A Contextual-Bandit Algorithm for Mobile Context-Aware Recommender System 논문 리뷰
Abastract
모바일 맥락 기반 추천 시스템의 대부분의 접근 방법은 맥락 정보를 활용해서 유저와 관련성 있는 아이템을 추천하는데 초점이 맞춰져 있다. 고려할만한 맥락 정보로 아래 세가지가 있다.
- 시간
- 위치
- 소셜 정보
이전의 연구들은 모두 유저의 컨텐츠 변화 문제를 고려하지 않는데 이 논문은 컨텐츠에 대해 변화하는
- 유저의 흥미를 다이나믹하게 처리하는 알고리즘을 제시
- 유저 상황에 따라 Exploration과 Exploitation을 결정한 뒤 적응형으로 EE 트레이드 오프
직접 설계한 오프라인 시뮬레이션 프레임워크로 실제 온라인 로그 데이터에서 검증을 수행한다.
1 Introduction
모바일 기술은 언제 어디서든 거대한 정보 컬렉션에 접근하게 만들었다. 특히, 거의 모든 모바일 유저는 그들의 리포지토리에서 거대한 규모의 컨텐츠를 획득하거나 유지한다. 리포지토리의 컨텐츠는 계속 변화하고 빈번하게 추가되고 제거된다.
→ 추천 시스템은 새로운 문서의 중요도를 빠르게 식별할 필요가 있고, 오래된 문서의 가치를 감쇄 시켜야한다.
이런 환경에서 유저에게 흥미로운 컨텐츠를 식별하는 것은 중요하다. 이 문제는 최근 Mobile Context-Aware Recommender Systems(MCRS) 연구 영역에서 해결하고 있다. 그러나 대부분의 연구 방향은 유저의 계산된 행동이나 그들의 주변 환경에 초점이 맞춰져 있고 컨텐츠에 대한 유저의 흥미 변화는 다루지 않는다.
→ 밴딧 알고리즘은 이 문제를 해결하기 위한 잘 알려진 솔루션이지만, exr/exp 트레이드 오프를 해결해야하는 문제가 있다.
$Bandit$
밴딧 알고리즘의 B는 과거 경험을 exploit 해서 문서를 선택해서 더 자주 나오게 한다. 선택한 최적 문서는 B의 지식이 부정확해서 사실 차선의 선택일 수도 있다. 이를 회피하기 위해, B는 차선책 처럼 보이는 문서를 Exploration 해서 문서에 대한 정보를 더 수집해야한다. exp는 일부 차선의 문서가 선택될 수 있기 때문에 단기적으로 유저의 만족도를 떨어트린다. 하지만, 문서의 평균 보상에 대한 정보를 얻는 것(exr)이 B가 하는 문서의 예측 보상을 재정의하고 장기적으로 사용자의 만족도를 높힌다. exp만 하는 그리고 exr만 하는 알고리즘 둘 다 잘 동작하지 않기 때문에 트레이드 오프를 잘해야 한하다. 기존 MAB 솔루션으로 $\epsilon-greedy$ 전략이 있다.
$\epsilon-greedy$
- $1-\epsilon$의 확률로, 현재 지식을 기반으로 최고의 문서를 선택한다.
- $\epsilon$의 확률로 다른 문서들을 유니폼하게 선택한다.
파라미터 $\epsilon$를 사용해서 EE 트레이드 오프를 컨트롤한다. 이 알고리즘의 단점으로 최적 값을 결정하기 어렵다는 문제가 있다. 그래서 이 논문에서는 유저의 상황에 따라 exp/exr 트레이드 오프를 적응형으로 해결하는
$Contextual-\epsilon-greedy$ 라고 부르는 알고리즘을 소개한다. 이 알고리즘은 $\epsilon-greedy$를 변형하는데exp/exr을 위한 적합한 유저 상황을 선택해서 exr/exp 트레이드 오프를 업데이트한다.
논문의 남은 구성은 다음과 같다.
- 섹션 2는 이 논문 전체에 사용된 핵심 개념을 제공한다.
- 섹션 3은 관련 연구를 리뷰한다.
- 섹션 4는 MCRS 모델을 제시하고 제안된 방법에 알고리즘을 설명한다.
- 섹션 5에서 실험 결과를 설명한다.
- 마지막 섹션에서는 논문을 마무리하고 향후 연구에 대한 방향을 설명한다.
2 Key Notions
이 섹션에서는 이 논문에서 사용하는 핵심 개념을 설명한다.
The users’model :
모델은 케이스 기반으로 구성되며, $U={{(S^i;UP^i)}}$로 표시되는 해당하는 유저의 선호도가 있는 상황으로 구성된 케이스 셋이다. 여기서 $S^i$는 유저의 상황이고 $UP^i$는 해당하는 유저의 선호도이다.
The user’s preferences :
유저 선호도는 유저의 탐색 활동으로 추론된다. 예를 들어 방문한 문서들의 클릭 수나 문서에 소요된 시간이다. UP은 주어진 상황에서 시스템의 특정 유저가 제출한 선호도이다. 각 문서의 UP은 단일 벡터 $d=(c_1,…,c_n)$로 표현된다. $c_i(i=1,…,n)$는 $d$의 선호도를 특정하는 구성요소의 값이다. 다음의 구성요소를 고려한다 : $d$에 대한 총 클릭수, $d$를 소비하는데 소요된 시간 그리고 $d$가 추천된 총 횟수.
Context :
유저 컨텍스트 $C$는 각 온톨로지가 컨텍스트 차원 $C=(O_{Location}, O_{Time}, O_{Social})$에 해당하는 다중-온톨로지 표현이다. 각 차원은 컨텍스트 정보 타입을 모델링하고 관리한다. 모든 필요한 정보를 다루기 때문에 이 세 가지 차원에 중점을 둔다. 온톨리지들은 [1]에 설명되어 있다.
Situation :
상황은 유저 컨텍스트를 하나의 인스턴스로 만든 것이다. 상황을 $triple \ S = (O_{Location}\dot x_i, O_{Time} \dot x_j, O_{Social} \dot x_k )$로 구성하는데 여기의 $x_i$, $x_j$와 $x_k$는 온톨로지나 인스턴스이다. 유저의 핸드폰에서 다음의 데이터가 센싱되었다고 가정한다:
- Location(GPS) : “48.89”, “2.23” ( 위도 경도 )
- Time(로컬) : “Oct_3_12:10_2012”
- Social(달력) : “meeting with Paul Gerad”
→ 해당 상황은 S=(“48.89,2.23”,“Oct_3_12:10_2012”,“Paul_Gerad”)이다.
미리 생성된 온톨로지 추론으로 저수준 다중 모드 센서 데이터에서 유저 행동을 해석한다. 예를 들어, S로 부터 아래와 같은 상황을 얻는다
→ Meeting=(Restaurant, Work_day, Financial_client)
획득한 상황 셋 중에서 일부는 높은 수준의 위기 상황으로 특징된다.
High-Level Critical Situations (HLCS) :
HLCS는 전문적인 미팅에서 유저가 시스템에서 추천할 수 있는 최상의 정보를 필요로 하는 상황 클래스이다. 이 상황에서 시스템은 exr 지향 학습 보다는 exp 만 수행해야한다. 다른 경우에는 예를 들어 사용자가 집에서 그들의 정보를 사용하는 경우, 친구와의 휴가의 경우에는 시스템이 그들의 관심을 무시하고 일부 정보를 추천하여 exr을 할 수 있다. HLCS는 도메인 전문가가 미리 정한다. 전문적인 모바일 유저를 대상으로 연구를 수행하며 이에 대해서는 섹션 5에 자세히 설명되어 있다. HLCS의 예제로 아래 두가지가 있다.
- $S1=(restaurant, midday, client)$
- $S2=(company, morning, manager)$
3 Related Work
이 섹션에서는 다이나믹 exr/exp(밴딧 알고리즘)를 만드는 문제를 다루는 최근 추천 기술을 다룬다. 추천에서 유저의 상황을 다루는 기존 연구는 이 섹션에서는 다루지 않는다. 자세한 내용은 [1]을 참조하자.
$\epsilon-greedy$
강화학습에서 exr/exp 트레이드 오프를 연구를 많이 하는데 , MAB는 Robbins[11]에 의해 제시되었다. $\epsilon-greedy$는 밴딧 문제를 해결하는데 가장 많이 사용되는 전략이고 [10]에서 처음으로 설명되었다. $\epsilon-greedy$ 는 입실론 빈도수 ($\epsilon$)로 랜덤하게 문서를 선택하고, 그렇지 않으면, 가장 높은 추정 평균을 가진 문서를 선택한다. 추정은 지금까지 관측된 보상을 기반으로 한다. $\epsilon$은 [0, 1] 구간 내이고 선택은 유저가 한다.
$\epsilon-beginning$
$\epsilon-greedy$ 전략은 첫번째 변형으로 $\epsilon-beginning$ 전략이라고 한다.[6,10] 이 전략은 초기에 모두 한번 exr을 한다. 주어진 반복 횟수 $I$에 대해 문서들은 첫 $\epsilon I$번 반복 동안 랜덤하게 추출된다. 남은 $(1-\epsilon)I$ 반복 동안, 가장 높은 추천 평균을 가진 문서가 추출된다.
$\epsilon-decreasing$
$\epsilon-greedy$ 의 다른 변형은 $\epsilon-decreasing$라고 한다.[10] 이 전략에서는 $\epsilon_i$로 랜덤하게 문서가 추출 되는 것을 제외하고는 가장 높은 추천 평균을 가지는 문서가 추출된다. 여기서 $\epsilon_i = {{ \epsilon_0 / i }}$, $\epsilon \in [0,1]$ 그리고 i는 현재 라운드이다. $\epsilon-decreasing$ 외에 네가지 다른 전략이 제시 되었다.[3] 그러한 전략은 여기서 설명하지는 않지만 [3]의 실험은 $\epsilon-decreasing$이 다른 전략 만큼 좋다는 것을 보였다. 고정된 액션 셋을 표준 MAB 문제와 비교하면 MCRS에서는 오래된 문서가 만료되고 새 문서가 자주 나타날 수 있다. 그래서 [6]과 같이 처음에 exr을 한번에 모두 수행하거나 [10]의 감소 전략으로 exr을 단조롭게 줄이는 것은 적절하지 않을 수 있다.
Exponentiated Gradient(EG)
MCRS에서 exr/exp 트레이드 오프를 다루는 연구는 없다. 소수의 연구만 추천 시스템에서 유저의 행동을 컨텍스트로 간주하는 컨텍스튜얼 밴딧 문제를 연구하는데 전념한다. [13]에서 저자는 $\epsilon-greedy$ 전략을 확장해서 $\epsilon$ exr 값을 다이나믹하게 업데이트한다. 각 반복에서, 샘플링을 수행해서 한정된 후보 셋에서 $\epsilon$을 선택한다. 후보와 연관된 확률은 유니폼하게 초기화되고 Exponentiated Gradient(EG)로 업데이트된다.[7] 이 업데이트 규칙은 유저의 클릭으로 이어질 때 후보 $\epsilon$의 확률을 증가시킨다. $\epsilon-beginning$과 $\epsilon-decreasing$ 모두와 비교하면, 이 기술이 더 좋은 결과를 준다. [9]에서 저자는 컨텍스튜얼 밴딧 문제로 추천을 모델링한다. 사용자 행동을 기반으로 유저에게 제공할 문서를 순차적으로 선택하는 접근 방식을 제안한다. 유저의 총 클릭 수 최대화를 위해, 이 연구는 계산적으로 효율적인 LINUCB 알고리즘을 제안한다.
위에서 봤듯이, 어떤 연구도 exr/exp 전략에서 exr/exp의 역동성과 유저의 상황을 다루지 않는다. 이것이 바로 우리의 접근 방식으로 하려는 것이다. 직관적으로 보면 exr/exp 트레이드 오프를 관리할 때 상황의 중요성을 추가로 고려하면 MCRS의 결과를 향상시킨다. 논문의 방법은 현재 유저의 상황이 중요하지 않을 때 exr을 하고 반대의 경우에는 exp를 한다.
4 MCRS Model
추천 시스템에서, 문서 추천은 유저의 상황 정보를 포함한 컨택스튜얼 밴딧 문제로 모델링 된다.[8] 공식적으로, 밴딧 알고리즘은 구분된 시도 $t=1,…,T$로 진행된다. 각 시도 $t$에서 알고리즘은 다음 태스크를 수행한다.
Task 1 :
시스템은 $S^t$를 $PS$ 내 상황과 비교해서 가장 유사한 상황을 선택한다, $S^p$:
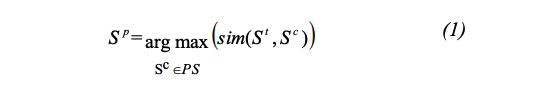
Equation 1
- $S^t$ : 현재 유저의 상황
- $PS$ : 과거 상황 셋
의미론적 유사도 메트릭은 다음으로 계산된다.
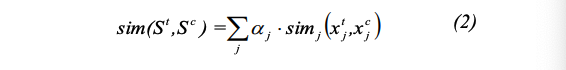
Equation 2
식 2에서 $sim_j$는 유사도 메트릭으로 두가지 컨셉 $x_j^t$와 $x_j^c$ 사이의 차원 $j$와 관련이 있다.
- $\alpha_j$ : 차원 j와 연관된 가중치(실험 단계에서는 $\alpha_j$는 모든 차원이 1)
이 유사도는 $x_j^t$와 $x_j^c$가 해당 온톨로지에서 얼마나 밀접하게 관련되어 있는지와 관련된다. [15]에서 정의한 유사도 측정 방법과 같은 방법을 사용한다.
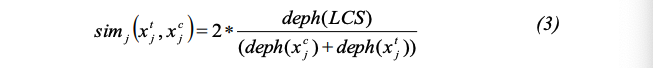
Equation 3
- $LCS$ : $x_j^t$와 $x_j^c$의 $Least \ Common \ Subsumer$
- $deph$ : 노드에서 온톨로지 루트 까지의 경로에 있는 노드 수
Task 2 :
$S^p$를 검색한 후에, 시스템은 각 문서 $d_p \in D_p$를 읽을 때의 유저 행동을 관측한다. 관측된 보상을 기반으로, 알고리즘은 더 큰 보상 $r_p$를 가지는 문서 $d_p$를 선택한다.
- $D$ : 문서 컬렉션
- $D_p \in D$ : 상황 $S^p$에서 추천된 문서 셋
Task 3 :
유저의 보상을 받은 후, 알고리즘은 자체 문서 선택 전략을 새로운 관측 값으로 개선한다 : 상황 $S^t$에서 문서 $d_p$는 보상 $r_t$를 획득한다.
유저에게 문서가 표시되고 이 문서가 클릭으로 선택될 때, 보상 1이 발생한다: 그렇지 않으면 보상은 0이다. 문서의 보상은 정확히 CTR이다. CTR은 추천에 의한 문서의 평균 클릭 수이다.
4.1 The $\epsilon-greedy$ algorithm
$\epsilon-greedy$ 알고리즘은 다음의 식으로 미리 선언된 문서의 수 N만큼 선택된 문서를 추천한다.
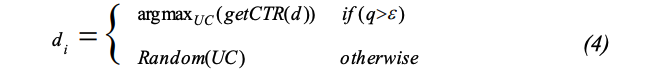
Equation 4
식 4에서, $i \in {{1,…,N}}, UC={{d_1,…,d_p}}$는 문서 셋으로 유저의 선호도에 해당한다;
- $getCTR()$ : 주어진 문서의 CTR을 계산
- $Random()$ : 주어진 셋에서 랜덤 엘리먼트를 반환하고 exr을 수행
- q : [0,1]에서 유니폼하게 분포하는 값( exr/exp 트레이드 오프를 정의한다 )
- $\epsilon$ : 랜덤 exr 문서를 추천할 확률
4.2 The $contextual-\epsilon-greedy$ algorithm
HLCS 상황에서의 $\epsilon-greedy$ 알고리즘의 적응도를 개선하기 위해, $contextual-\epsilon-greedy$ 알고리즘은 현재 유저의 상황 $S^t$를 HLCS 상황 클래스와 비교한다. $S^t$와 그것과 가장 유사한 상황 $S^m \in HLCS$의 유사도에 의존하는데 B를 유사도 임계치(이 메트릭은 아래에 논의됨)로 하면 두가지 시나리오가 가능하다.
(1) $sim(S^t, S^m) ≥ B$인 경우,
현재 상황은 크리티컬하다; $\epsilon-greedy$ 알고리즘은 $\epsilon=0$(exploitation)으로 사용되고 $S^t$는 HLCS 상황 클래스에 추가된다.
(2) $sim(S^t, S^m) ≤ B$인 경우,
현재 상황은 크리티컬하지 않다; $\epsilon-greedy$ 알고리즘은 $\epsilon > 0$(exploration)으로 사용되고 식 5로 계산된다.
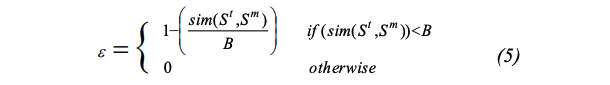
Equation 5
요악하면, 현재 유저의 상황이 크리티컬하면 exp만 수행하고 그렇지 않으면 exr을 수행한다. $S^t$와 $S^m$의 유사도가 증가하면 exr은 감소한다.
5 Experimental Evaluation
우리의 접근 방법의 성능을 경험적으로 검증하기 위해, 그리고 표준 검증 프레임워크가 없는 경우, 연구 항목의 일일 셋을 기반으로 검증 프레임워크를 제시한다. 실험 검증의 주요 목적은
(1) 섹션 4.2에 묘사된 최적 임계치 B를 찾는다
(2) 제안된 알고리즘 ($contextual-\epsilon-greedy$)의 성능을 검증한다
실험 데이터셋을 설명하고 획득 결과를 표시하고 논의한다.
프랑스 소프트웨어 회사 Nomalys와의 협력으로 다이어리 연구를 수행한다. 이 회사는 어플리케이션 히스토리를 제공하는데, 이 히스토리는 사용자의 시간, 현재 위치, 소셜 및 탐색 정보를 저장한다.
일일 연구
- 18 달이 소요
- 178,369 일일 상황(문맥적 시간, 위치 그리고 소셜 정보 캡처)
각 항목에서, 캡처된 데이터는 시간, 공간 그리고 소셜 온톨로지를 사용한 더 추상화된 정보로 교체된다.[1] 일일 연구로 부터,
- 총 2,759,283 항목
- 평균 15.47개의 상황
임계 유사도 값을 설정하기 위해서, 베이스라인으로 수동 분류를 사용하고 우리의 기술로 얻은 결과와 비교한다. 상황 항목 10%를 랜덤하게 샘플링하고, 수동으로 유사 상황으로 그룹화한다; 그리고 생성된 그룹과 다른 유사도 알고리즘과 다른 임계치를 사용한 결과와 비교한다.
그림 1은 상황 유사도 임계치 파라미터 $B$를 [0,3] 구간으로 다양하게 했을 때 효과를 precision으로 보인다. 결과는 B가 2.4일 때 precision 0.849로 최고 성능임을 나타낸다. 결과적으로 최적 임계치 $B=2.4$를 MCRS를 테스트하기 위해 사용한다.
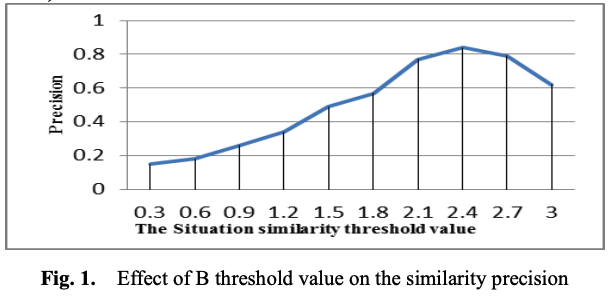
Figure 1
$contextual-\epsilon-greedy$ 알고리즘 성능 테스트
- 100번 이상 발생한 3000개의 상황을 먼저 수집(통계적으로 유의미함 )
- 이러한 상황들에서 보여진 10,000개의 문서를 샘플링
- 테스팅 상황에 대한 알고리즘을 검증 ( 평균 CTR ; 총 클릭 수와 총 디스플레이 수 간 비율)
- 매 1,000회 반복마다 평균 CTR을 계산한다.
- 모든 알고리즘이 수렴되는 반복 횟수가 10,000회에 도달할 때까지 시뮬레이션을 수행
각 상황에 대해 추천 시스템이 반환하는 문서 수(N)은 10이다. 첫번째 실험에서, 순수한 exp 베이스라인에 더해서, 관련 연구(섹션 3)에서 설명된 알고리즘과 우리의 알고리즘을 비교한다:
- $\epsilon-greedy$;
- $\epsilon-beginning$
- $\epsilon-decreasing$
- $Exponentiated-Gradient \ (EG)$
그림 2에서 x축은 반복 횟수이고 y축은 성능 메트릭이다.
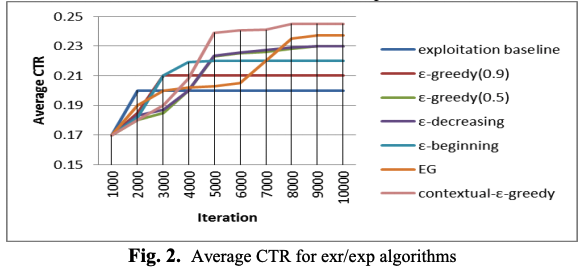
Figure 2
우리는 다음과 같이 다른 알고리즘을 파라미터화 했다. 두 파라미터 값으로 $\epsilon-greedy$를 테스트 했다;
- $\epsilon = 0.5, 0.9$
- $\epsilon-decreasing$과 $EG$는 동일한 셋 ${{ \epsilon_i = 1-0.01*i, i=1,…,100}}$을 사용
- $\epsilon-decreasing$은 가장 높은 값을 사용
- 매 100회 반복마다 가장 작은 값에 도달할 때까지 0.01씩 감소했다.
전체 테스트 알고리즘들은 베이스라인에 비해서 더 좋은 성능을 가진다. 그러나 첫번째 2,000회 반복에서 순수 exr으로 exp 베이스라인은 더 빠르게 수렴한다. 그러나 장기적으로, 모든 exr/exp 알고리즘은 수렴되면 평균 CTR이 개선된다.
다른 exr/exp 알고리즘에 대한 몇가지 관찰한 것이 있다.
- $\epsilon-decreasing$ 알고리즘에서, $\epsilon$(exp 인자)이 감소할수록 수렴된 평균 CTR이 증가
- $\epsilon-greedy$(0.9)와 $\epsilon-greedy$(0.5)에서는 수렴후에도 알고리즘은 여전히 평균 CTR이 낮은 문서에 각각 90%와 50%의 기회를 제공하므로 결과가 크게 감소
- EG 알고리즘이 더 높은 평균 CTR로 수렴하는 동안, 전체 성능은 $\epsilon-decreasing$ 만큼은 좋지 않다. 더 많은 exr로 초기 스텝에서 평균 CTR이 낮지만, 더 빠르게 수렴하지는 않음
- $contextual-\epsilon-greedy$ 알고리즘은 효과적으로 최적 $\epsilon$을 학습 수렴율이 가장 높고 평균 CTR이 베이스라인에 비해 두배 증가하며 다른 exr/exp 알고리즘 보다 성능이 더 뛰어나다. ( 이러한 성능 개선은 크리티컬한 상황(HLCS) 예측에 의해 컨트롤되는 exr/exp 간 다이나믹 트레이드 오프로 부터 발생한다. 초기에 이 알고리즘은 좋은 결과를 얻을 기회를 낭비하지 않고 exr을 최대한 활용한다. )
6 Conclusion
이 논문에서는 모바일 맥락 기반 추천 시스템의 exploitation과 exploration의 문제를 연구하고 적응적으로 exr/exp를 유저의 상황에 대해서 균형을 맞추는 새로운 접근 방식을 제안한다. 제안된 알고리즘의 성능을 검증하기 위해서, 다른 표준 exr/exp 전략을 비교한다. 실험 결과는 우리의 알고리즘이 다양한 구성에서 평균 CTR이 더 좋다는 것을 증명한다. 추후에는 모바일 디바이스 상에서의 알고리즘의 확장성을 검증하고 다른 공공 벤치마크에서 조사할 계획이 있다.