단단한 강화 학습 2장 다중 선택 ~ 2.5 정리
Bandit Problem은 오직 하나의 상태만 다루는 강화학습 문제이다.
강화 학습은 지도 학습과는 다른 종류의 학습 피드백을 전달한다. 학습자의 행동과 무관하게 정해져 있는 정답이 있는 지도 학습과는 다르게, 강화 학습은 행동에 대한 결과를 피드백으로 전달한다. 그렇기 때문에 좋은 행동을 찾기 위한 직접적인 탐색이 필요하다.
단순화 된 구조에서 하나의 상황에 대해서만 행동을 학습하게 되는 구조를
Non-Associative 구조라고 한다.
- 하나 이상의 situation을 다루지 않음.
- Evaluative Feedback에 관한 작업이 이미 수행 된다.
이러한 구조를 가지는 특별한 구조로서 다중 선택 문제(Multi-Armed Bandits)가 있다.
Multi-Armed Bandits
K-Armed Bandit Problem(다중 선택 문제)는 슬롯 머신과 유사하기 때문에 붙여졌는데
- k개의 서로 다른 옵션이나 행동 중 하나를 계속해서 선택해야 하고
- 선택 후에는 수치화된 보상이 주어진다.
- 선택의 목적은 반복적인 선택을 통한 누적 보상을 최대로 만드는 것이다.
k개의 행동 각각에는 선택 되었을 때 기대 평균 보상 값이 있다. 평균 보상 값을 가치(Value)라고 하자.
임의의 행동 a의 기대 평균 보상(가치)인 $q_*(a)$는 아래의 식으로 표현할 수 있다.
$q_*(a) \dot{=} E[R_t | A_t = a]$
- $A_t$ : 시간 t에서 선택 되는 행동 ( Action )
- $R_t$ : 시간 t에서 행동에 따른 보상 ( Reward )
각 행동에 대한 가치의 확실하지 않다는 전제를 가진다. 시간 t에서 추정한 행동 a의 가치를 $Q_t(a)$로 표현하는데, 추정값 $Q_t(a)$가 기댓값 $q_*(a)$와 가까워질수록 정확한 추정이 된다.
행동에 대한 가치를 시간에 따라 추정하면 각 시간마다 가치가 최대인 행동을 하나 이상 선택할 수 있는데 이러한 방법을 탐욕적 행동(Greedy action)이라고 한다.
Greedy Action
이 방법은 최대의 가치를 가지는 행동을 선택하는 방법이다. 탐욕적 행동을 선택하는 것은 현재 까지 가지고 있는 지식을 최대한 활용(Exploiting) 하는데
탐욕적 행동은 단기적으로는 좋을 수 있지만, 그리디 행동의 기반인 가치가 불확실하기 때문에 장기적으로 더 많은 선택을 해야한다면 좋지 않을 수 있다.
비-탐욕적 행동을 하는 것을 탐험(Exploring)이라고 하는데 탐험으로 비-탐욕적 행동의 추정 가치를 상승 시킬 수 있다. 탐험으로 더 높은 가치를 가지는 행동을 찾아내고 그 행동을 더 많이 선택함으로써 누적된 보상의 총합을 상승 시킬 수 있기 때문에 장기적으로는 더 큰 보상을 얻을 수 있다. 하지만 행동을 선택할 때 한번에 활용과 탐색을 할 수는 없기 때문에 균형을 맞춰야 한다.
Exploiting과 Exploring을 결정하는 것은 복잡한 방법으로 결정 된다.
- Action에 대한 정밀한 가치 추정값.
- 가치 추정값의 불확실성.
- 앞으로 남아 있는 단계의 수.
행동 가치 방법 ( Action-Value Method )
행동의 가치를 추정하고 추정값으로 부터 행동을 선택하는 결정하는 방법
행동이 가지는 가치는 행동이 선택될 때 받을 수 있는 보상의 평균이다. 평균 보상을 추정하는 방법은 최선의 방식은 아니지만 직관적으로 실제로 받은 보상의 산술평균을 계산함으로 추정 할 수 있다. 이 방법을 표본 평균법(sample-average)이라고 하고 아래의 식으로 표현할 수 있다.
$Q_t(a) \dot{=} \frac{시각 \ t \ 이전에 \ 취해지는 \ 행동 \ a에 \ 대한 \ 보상의 \ 총합}{시각 \ t \ 이전에 \ 행동 \ a를 \ 취하는 \ 횟수 } = \frac{\sum_{i=1}^{t-1} R_o \cdot \mathsf{1}_{A_i=a}}{\sum_{i=1}^{t-1} R_o \cdot \mathsf{1}_{A_i=a}}$
- $\mathsf{1}_{조건 서술어}$는 ‘조건 서술어’가 참이면 1 아니면 0을 가지는 확률 변수를 나타낸다.
- 분모가 0이 되는 경우에는 $Q_t(a)$도 0으로 정의한다.
분모가 무한으로 커지는 경우에는 큰 모집단에서 무작위로 뽑은 표본의 평균이 전체 모집단의 평균과 가까울 가능성이 높다는 기본 개념인 큰수의 법칙에 따라 $Q_t(a)$는 $q_*(a)$로 접근한다.
이렇게 추정한 가치로 행동을 선택하는 가장 간단한 규칙으로 그리디(Greedy) 행동 선택 방법이 있다. 가치가 최대인 행동 중 하나를 선택하는 것이다. 여러개가 있다면 무작위로 그중 하나를 선택할 수 있다. 아래와 같이 표현할 수 있다.
$A_t \doteq \underset{a}{arg \ max} \ Q_t(a)$
탐욕적 행동 선택 방법을 대체할 만한 단순한 대안은 대부분은 탐욕적 선택을 유지하고 가끔씩 모든 행동을 대상으로 무작위 선택을 하는 입실론 그리디($\epsilon-greedy$) 방법이 있다.
$\epsilon-greedy$ 방법
상대적 빈도수 $\epsilon$을 작은 값으로 유지하면서 탐욕적 선택 대신 행동의 추정 가치와는 무관하게 모든 행동을 균등한 확률로 선택하는 방법이다. 장점은 이후 단계 수가 무한으로 커지면 모든 행동을 선택하는 횟수도 무한이 되어 모든 $Q_t(a)$가 $q_*(a)$로 수렴한다는 것이다.
10중 선택 테스트 ( 10-Armed TestBed )
그리디 행동 가치 방법과 입실론 그리디 행동 가치 방법이 상대적으로 얼마나 효과적인지 평가하기 위해 테스트로 두 방법을 수치로 비교한다. 탐욕적 방법과 두 개의 입실론 탐욕적 방법 ($\epsilon=0.01, 0.1$)을 비교한다.
테스트 환경
- 열 번의 선택을 하는 다중 선택 문제 2000개를 랜덤하게 생성한다.
- 각 행동의 가치 $q_*(a)$는 평균이 0이고 분산이 1인 정규 분포(gaussian) 분포에 따라 선택된다.
- 각 학습 방법 별 1000 스텝을 수행한다.
- 실행을 2000번 독립적으로 수행하면서 학습 알고리즘의 평균 결과를 측정할 수 있다.
음영으로 표시되는 분포는 아래 그림과 같다.
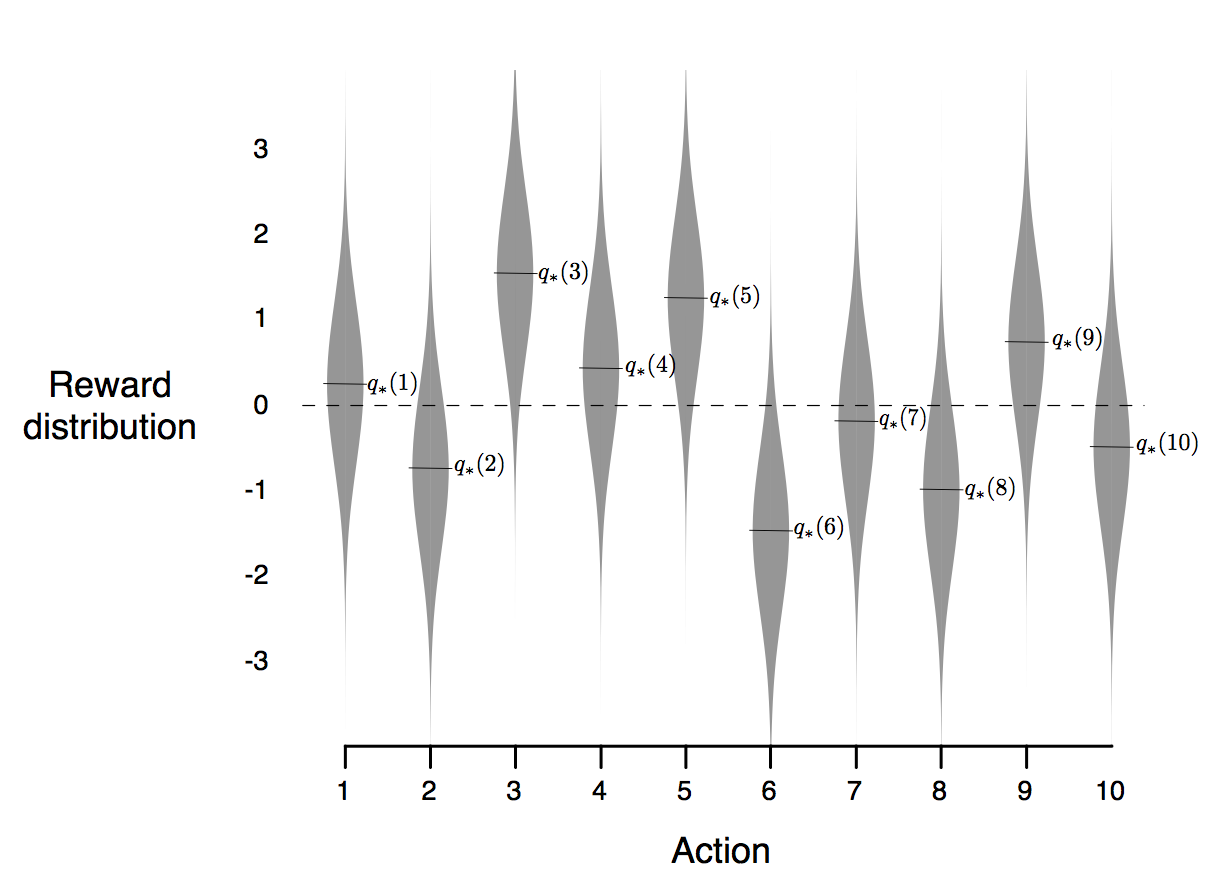
Figure 1
Average reward
탐욕적 방법은 시작 직후에는 다른 방법에 비해 조금 더 빠르게 향상되지만, 결국에는 성능이 떨어진다. 가장 좋을 것으로 기대되는 $q_*(3)$ 보상은 1.55 인 것에 비해 탐욕적 방법의 단계당 보상은 1 정도이다.
Optimal action
그리고 탐욕적 방법은 약 30% 정도의 문제에서 최적의 행동을 찾는 것으로 보인다. 입실론 그리디 방법은 탐험을 계속 했기 때문에 최적 행동을 찾을 확률이 계속해서 증가했다. 결국에 더 좋은 성능을 보였다.
$\epsilon = 0.1$인 경우 더 많이 탐험 했고 더 빨리 최적 행동을 찾았지만 최적 행동을 선택한 시간 단계는 91%에 미치지 못한다. 91%를 해석하자면 여기에서 1%는 10개의 행동 중 하나가 최적의 행동이기 때문이다.
$\epsilon = 0.01$의 경우, 최적 행동을 찾는 것은 더 느리지만 결국에는 $\epsilon = 0.1$에 비해 두 그래프 모두에 좋은 결과를 보일 것이다. $\epsilon$을 시간에 따라 감소시켜 가면서 최상의 결과를 보이는 행동을 찾는 방법도 가능하다.
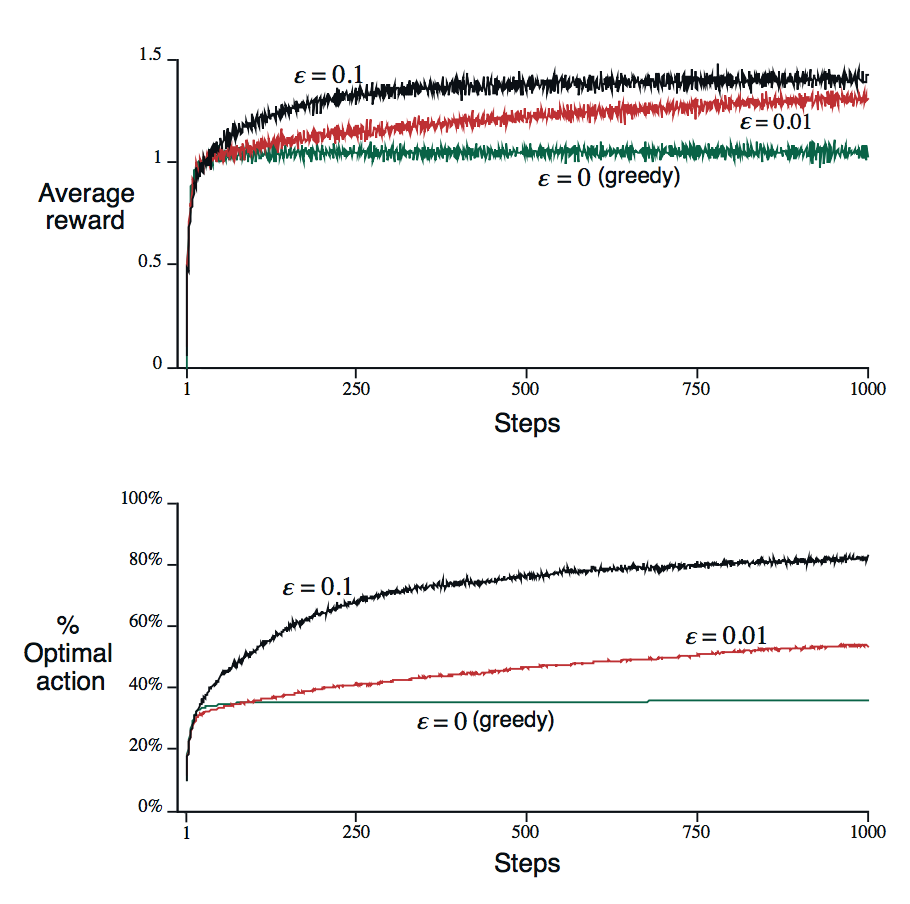
Figure 2
다중 선택 문제를 보상의 분포가 비정상적(non-stationary)이고, 행동 가치가 시간에 따라 변한다고 가정한다면, 비-탐욕적 행동이 탐욕적 행동에 비해 더 큰 가치를 가지지 않는지 확인해야하기 때문에 탐험이 중요 해진다.
2.4 Incremental Implementation
컴퓨터의 메모리와 시간 단계별 계산량이 제한된 경우에 수치 계산 측면에서 효율적으로 계산하는 방법이 있다. 수식을 간단하게 하기 위해 행동 하나만 고려한다. 행동이 i번째 선택된 후에 받는 보상을 $R_i$라고 했을 때, 행동이 n-1번 선택된 이후에 이 행동의 가치 추정값 $Q_n$은 아래의 식으로 표현할 수 있다.
$Q_n \doteq \frac{R_1 + R_2 + \cdot \cdot \cdot + R_{n-1}}{n-1}$
모든 보상을 기록하고 추정값이 필요할 때마다 식으로 계산하는 방식인데 보상이 커질수록 컴퓨터의 메모리와 계산 능력에 대한 수요가 증가한다. 보상이 하나 더 관측될 때마다 그 값을 저장할 메모리가 추가로 필요하고, 식의 분자에 있는 합계를 계산하기 위한 계산 능력이 추가로 필요하다. 하지만 이 과정이 사실은 일정한 계산 능력만을 이용하여 평균값을 갱신하는 점증적 공식으로 쉽게 만들 수 있다.
$Q_{n+1} = Q_n + \frac{1}{n}[ R_n - Q_n ]$
이 갱신 규칙은 아래와 같이 일반적으로 표현할 수 있다.
$새로운 \ 추정값 \ ← \ 이전 \ 추정값 \ + \ 시간 \ 간격의 \ 크기 [ 목푯값 - \ 이전 \ 추정값]$
- [목푯값 - 이전 추정값]은 추정 오차(error)를 나타낸다.
오차는 ‘목푯값’으로 한단계 접근할 때마다 감소한다. 사실 시간 간격의 크기는 시간 단계마다 다른데 시간 간격의 크기를 $\alpha$로 나타내거나 더 일반적으로는 $\alpha_t(a)$로 표현한다. 아래는 점증적으로 계산한 표본평균과 입실론 그리디 행동 선택을 이용한 완전한 다중 선택 알고리즘의 의사코드이다.

Figure 3
- $bandit(a)$ : 어떤 행동에 대한 보상을 계산하는 함수
2.5 Tracking a Nonstationary Problem
정상(stationary) 다중 선택 문제에서는 보상값의 확률 분포가 시간이 지나도 변하지 않기 때문에 평균값을 사용하는 것이 좋다. 하지만 실제에서는 비정상(non-stationary)하기 때문에 최근의 보상일 수록 더 큰 가중치를 줘야하고 오래된 보상일수록 더 낮은 가중치를 부여해야한다. 고정된 시간 간격을 이용해서 가중치를 부여하는 방법이 가장 많이 사용된다. 고정된 시간 간격을 이용해 보상의 가중치를 부여하는 방법으로 수정한 점증적 갱신 규칙은 아래와 같다.
$Q_{n+1} \doteq Q_n + \alpha[R_n - Q_n] = (1-\alpha)^nQ_1 +\sum\limits_{i=1}^n \alpha(1-\alpha)^{n-i}R_i$
- $\alpha \in (0, 1]$ : 시간 간격의 크기 ( 고정 )
- $Q_1$ : 초기 추정값
- $Q_{n+1}$ : 이 초기 추정값 $Q_1$과 과거 보상값들에 대한 가중치가 적용된 평균
- $R_i$ : 보상
보상 $R_i$에 주어진 가중치 $\alpha(1-\alpha)^{n-i}$는 보상이 관측되고 난 후 남아있는 보상의 갯수인 n-i에 따라 결정된다. $1-\alpha$는 1보다 작기 때문에 보상에 주어지는 가중치는 등장할 보상의 갯수가 증가함에 따라 감소된다. 기하급수적으로 감소하기 때문에 기하급수적 최신 가중 평균(exponential recency-weighted average)라고 부르기도 한다.
시간 간격의 크기를 시간 단계에 따라 변화 시키는 것이 편리할 때도 있는데 행동 a를 n번째 선택한 이후에 받은 보상을 처리하는 데 이용할 시간 간격의 크기를 $\alpha_n(a)$라고 하면, 표본 방법은 $\alpha_n(a) = \frac{1}{n}$이 될 때이다. 표본 방법은 큰 수의 법칙에 따라 행동 가치의 참값으로 수렴함을 보장한다. 하지만 모든 선택 가능한 시간 간격 크기 ${ \alpha_n(a) }$에 수렴성이 보장 되는 것은 아니다. 확률론적 근사 이론에 따르면 100% 확률로 수렴성을 보장하기 위한 조건은 아래와 같다.
- $\sum\limits_{n=1}^{\infty}\alpha_n(a) = \infty$ : 어떤 초기 조건이나 확률적 변동성도 극복할 만큼 충분히 큰 시간 간격을 보장한다.
- $\sum\limits_{n=1}^{\infty}\alpha_n^2(a) = \infty$ : 시간 간격이 감소해서 결국에는 수렴성을 확신할 만큼 충분히 작아진다.
표본 방법의 경우에는 두가지를 모두 만족하지만 고정된 시간 간격의 크기 $\alpha_n(a) = \alpha$를 적용하면 만족할 수 없다. 충분히 작아져야한다는 두번째 조건을 만족하지 못하는데, 이것은 추정값이 완전히 수렴하지 않고 가장 최근에 받은 보상에 반응하여 연속적으로 변한다는 것을 의미한다. 앞에서 언급한 것과 같이 실제 문제에서는 당연한 것이다. 그렇기 때문에 실제 문제에서는 적용이 거의 되지는 않는다.