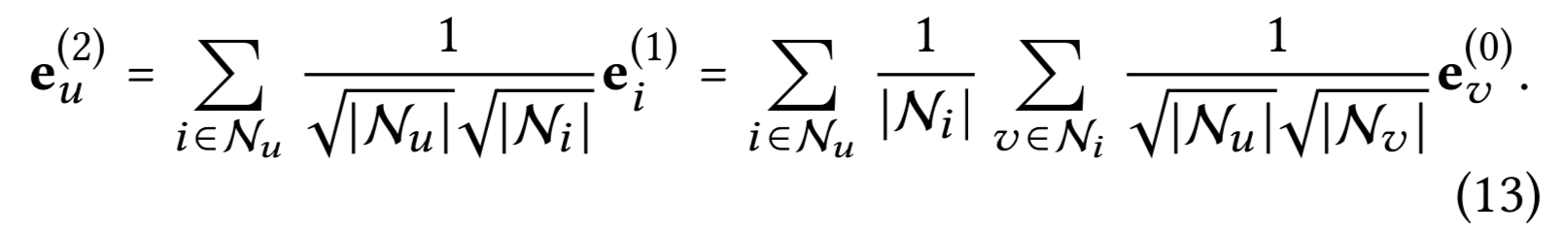
또다른 유저 $v$가 타겟 유저 $u$와 함께 상호작용을 하면, $u$에 대한 $v$의 스무딩 강도는 계수에 의해 측정된다. (상호작용이 없으면 0)
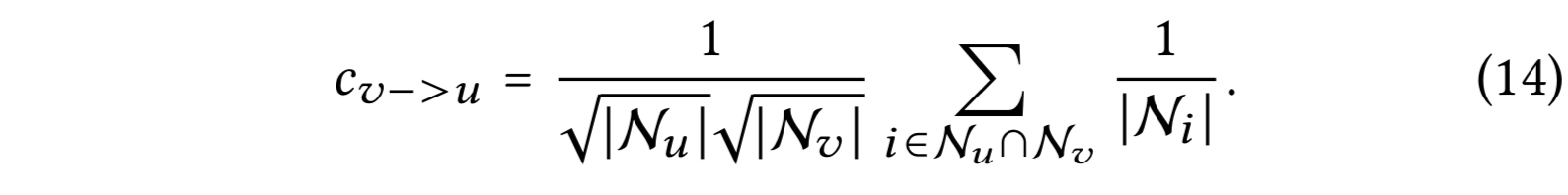
계수는 해석 가능하다 : $u$의 이차 이웃 $v$의 영향도는 다음에 의해서 결정되는데
- 동시에 상호작용한 아이템들의 수, 많을 수록 커진다.
- 동시에 상호작용한 아이템의 유명도, 유명하지 않을 수록 커진다. ( 유저의 개인적인 선호도를 더 잘 표현한다 )
- $v$의 액티비티, 활성도가 낮을 수록 커진다.
이러한 해석 가능도가 유저 유사도 측정에 있어 CF의 가정을 충족시키고 LightGCN의 타당성을 입증하는 근거가 된다. LightGCN의 대칭 공식으로, 아이템 측면에서도 유사도 분석 결과를 얻을 수 있다.
3.3 Model Training
LightGCN의 학습 가능한 파리미터는 0번째 레이어의 임베딩이 유일하다. 다르게 말하면, 모델 복잡도가 표준 MF와 같다.
-
Bayesian Personalized Ranking(BPR) 로스를 적용한다.
관측된 엔티티를 미관측 엔티티 보다 높게 만든다.
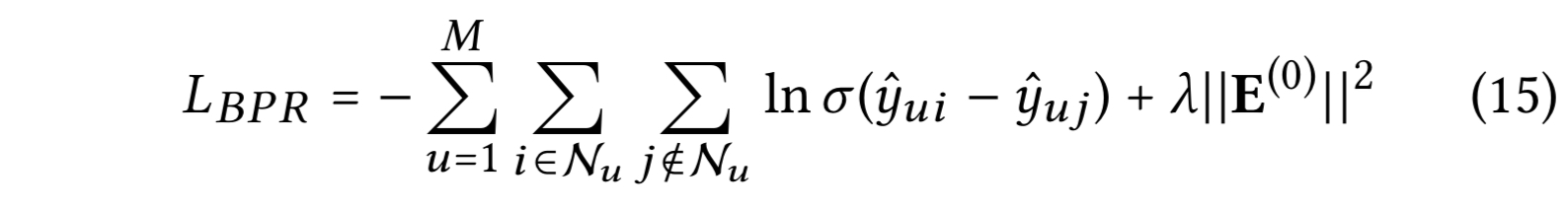
- $\lambda$ : $l_2$ 정규화 강도를 조절한다.
Adam 옵티마이저를 적용한 미니 배치 방식을 사용한다. lightGCN을 개선할만한 hard negative sampling과 adversarial sampling 같은 네거티브 샘플링 전략들이 있지만, 추후 연구로 남겨둔다.
-
GCN 들이나 NGCF에서 공통적으로 사용한 드롭아웃을 적용하지 않는다.
LigntGCN에는 피처 변환 가중치 행렬이 없기 때문이다. 그래서 임베딩 레이어에 적용한 $L_2$ 정규화가 오버피팅 방지에 충분하다.
노드 드롭아웃과 메시지 드롭아웃 비율을 조절할 필요가 없어 NGCF에 비해 학습과 튜닝이 간단하다. 그리고 각 레이어의 임베딩을 유닛 길이로 정규화한다.
게다가, 레이어 조합 계수 ${{ \alpha_k}}_{k=0}^K$를 학습하는 것도 기술적으로 가능하고 혹은 어텐션 네트워크로 파라미터화 하는 것도 기술적으로 가능하다. 그러나, 학습 데이터로 $\alpha$를 학습하는 것이 성능 개선 효과가 없다는 것을 발견했다. 아마도 학습 데이터가 알려지지 않은 데이터에서 일반화를 할 정도로 좋은 $\alpha$를 학습할 정도의 충분한 시그널을 포함하지 못했기 때문이다. 검증 데이터셋에서 학습 하는 시도를 했으나, 성능이 약간 개선(1% 내) 되었다. 최적의 $\alpha$를 찾는 것은 추후 연구로 남긴다.
4 EXPERIMENTS
실험 세팅에 대해 설명하고 NGCF와 자세한 비교를 수행한다. NGCF는 LightGCN과 가장 관련성이 높지만, 더 복잡하다.
다음으로 다른 SOTA 메소드들과 비교한다. LightGCN의 디자인을 정당화 하고 효과성의 근거를 알린다. ablation 연구와 임베딩 분석을 수행한다.
하이퍼 파라미터 연구를 최종적으로 진행한다.
4.1 Experimental Settings
실험 데이터셋에 대한 통계치는 테이블 2에 있다.
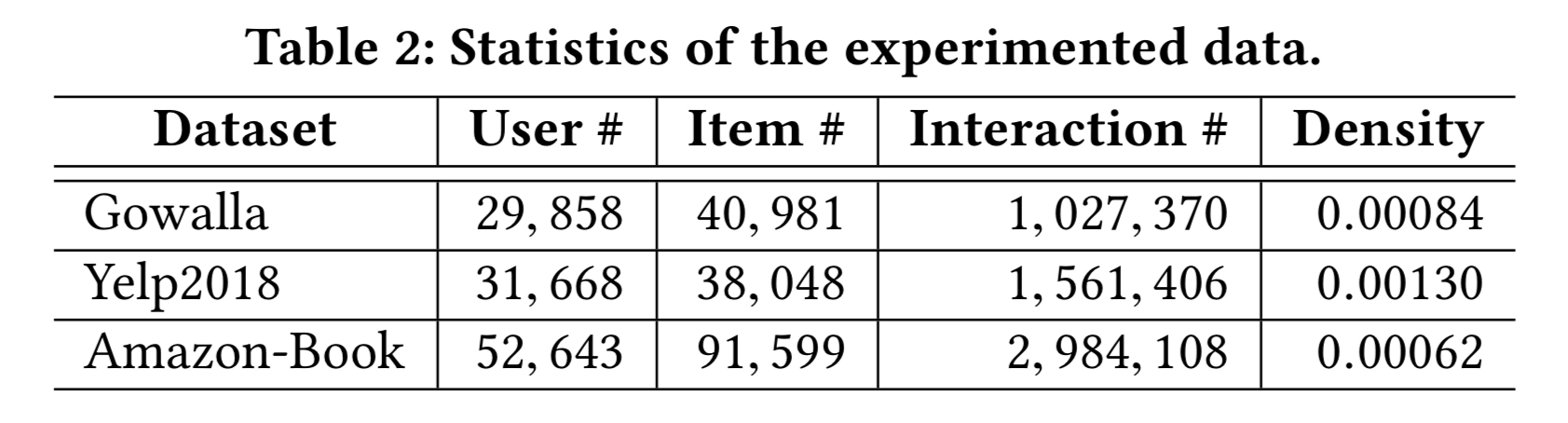
Gowalla와 Amazon-Book는 NGCF 논문에서 사용한 세팅과 동일한 세팅으로 비교를 진행하고 NGCF의 결과를 그대로 사용한다.
Yelp 2018 데이터는 예외로 하는데 개정된 버전이다. 저자에 따르면 이전 버전은 테스트 셋에서 콜드 스타트 아이템을 필터링 하지 않은 버전이고, 개정된 버전만을 공유 받았다. 따라서 Yelp 2018 데이터에서 재 실행 했다.
검증 메트릭은 recall@20과 ndcg@20을 사용했다. — 유저와 상호작용 하지 않은 모든 아이템 들이 후보 아이템이다.
4.1.1 Compared Methods.
주로 비교하는 메소드는
- GCN : NGCF, GC-MC와 PinSage,
- Neural Network : NeuMF와 CMN
- MF : MF와 HOP-Rec
LightGCN의 성능이 우월했다.
추가로, 관련성 이있고 경쟁력 있는 두가지 CF 메소드와 비교했다.
- Multi-VAE: Variational autoencoder 기반의 아이템 기반 CF 메소드다.
- GRMF : 그래프 라플라시안 정규화기를 추가해서 매트릭스 팩토라이제이션을 스무딩한다.
4.2 Performance Comparison with NGCF
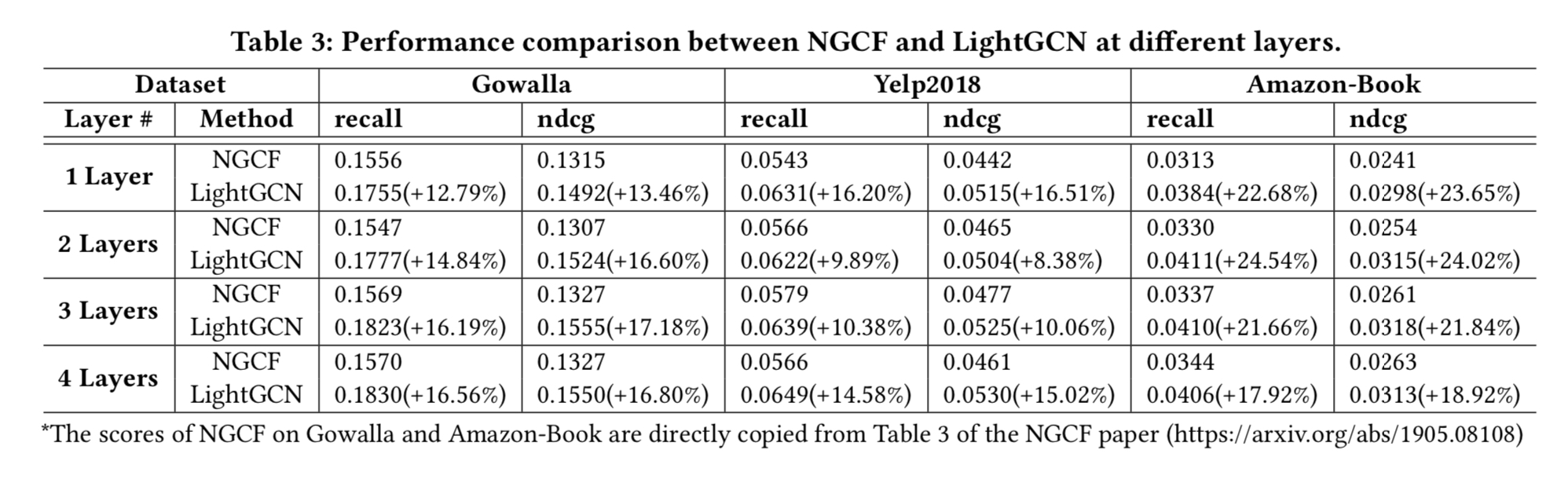
NGCF와 자세한 비교를 했다. 서로 다른 레이어 (1-4)에서의 성능을 테이블 4에 기록한다.
그리고 학습 과정 상의 학습 로스와 테스팅 recall을 그림 3에 그린다.
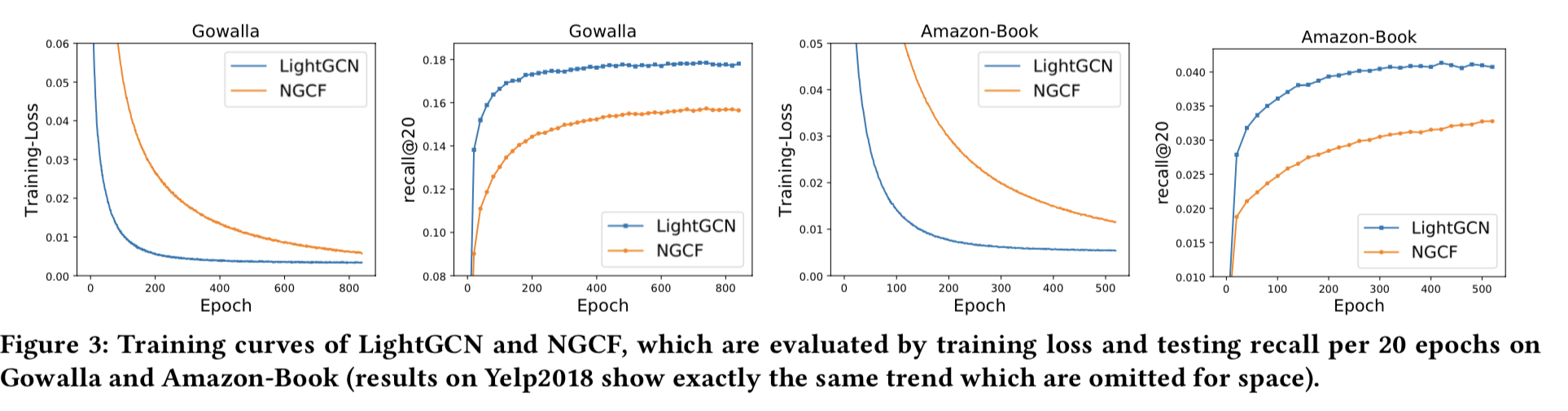
- 모든 경우에서, LightGCN이 NGCF에 비해 큰 마진으로 성능이 좋았다.
- 테이블 4와 섹션 2의 테이블 1을 함께 보면, LightGCN이 피처 변환과 비선형 활성화를 제거한 NGCF-fn에 비해 성능이 좋다. NGCF-fn이 여전히 LightGCN 보다 더 많은 연산(셀프 커넥션, 그래프 컨볼루션 내 유저 임베딩과 아이템 임베딩 간의 상호작용, 드롭아웃)을 포함하기 때문이다. 이 연산 들도 가치가 없다는 걸 제안한다.
- 레이어 수를 증가 시켜 성능을 개선할수 있으나 장점이 사라졌다. 레이어 3개가 만족할만한 성능을 대부분에서 보였다. NGCF에서도 그랬었다.
- LightGCN이 학습 로스가 낮은데, 학습 데이터에 더 잘 fit 했다는 것이다. 게다가 낮은 학습 로스가 더 나은 테스트 정확도로 전이되는 것으로, 일반화도 LightGCN이 더 강력했다는 것을 나타낸다.
4.3 Performance Comparison with State-of-the-Arts
테이블 4가 다른 메소드와의 성능 비교를 보인다.
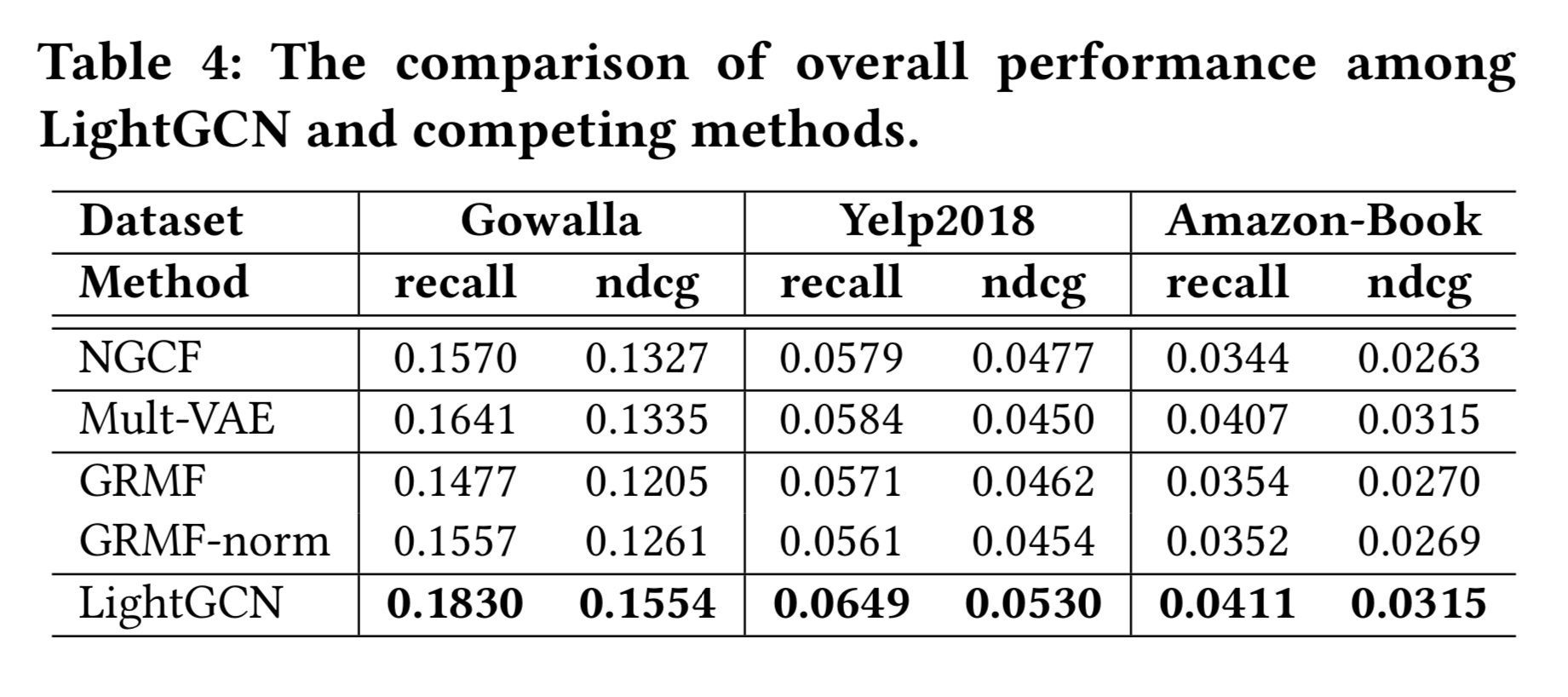
세 데이터셋 모두에서 LightGCN이 결과가 가장 좋다. $\alpha_k$를 튜닝했다면, 더 개선 가능하지만, 유니폼한 세팅 값 $\frac{1}{K+1}$을 오버 튜닝을 피해서 사용했다.
4.4 Ablation and Effectiveness Analyses
레이어 조합과 대칭 루트 정규화의 효과를 보인다. 추가로 임베딩 스무딩의 효과를 조사한다.
4.4.1 Impact of Layer Combination
그림 4는 LightGCN과 변형으로 레이어 조합을 사용하지 않는 LightGCN-single의 결과를 보인다.
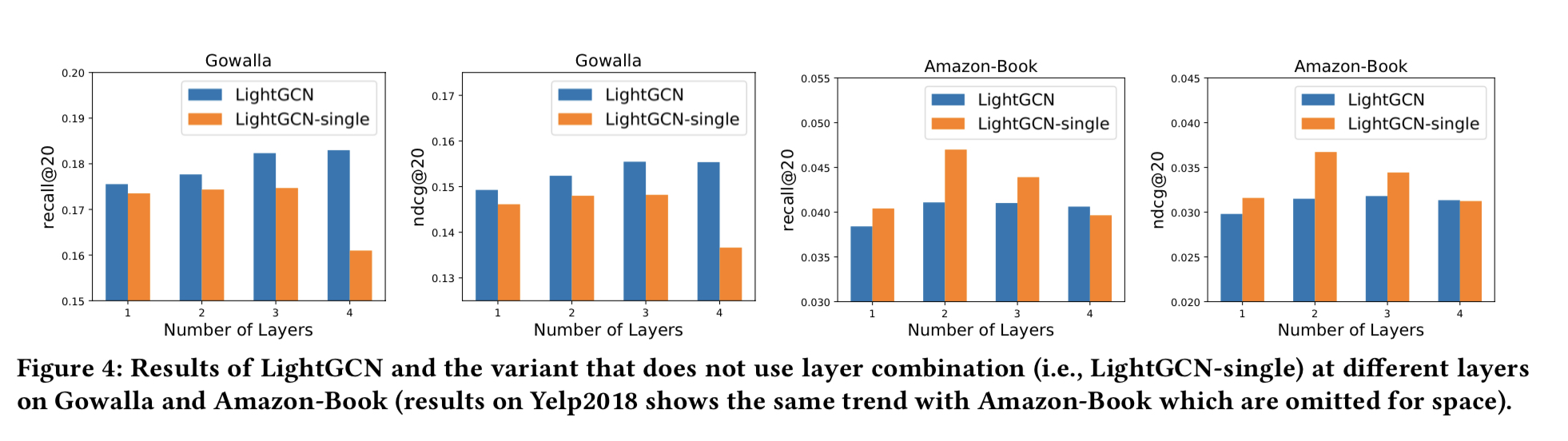
즉 K 레이어 LightGCN에서 $E^{(K)}$가 최종 예측에 사용된다. 세가지 주요한 발견이 있다.
- LightGCN-single에 집중하면, 초기에 성능이 증가하지만 레이어 수가 증가하면서 성능이 감소한다. 레이어 두개 일 때, 성능이 피크다. CF에는 일-이차 이웃까지가 유용하다는 것을 나타낸다. 이웃 차수가 높아질 수록 오버스무딩 된다.
- LightGCN에 집중하면, 레이어 수가 증가함에 따라 성능이 점진적으로 증가한다. 오버 스무딩에 대한 레이어 조합의 효과를 뒷받침 한다.
- 두 메소드를 비교하면, Gowalla에서만 LightGCN이 LightGCN-single에 비해 성능 개선이 있다. 여기서 고려할 점은 LightGCN-single은 LightGCN에서 $\alpha_k$ 하나가 1이고 나머지 $\alpha_k$가 0인 특수한 경우이다. $\alpha_k$를 최적화 하면 LightGCN의 성능이 더 높아질 것이다.
4.4.2 Impact of Symmetric Sqrt Normalization
LightGCN에서 대칭 루트 정규화 $\frac{1}{\sqrt{|N_u|}\sqrt{|N_i|}}$를 각 이웃 임베딩에 이웃 집계를 수행할 때 적용한다. 합리성을 연구하기 위해, 다른 선택을 탐색한다. 정규화를 왼쪽(타겟 노드의 계수)과 오른쪽(이웃 노드의 계수) 으로만 수행한다. $L_1$ 정규화도 제곱근을 제거해서 테스트한다. 정규화를 제거하면 학습이 대수적으로 불안정해지고 NAN 이슈가 발생한다. 그래서 정규화를 제거할 수는 없다. 테이블 5에서 3 레이어 LightGCN에서의 결과를 보인다.
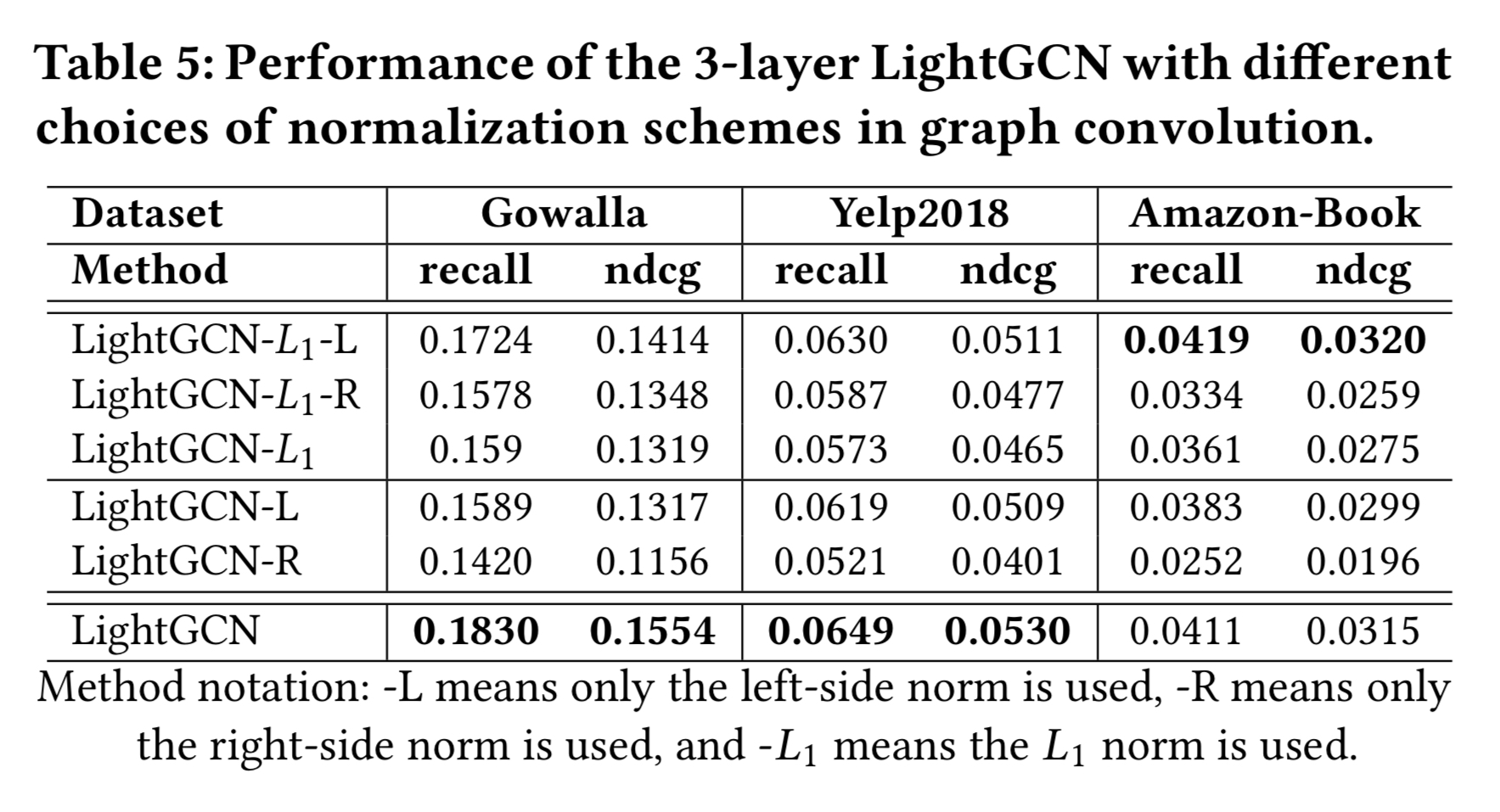
다음과 같은 발견이 있었다.
- 어느 쪽의 제거해도 성능이 떨어진다.
- 두번째가 왼쪽에만 $L_1$ 정규화를 사용하는 것(LightGCN-$L_1$-$L$)이다. in-degree로 인접 행렬을 확률 행렬로 정규화 하는 것과 동일하다.
- 두쪽을 대칭적으로 정규화하는 것이 제곱근 정규화에 도움이 되지만 $L_1$ 정규화의 성능은 감소될 것이다.
4.4.3 Analysis of Embedding Smoothness
2 레이어 LightGCN은 유저 임베딩을 스무딩 할 때, 그 유저와 상호작용한 아이템과 겹치는 유저를 기반으로 스무딩할 것이다. 그리고 두 유저 들간의 스무딩 강도 $c_{v→u}$는 수식 (14)에서 측정된다. 추측 하건대 임베딩 스무딩은 LightGCN의 효과성의 주요한 근거다. 증명을 위해, 유저 임베딩의 스무딩 정도를 다음과 같이 정의한다
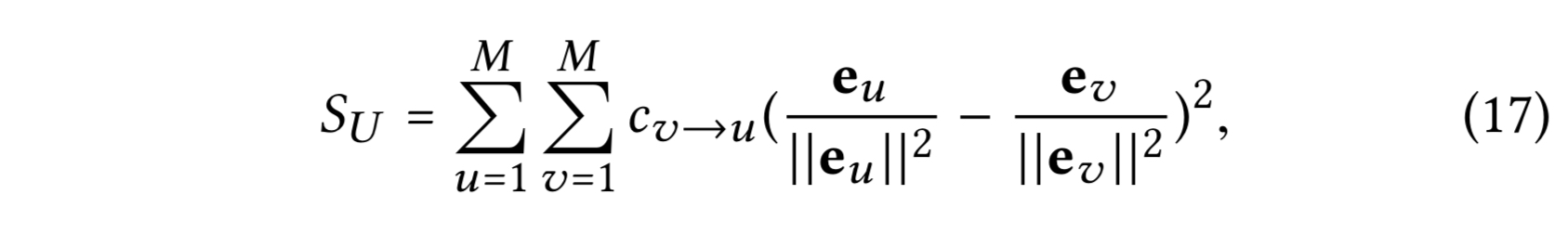
임베딩에 $L_2$ 정규화를 하는 것은 임베딩의 스케일의 효과를 제거하기 위해 사용 되었다. 아이템 임베딩도 유사하게 얻을 수 있다. 테이블 6에서 MF($E^{(0)}$)와 2 레이어 LightGCN($E^{(2)}$) 두 모델의 스무스한 정도를 보인다.
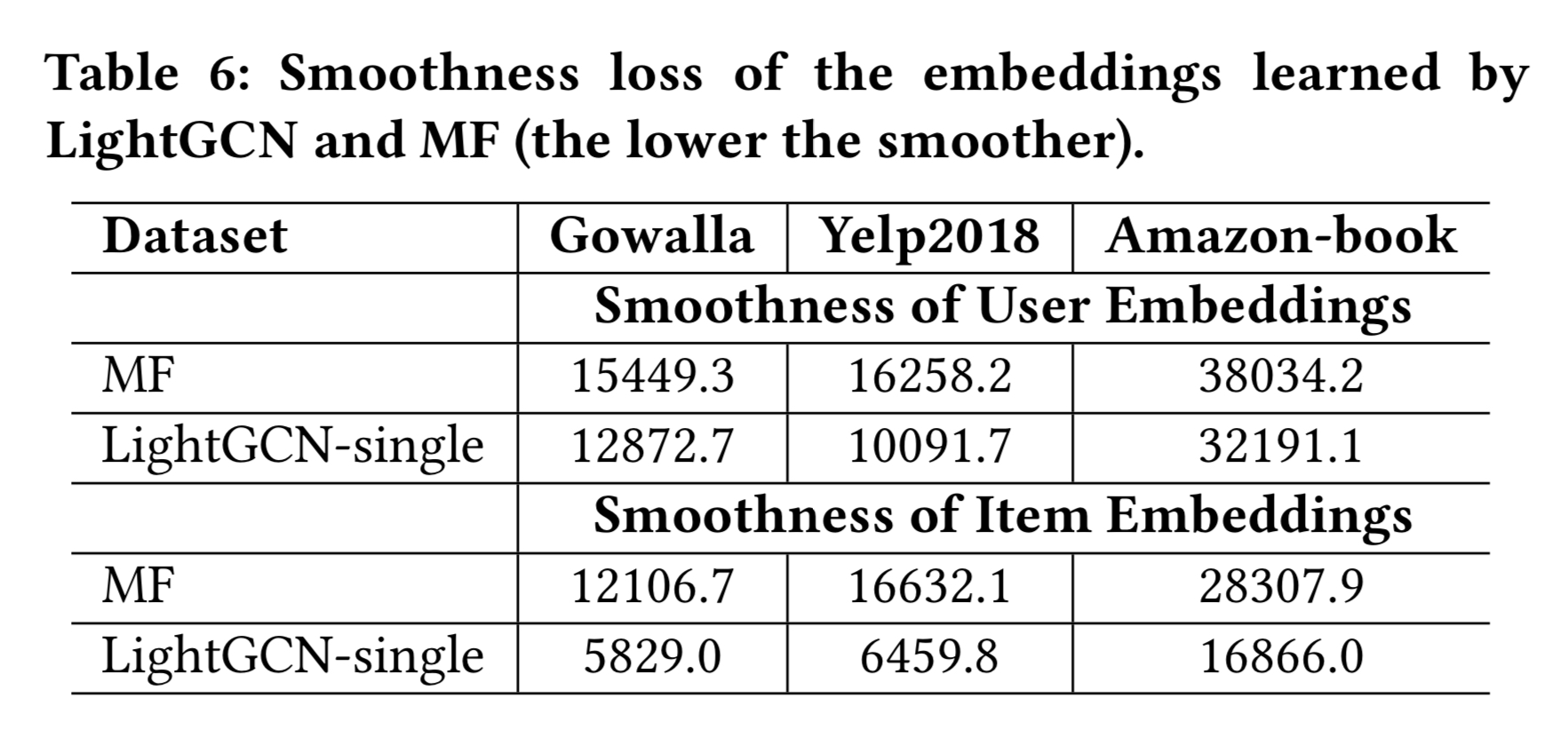
우리는 LightGCN이 MF에 비해 큰 마진으로 추천 정확도가 높다는 사실을 이미 알고 있다. LightGCN-single의 smoothness loss도 MF에 비하면 훨씬 낮다.
해석하자면, 가벼운 그래프 컨볼루션을 수행하는 것이 추천을 위해서는 임베딩을 smoother하고 더 적합하게 만든다.
4.5 Hyper-Parameter Studies
새로운 데이터셋에 LightGCN을 적용할 때, 표준 하이퍼 파라미터인 learning rate 외의 가장 중요한 하이퍼 파라미터는 $L_2$ 정규화 계수 $\lambda$이다.
그림 5에서 볼 수 있듯이,
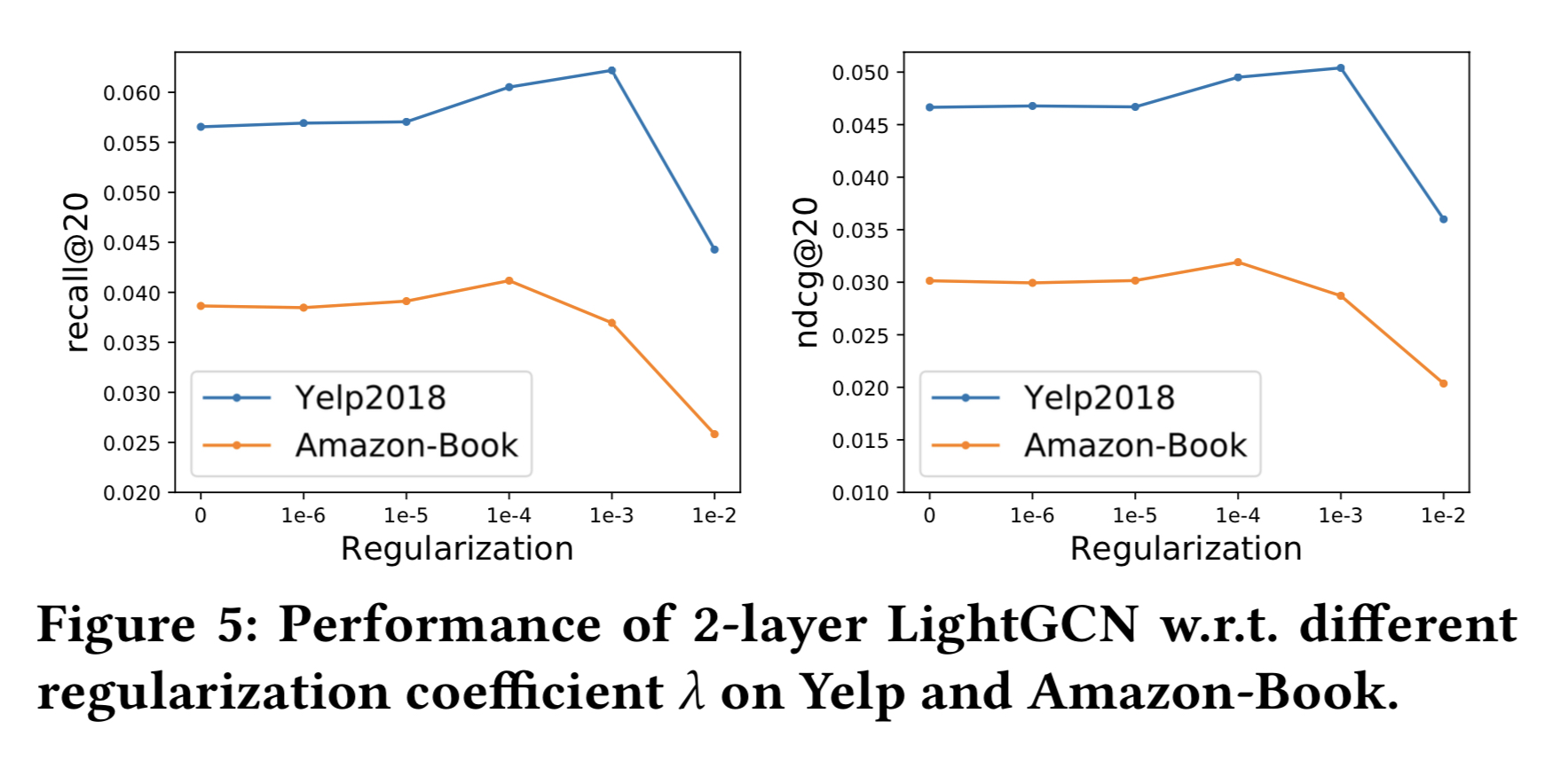
LightGCN은 상대적으로 $\lambda$에 insensitive하다. — $\lambda$가 0이어도, NGCF 보다 성능이 좋다. 이를 보면, LightGCN은 오버피팅으로 인한 프루닝이 필요없다. 학습 가능한 파라미터가 0번째 레이어의 임베딩이 유일해 전체 모델의 학습과 정규화가 쉽기 때문이다.
6 CONCLUSION AND FUTURE WORK
본 논문은 GCN이 CF에서는 불필요할정도로 복잡하다고 주장했고, 실험을 통해 주장을 정당화 했다.
LightGCN을 제안했는데, light graph convolution과 layer combination의 두 필수 컴포넌트로 구성된 모델이다.
- light graph convolution에서 피처 변환과 비선형 활성화를 제거했다. 학습 난이도를 올리기 때문이다.
- layer combination에서 모든 레이어에서 나온 임베딩 들의 가중합으로 최종 임베딩을 생성했다. 셀프 커넥션이 포함됨을 증명했고 오버 스무딩을 제어하는데 도움 되는 것을 증명했다.
실험으로 학습이 쉽고, 일반화가 좋고, 효과적이라는 LightGCN의 강점을 증명했다.
LightGCN은 미래의 추천 모델 개발에 영감을 줄 거라고 한다. 실제 APP의 연결된 그래프 데이터의 prevalence로, 그래프 기반 모델들이 추천에서 굉장히 중요해졌다. 예측 모델에서 명시적으로 엔티티 들 간의 관계를 활용함으로써, 기존의 암시적으로 관계를 모델링 하던 MF에 비해 강점이 있다.
예를 들어 ) 최근 트렌드는 아이템 지식 그래프, 소셜 네트워크, 멀티미디어 컨텐츠 같은 보조 정보를 추천에 활용하는 것이고, GCN이 새로운 SOTA가 되었다.
추후 방향은 레이어 조합 가중치 $\alpha_k$를 개인화 하는 것으로, 유저 들마다 스무딩을 적응형으로 하겠다. ( 희소한 유저는 고차 이웃의 신호를 더 많이 필요로 할 수도 있다. ) 그리고 LightGCN을 더 단순하게 해서, 온라인 환경에서 스트리밍 가능하도록 연구할 것이다.